 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom RAG to Agentic RAG for Faithful Islamic Question Answering
Jan 12, 2026LLMs are increasingly used for Islamic question answering, where ungrounded responses may carry serious religious consequences. Yet standard MCQ/MRC-style evaluations do not capture key real-world failure modes, notably free-form hallucinations and whether models appropriately abstain when evidence is lacking. To shed a light on this aspect we introduce ISLAMICFAITHQA, a 3,810-item bilingual (Arabic/English) generative benchmark with atomic single-gold answers, which enables direct measurement of hallucination and abstention. We additionally developed an end-to-end grounded Islamic modelling suite consisting of (i) 25K Arabic text-grounded SFT reasoning pairs, (ii) 5K bilingual preference samples for reward-guided alignment, and (iii) a verse-level Qur'an retrieval corpus of $\sim$6k atomic verses (ayat). Building on these resources, we develop an agentic Quran-grounding framework (agentic RAG) that uses structured tool calls for iterative evidence seeking and answer revision. Experiments across Arabic-centric and multilingual LLMs show that retrieval improves correctness and that agentic RAG yields the largest gains beyond standard RAG, achieving state-of-the-art performance and stronger Arabic-English robustness even with a small model (i.e., Qwen3 4B). We will make the experimental resources and datasets publicly available for the community.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025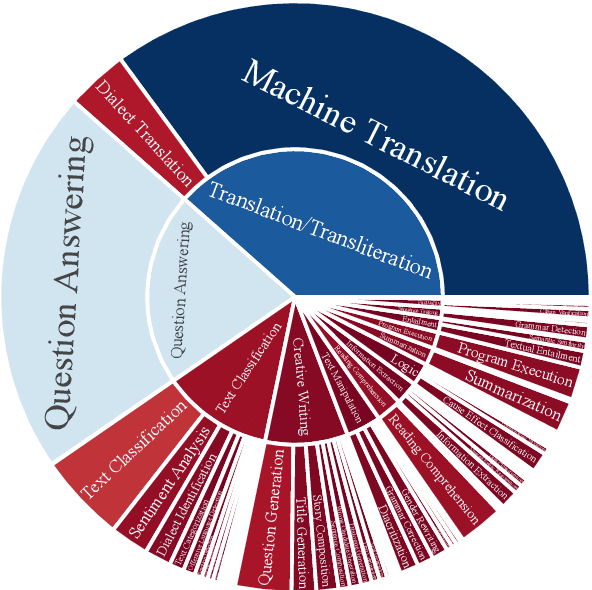



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Beyond Orthography: Automatic Recovery of Short Vowels and Dialectal Sounds in Arabic
Aug 05, 2024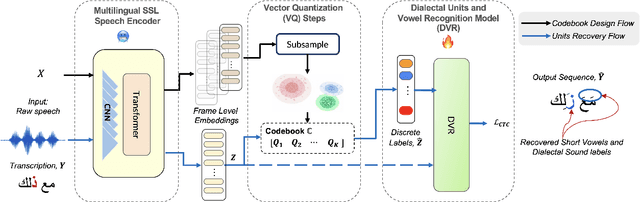

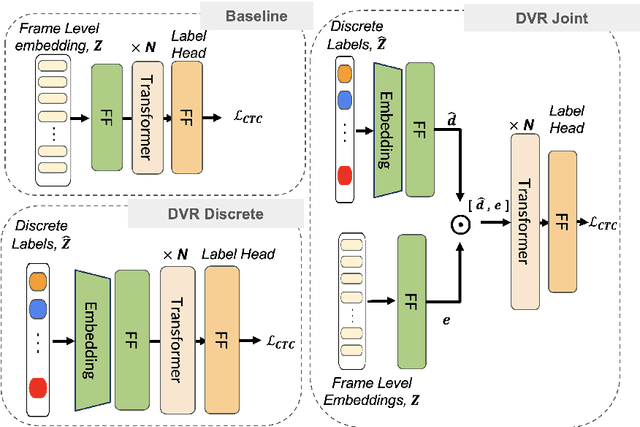

This paper presents a novel Dialectal Sound and Vowelization Recovery framework, designed to recognize borrowed and dialectal sounds within phonologically diverse and dialect-rich languages, that extends beyond its standard orthographic sound sets. The proposed framework utilized a quantized sequence of input with(out) continuous pretrained self-supervised representation. We show the efficacy of the pipeline using limited data for Arabic, a dialect-rich language containing more than 22 major dialects. Phonetically correct transcribed speech resources for dialectal Arabic are scarce. Therefore, we introduce ArabVoice15, a first-of-its-kind, curated test set featuring 5 hours of dialectal speech across 15 Arab countries, with phonetically accurate transcriptions, including borrowed and dialect-specific sounds. We described in detail the annotation guideline along with the analysis of the dialectal confusion pairs. Our extensive evaluation includes both subjective -- human perception tests and objective measures. Our empirical results, reported with three test sets, show that with only one and half hours of training data, our model improve character error rate by ~ 7\% in ArabVoice15 compared to the baseline.
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Mar 07, 2024
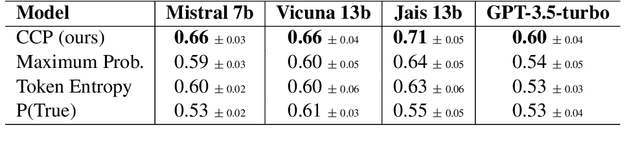
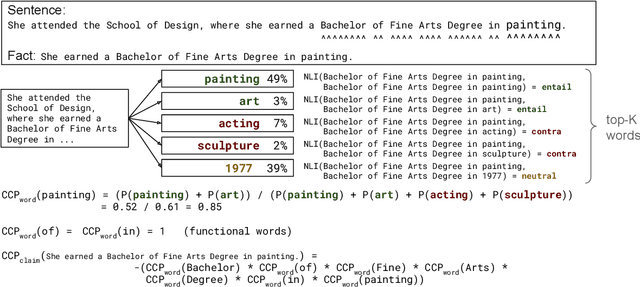
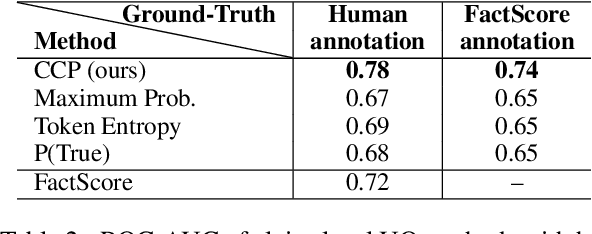
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factual, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for six different LLMs and three languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
ArAIEval Shared Task: Persuasion Techniques and Disinformation Detection in Arabic Text
Nov 06, 2023



We present an overview of the ArAIEval shared task, organized as part of the first ArabicNLP 2023 conference co-located with EMNLP 2023. ArAIEval offers two tasks over Arabic text: (i) persuasion technique detection, focusing on identifying persuasion techniques in tweets and news articles, and (ii) disinformation detection in binary and multiclass setups over tweets. A total of 20 teams participated in the final evaluation phase, with 14 and 16 teams participating in Tasks 1 and 2, respectively. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further give a brief overview of the participating systems. All datasets and evaluation scripts from the shared task are released to the research community. (https://araieval.gitlab.io/) We hope this will enable further research on these important tasks in Arabic.
LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
Aug 09, 2023


The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework. Initially developed to evaluate Arabic NLP tasks using OpenAI's GPT and BLOOM models; it can be seamlessly customized for any NLP task and model, regardless of language. The framework also features zero- and few-shot learning settings. A new custom dataset can be added in less than 10 minutes, and users can use their own model API keys to evaluate the task at hand. The developed framework has been already tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We plan to open-source the framework for the community (https://github.com/qcri/LLMeBench/). A video demonstrating the framework is available online (https://youtu.be/FkQn4UjYA0s).
Benchmarking Arabic AI with Large Language Models
May 24, 2023With large Foundation Models (FMs), language technologies (AI in general) are entering a new paradigm: eliminating the need for developing large-scale task-specific datasets and supporting a variety of tasks through set-ups ranging from zero-shot to few-shot learning. However, understanding FMs capabilities requires a systematic benchmarking effort by comparing FMs performance with the state-of-the-art (SOTA) task-specific models. With that goal, past work focused on the English language and included a few efforts with multiple languages. Our study contributes to ongoing research by evaluating FMs performance for standard Arabic NLP and Speech processing, including a range of tasks from sequence tagging to content classification across diverse domains. We start with zero-shot learning using GPT-3.5-turbo, Whisper, and USM, addressing 33 unique tasks using 59 publicly available datasets resulting in 96 test setups. For a few tasks, FMs performs on par or exceeds the performance of the SOTA models but for the majority it under-performs. Given the importance of prompt for the FMs performance, we discuss our prompt strategies in detail and elaborate on our findings. Our future work on Arabic AI will explore few-shot prompting, expand the range of tasks, and investigate additional open-source models.
QVoice: Arabic Speech Pronunciation Learning Application
May 09, 2023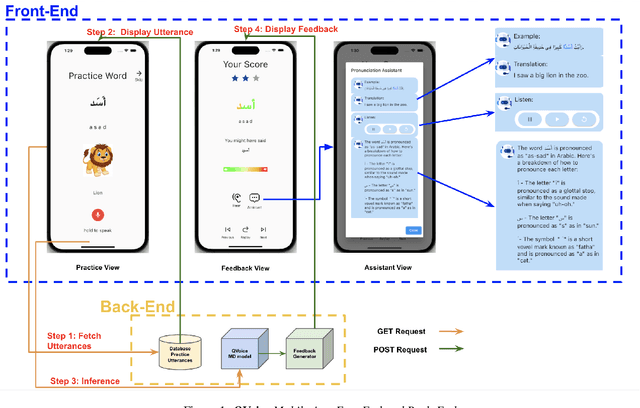
This paper introduces a novel Arabic pronunciation learning application QVoice, powered with end-to-end mispronunciation detection and feedback generator module. The application is designed to support non-native Arabic speakers in enhancing their pronunciation skills, while also helping native speakers mitigate any potential influence from regional dialects on their Modern Standard Arabic (MSA) pronunciation. QVoice employs various learning cues to aid learners in comprehending meaning, drawing connections with their existing knowledge of English language, and offers detailed feedback for pronunciation correction, along with contextual examples showcasing word usage. The learning cues featured in QVoice encompass a wide range of meaningful information, such as visualizations of phrases/words and their translations, as well as phonetic transcriptions and transliterations. QVoice provides pronunciation feedback at the character level and assesses performance at the word level.
* 2 pages, Accepted InterSpeech23 Show & Tell Demo Session
Detecting and Reasoning of Deleted Tweets before they are Posted
May 05, 2023



Social media platforms empower us in several ways, from information dissemination to consumption. While these platforms are useful in promoting citizen journalism, public awareness etc., they have misuse potentials. Malicious users use them to disseminate hate-speech, offensive content, rumor etc. to gain social and political agendas or to harm individuals, entities and organizations. Often times, general users unconsciously share information without verifying it, or unintentionally post harmful messages. Some of such content often get deleted either by the platform due to the violation of terms and policies, or users themselves for different reasons, e.g., regrets. There is a wide range of studies in characterizing, understanding and predicting deleted content. However, studies which aims to identify the fine-grained reasons (e.g., posts are offensive, hate speech or no identifiable reason) behind deleted content, are limited. In this study we address this gap, by identifying deleted tweets, particularly within the Arabic context, and labeling them with a corresponding fine-grained disinformation category. We then develop models that can predict the potentiality of tweets getting deleted, as well as the potential reasons behind deletion. Such models can help in moderating social media posts before even posting.
Unsupervised Data Selection for TTS: Using Arabic Broadcast News as a Case Study
Jan 26, 2023Several high-resource Text to Speech (TTS) systems currently produce natural, well-established human-like speech. In contrast, low-resource languages, including Arabic, have very limited TTS systems due to the lack of resources. We propose a fully unsupervised method for building TTS, including automatic data selection and pre-training/fine-tuning strategies for TTS training, using broadcast news as a case study. We show how careful selection of data, yet smaller amounts, can improve the efficiency of TTS system in generating more natural speech than a system trained on a bigger dataset. We adopt to propose different approaches for the: 1) data: we applied automatic annotations using DNSMOS, automatic vowelization, and automatic speech recognition (ASR) for fixing transcriptions' errors; 2) model: we used transfer learning from high-resource language in TTS model and fine-tuned it with one hour broadcast recording then we used this model to guide a FastSpeech2-based Conformer model for duration. Our objective evaluation shows 3.9% character error rate (CER), while the groundtruth has 1.3% CER. As for the subjective evaluation, where 1 is bad and 5 is excellent, our FastSpeech2-based Conformer model achieved a mean opinion score (MOS) of 4.4 for intelligibility and 4.2 for naturalness, where many annotators recognized the voice of the broadcaster, which proves the effectiveness of our proposed unsupervised method.