 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatiQ: An End-to-end Text-to-Speech System for Arabic
Jun 15, 2022
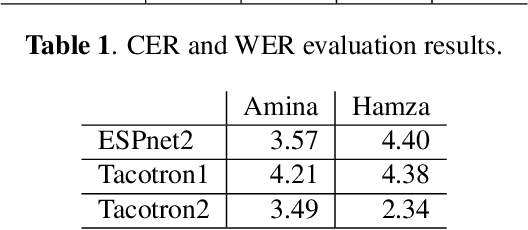
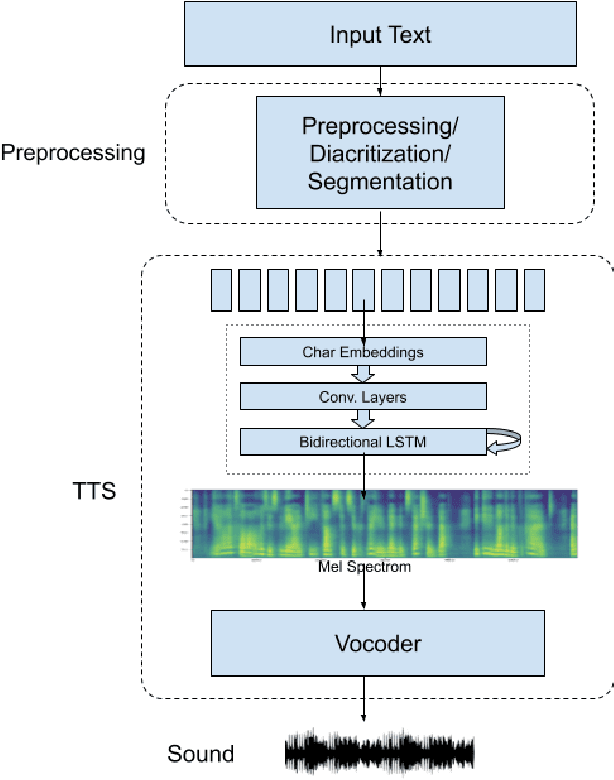
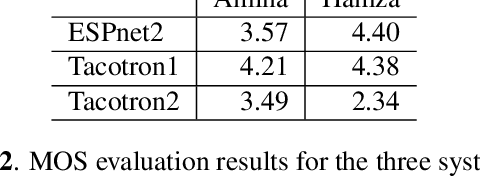
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron-1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neutral male "Hamza"- narrating general content and news, and 2) expressive female "Amina"- narrating children story books to train our models. Our best systems achieve an average Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real-time factor favored the end-to-end architecture ESPnet. NatiQ demo is available on-line at https://tts.qcri.org
Investigation of Synthetic Speech Detection Using Frame- and Segment-Specific Importance Weighting
Oct 10, 2016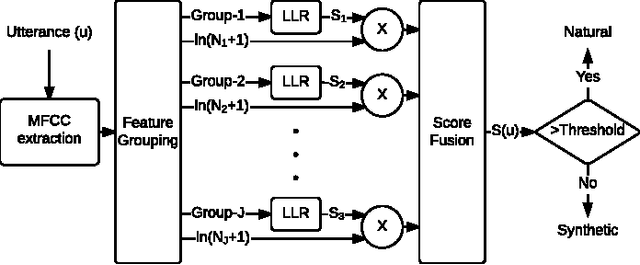
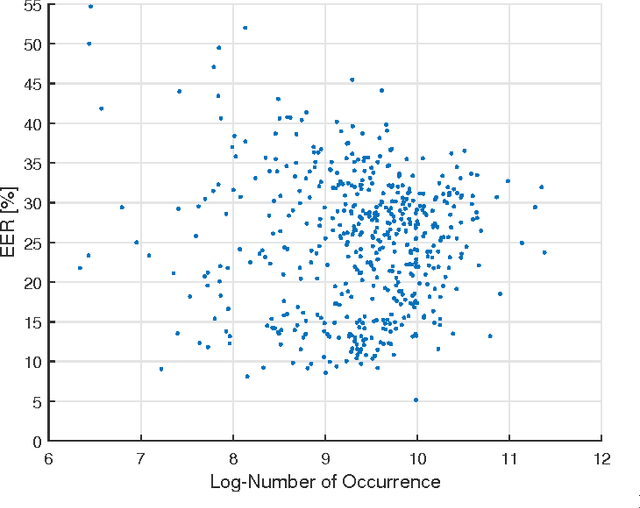
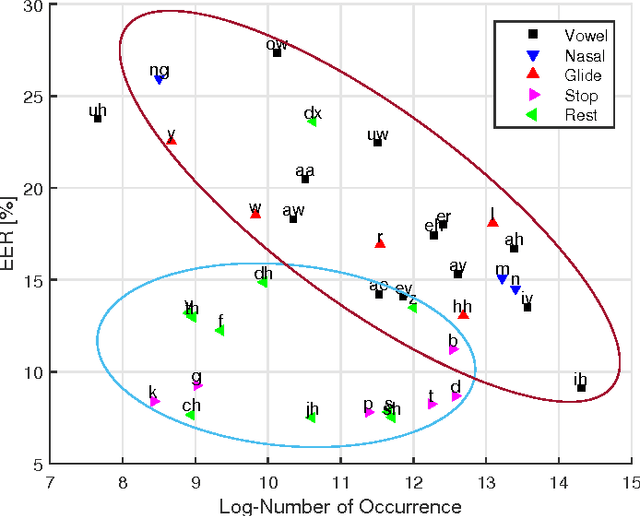
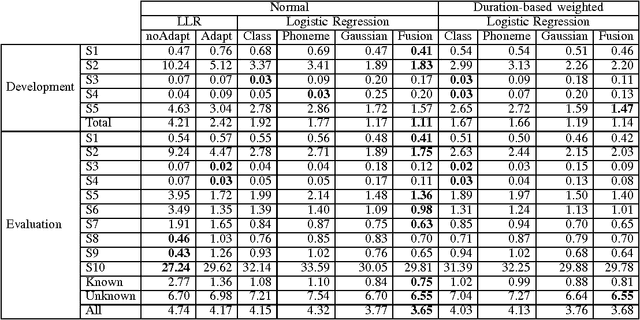
Speaker verification systems are vulnerable to spoofing attacks which presents a major problem in their real-life deployment. To date, most of the proposed synthetic speech detectors (SSDs) have weighted the importance of different segments of speech equally. However, different attack methods have different strengths and weaknesses and the traces that they leave may be short or long term acoustic artifacts. Moreover, those may occur for only particular phonemes or sounds. Here, we propose three algorithms that weigh likelihood-ratio scores of individual frames, phonemes, and sound-classes depending on their importance for the SSD. Significant improvement over the baseline system has been obtained for known attack methods that were used in training the SSDs. However, improvement with unknown attack types was not substantial. Thus, the type of distortions that were caused by the unknown systems were different and could not be captured better with the proposed SSD compared to the baseline SSD.
Incorporation of Speech Duration Information in Score Fusion of Speaker Recognition Systems
Aug 07, 2016
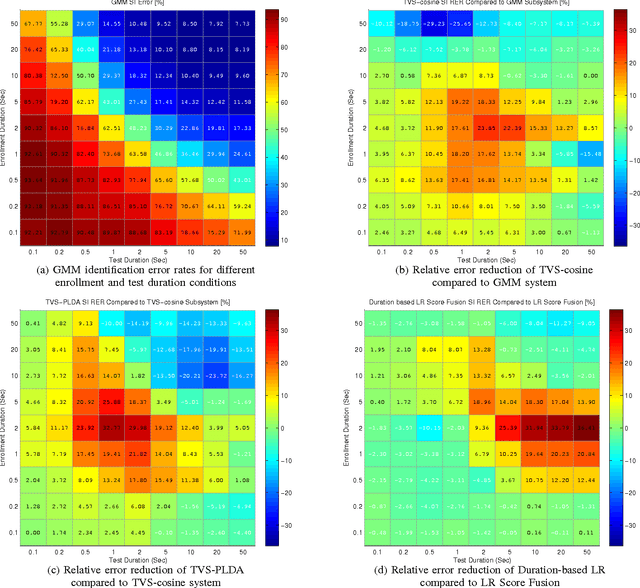

In recent years identity-vector (i-vector) based speaker verification (SV) systems have become very successful. Nevertheless, environmental noise and speech duration variability still have a significant effect on degrading the performance of these systems. In many real-life applications, duration of recordings are very short; as a result, extracted i-vectors cannot reliably represent the attributes of the speaker. Here, we investigate the effect of speech duration on the performance of three state-of-the-art speaker recognition systems. In addition, using a variety of available score fusion methods, we investigate the effect of score fusion for those speaker verification techniques to benefit from the performance difference of different methods under different enrollment and test speech duration conditions. This technique performed significantly better than the baseline score fusion methods.