 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Consistency from Only Two Samples: CoT-PoT Ensembling for Efficient LLM Reasoning
Apr 19, 2026Self-consistency (SC) is a popular technique for improving the reasoning accuracy of large language models by aggregating multiple sampled outputs, but it comes at a high computational cost due to extensive sampling. We introduce a hybrid ensembling approach that leverages the complementary strengths of two distinct modes of reasoning: Chain-of-Thought (CoT) and Program-of-Thought (PoT). We describe a general framework for combining these two forms of reasoning in self-consistency, as well as particular strategies for both full sampling and early-stopping. We show that CoT-PoT ensembling not only improves overall accuracy, but also drastically reduces the number of samples required for SC by a factor of 9.3x. In particular, the majority of tasks (78.6%) can be addressed with only two samples, which has not been possible with any prior SC methods.
Fanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Fanar-Sadiq: A Multi-Agent Architecture for Grounded Islamic QA
Mar 10, 2026Large language models (LLMs) can answer religious knowledge queries fluently, yet they often hallucinate and misattribute sources, which is especially consequential in Islamic settings where users expect grounding in canonical texts (Qur'an and Hadith) and jurisprudential (fiqh) nuance. Retrieval-augmented generation (RAG) reduces some of these limitations by grounding generation in external evidence. However, a single ``retrieve-then-generate'' pipeline is limited to deal with the diversity of Islamic queries. Users may request verbatim scripture, fatwa-style guidance with citations or rule-constrained computations such as zakat and inheritance that require strict arithmetic and legal invariants. In this work, we present a bilingual (Arabic/English) multi-agent Islamic assistant, called Fanar-Sadiq, which is a core component of the Fanar AI platform. Fanar-Sadiq routes Islamic-related queries to specialized modules within an agentic, tool-using architecture. The system supports intent-aware routing, retrieval-grounded fiqh answers with deterministic citation normalization and verification traces, exact verse lookup with quotation validation, and deterministic calculators for Sunni zakat and inheritance with madhhab-sensitive branching. We evaluate the complete end-to-end system on public Islamic QA benchmarks and demonstrate effectiveness and efficiency. Our system is currently publicly and freely accessible through API and a Web application, and has been accessed $\approx$1.9M times in less than a year.
SpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild?
Feb 03, 2026Spatial reasoning is a fundamental aspect of human cognition, yet it remains a major challenge for contemporary vision-language models (VLMs). Prior work largely relied on synthetic or LLM-generated environments with limited task designs and puzzle-like setups, failing to capture the real-world complexity, visual noise, and diverse spatial relationships that VLMs encounter. To address this, we introduce SpatiaLab, a comprehensive benchmark for evaluating VLMs' spatial reasoning in realistic, unconstrained contexts. SpatiaLab comprises 1,400 visual question-answer pairs across six major categories: Relative Positioning, Depth & Occlusion, Orientation, Size & Scale, Spatial Navigation, and 3D Geometry, each with five subcategories, yielding 30 distinct task types. Each subcategory contains at least 25 questions, and each main category includes at least 200 questions, supporting both multiple-choice and open-ended evaluation. Experiments across diverse state-of-the-art VLMs, including open- and closed-source models, reasoning-focused, and specialized spatial reasoning models, reveal a substantial gap in spatial reasoning capabilities compared with humans. In the multiple-choice setup, InternVL3.5-72B achieves 54.93% accuracy versus 87.57% for humans. In the open-ended setting, all models show a performance drop of around 10-25%, with GPT-5-mini scoring highest at 40.93% versus 64.93% for humans. These results highlight key limitations in handling complex spatial relationships, depth perception, navigation, and 3D geometry. By providing a diverse, real-world evaluation framework, SpatiaLab exposes critical challenges and opportunities for advancing VLMs' spatial reasoning, offering a benchmark to guide future research toward robust, human-aligned spatial understanding. SpatiaLab is available at: https://spatialab-reasoning.github.io/.
There Is More to Refusal in Large Language Models than a Single Direction
Feb 02, 2026Prior work argues that refusal in large language models is mediated by a single activation-space direction, enabling effective steering and ablation. We show that this account is incomplete. Across eleven categories of refusal and non-compliance, including safety, incomplete or unsupported requests, anthropomorphization, and over-refusal, we find that these refusal behaviors correspond to geometrically distinct directions in activation space. Yet despite this diversity, linear steering along any refusal-related direction produces nearly identical refusal to over-refusal trade-offs, acting as a shared one-dimensional control knob. The primary effect of different directions is not whether the model refuses, but how it refuses.
Do I Really Know? Learning Factual Self-Verification for Hallucination Reduction
Feb 02, 2026Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.
Improving Language Models Trained with Translated Data via Continual Pre-Training and Dictionary Learning Analysis
May 23, 2024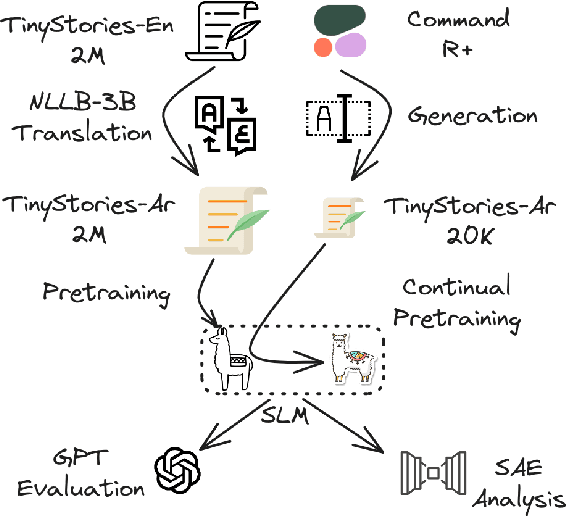
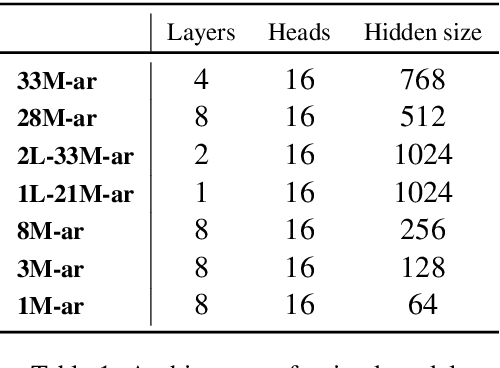
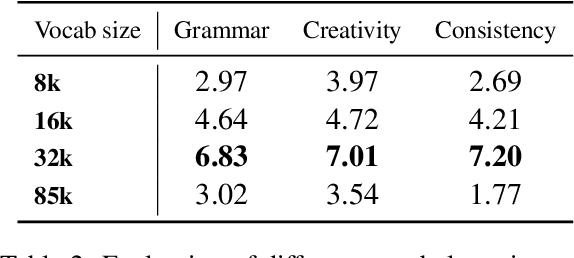
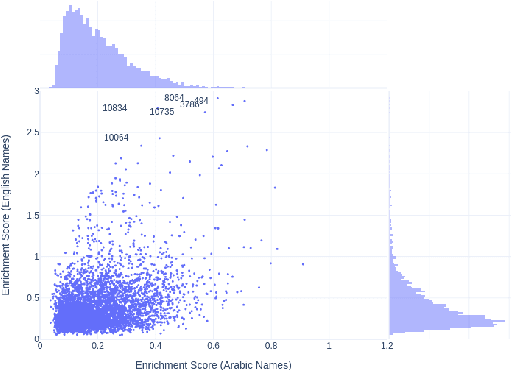
Training LLMs in low resources languages usually utilizes data augmentation with machine translation (MT) from English language. However, translation brings a number of challenges: there are large costs attached to translating and curating huge amounts of content with high-end machine translation solutions, the translated content carries over cultural biases, and if the translation is not faithful and accurate, the quality of the data degrades causing issues in the trained model. In this work we investigate the role of translation and synthetic data in training language models. We translate TinyStories, a dataset of 2.2M short stories for 3-4 year old children, from English to Arabic using the free NLLB-3B MT model. We train a number of story generation models of sizes 1M-33M parameters using this data. We identify a number of quality and task-specific issues in the resulting models. To rectify these issues, we further pre-train the models with a small dataset of synthesized high-quality stories, representing 1\% of the original training data, using a capable LLM in Arabic. We show using GPT-4 as a judge and dictionary learning analysis from mechanistic interpretability that the suggested approach is a practical means to resolve some of the translation pitfalls. We illustrate the improvement through case studies of linguistic issues and cultural bias.
Exploring Alignment in Shared Cross-lingual Spaces
May 23, 2024



Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the \textit{alignment} and \textit{overlap} of these concepts across various languages within the latent space. To this end, we introduce two metrics \CA{} and \CO{} aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (\texttt{mT5}, \texttt{mBERT}, and \texttt{XLM-R}) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual \textit{alignment} due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances \textit{alignment} within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.\footnote{The code is available at \url{https://github.com/baselmousi/multilingual-latent-concepts}}
Analyzing Multilingual Competency of LLMs in Multi-Turn Instruction Following: A Case Study of Arabic
Oct 23, 2023



While significant progress has been made in benchmarking Large Language Models (LLMs) across various tasks, there is a lack of comprehensive evaluation of their abilities in responding to multi-turn instructions in less-commonly tested languages like Arabic. Our paper offers a detailed examination of the proficiency of open LLMs in such scenarios in Arabic. Utilizing a customized Arabic translation of the MT-Bench benchmark suite, we employ GPT-4 as a uniform evaluator for both English and Arabic queries to assess and compare the performance of the LLMs on various open-ended tasks. Our findings reveal variations in model responses on different task categories, e.g., logic vs. literacy, when instructed in English or Arabic. We find that fine-tuned base models using multilingual and multi-turn datasets could be competitive to models trained from scratch on multilingual data. Finally, we hypothesize that an ensemble of small, open LLMs could perform competitively to proprietary LLMs on the benchmark.
Scaled-up Discovery of Latent Concepts in Deep NLP Models
Aug 20, 2023
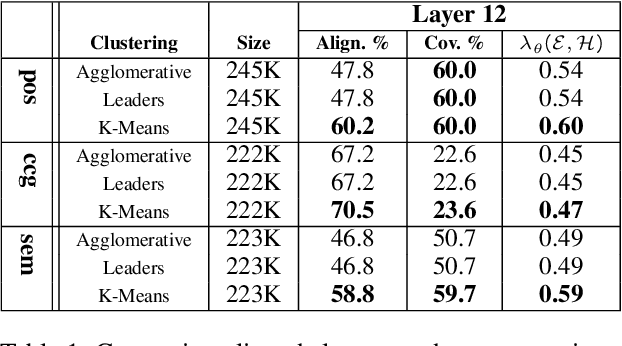

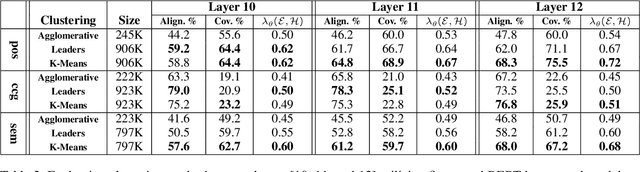
Pre-trained language models (pLMs) learn intricate patterns and contextual dependencies via unsupervised learning on vast text data, driving breakthroughs across NLP tasks. Despite these achievements, these models remain black boxes, necessitating research into understanding their decision-making processes. Recent studies explore representation analysis by clustering latent spaces within pre-trained models. However, these approaches are limited in terms of scalability and the scope of interpretation because of high computation costs of clustering algorithms. This study focuses on comparing clustering algorithms for the purpose of scaling encoded concept discovery of representations from pLMs. Specifically, we compare three algorithms in their capacity to unveil the encoded concepts through their alignment to human-defined ontologies: Agglomerative Hierarchical Clustering, Leaders Algorithm, and K-Means Clustering. Our results show that K-Means has the potential to scale to very large datasets, allowing rich latent concept discovery, both on the word and phrase level.