 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Synthetic Speech Detection Using Frame- and Segment-Specific Importance Weighting
Paper and Code
Oct 10, 2016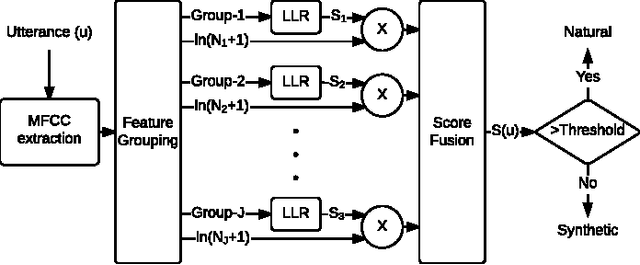
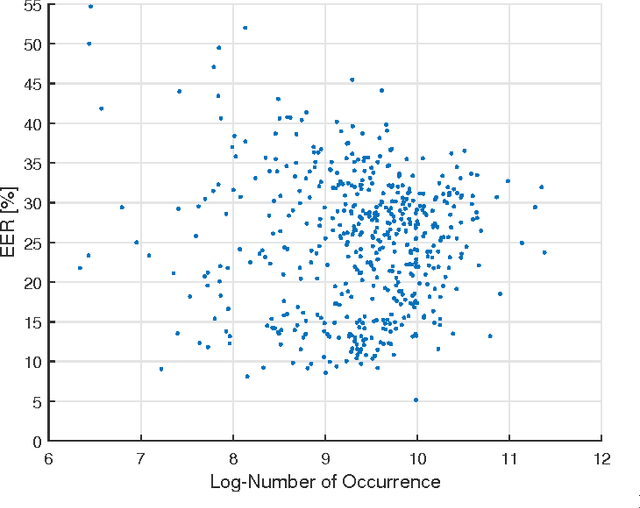
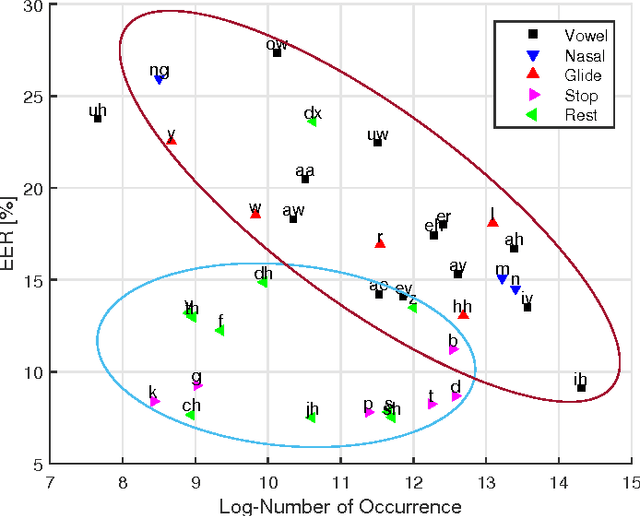
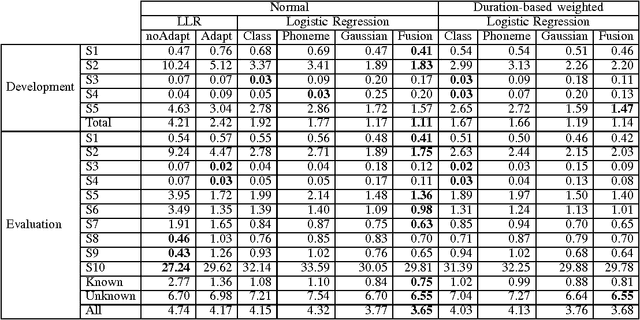
Speaker verification systems are vulnerable to spoofing attacks which presents a major problem in their real-life deployment. To date, most of the proposed synthetic speech detectors (SSDs) have weighted the importance of different segments of speech equally. However, different attack methods have different strengths and weaknesses and the traces that they leave may be short or long term acoustic artifacts. Moreover, those may occur for only particular phonemes or sounds. Here, we propose three algorithms that weigh likelihood-ratio scores of individual frames, phonemes, and sound-classes depending on their importance for the SSD. Significant improvement over the baseline system has been obtained for known attack methods that were used in training the SSDs. However, improvement with unknown attack types was not substantial. Thus, the type of distortions that were caused by the unknown systems were different and could not be captured better with the proposed SSD compared to the baseline SSD.