 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Unscented Autoencoders for Trajectory Prediction
Oct 30, 2023



The \ac{CVAE} is one of the most widely-used models in trajectory prediction for \ac{AD}. It captures the interplay between a driving context and its ground-truth future into a probabilistic latent space and uses it to produce predictions. In this paper, we challenge key components of the CVAE. We leverage recent advances in the space of the VAE, the foundation of the CVAE, which show that a simple change in the sampling procedure can greatly benefit performance. We find that unscented sampling, which draws samples from any learned distribution in a deterministic manner, can naturally be better suited to trajectory prediction than potentially dangerous random sampling. We go further and offer additional improvements, including a more structured mixture latent space, as well as a novel, potentially more expressive way to do inference with CVAEs. We show wide applicability of our models by evaluating them on the INTERACTION prediction dataset, outperforming the state of the art, as well as at the task of image modeling on the CelebA dataset, outperforming the baseline vanilla CVAE. Code is available at https://github.com/boschresearch/cuae-prediction.
Comparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving
May 25, 2023
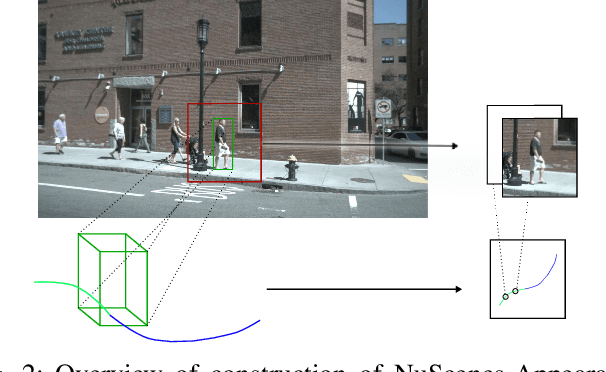
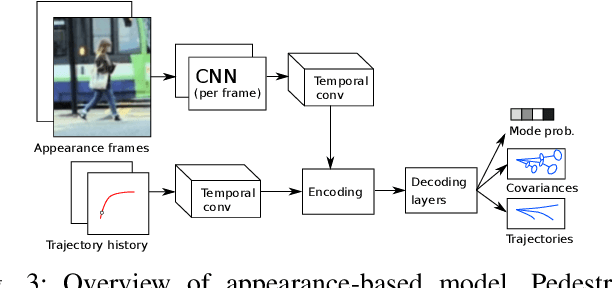
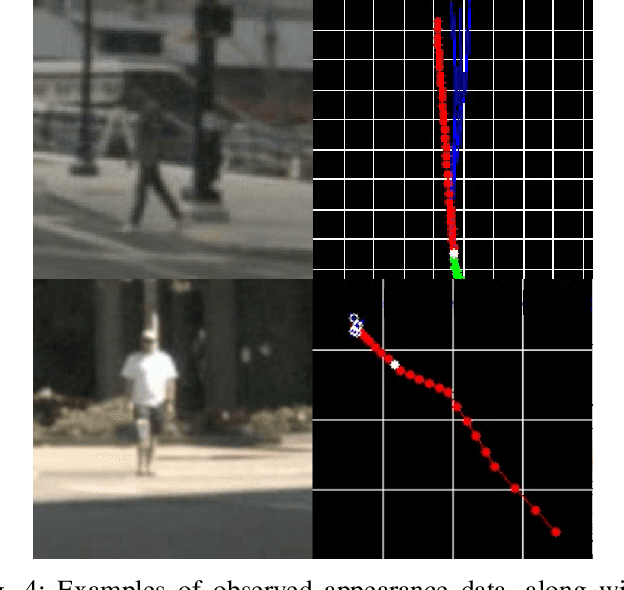
The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.
DiPA: Diverse and Probabilistically Accurate Interactive Prediction
Oct 12, 2022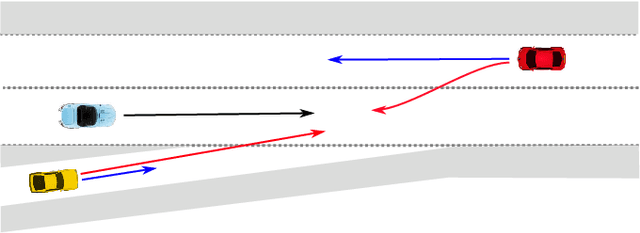
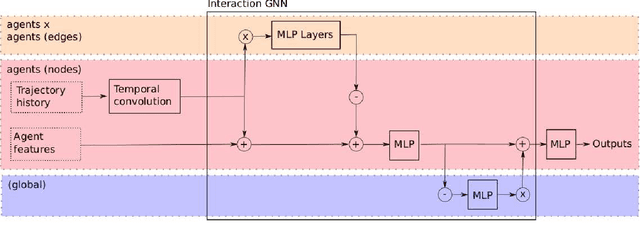

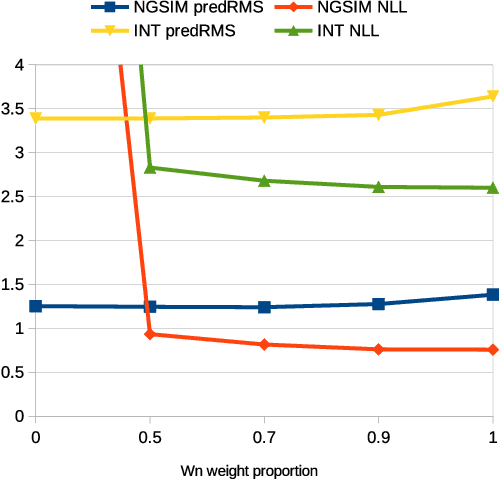
Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Previous interactive predictors have used closest-mode evaluations, which test if one of a set of predictions covers the ground-truth, but not if additional unlikely predictions are made. The presence of unlikely predictions can interfere with planning, by indicating conflict with the ego plan when it is not likely to occur. Closest-mode evaluations are not sufficient for showing a predictor is useful, an effective predictor also needs to accurately estimate mode probabilities, and to be evaluated using probabilistic measures. These two evaluation approaches, eg. predicted-mode RMS and minADE/FDE, are analogous to precision and recall in binary classification, and there is a challenging trade-off between prediction strategies for each. We present DiPA, a method for producing diverse predictions while also capturing accurate probabilistic estimates. DiPA uses a flexible representation that captures interactions in widely varying road topologies, and uses a novel training regime for a Gaussian Mixture Model that supports diversity of predicted modes, along with accurate spatial distribution and mode probability estimates. DiPA achieves state-of-the-art performance on INTERACTION and NGSIM, and improves over a baseline (MFP) when both closest-mode and probabilistic evaluations are used at the same time.
Beyond RMSE: Do machine-learned models of road user interaction produce human-like behavior?
Jun 22, 2022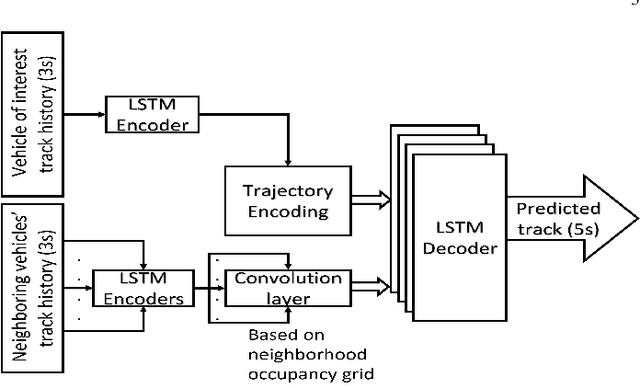
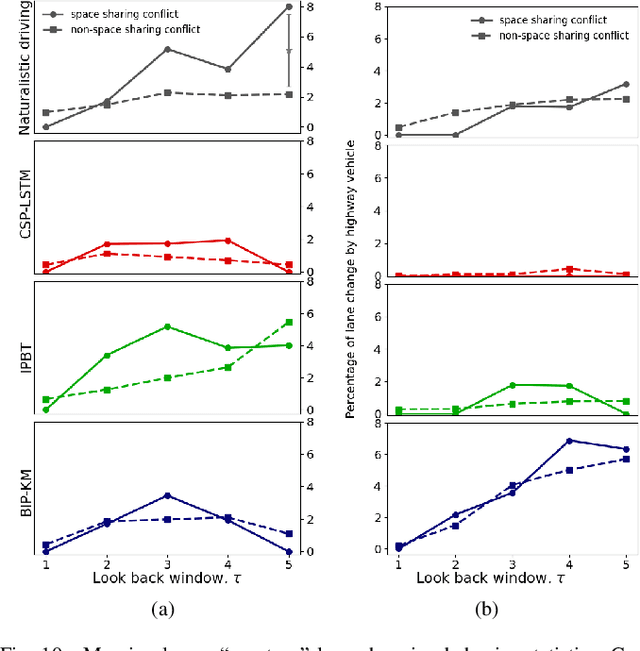
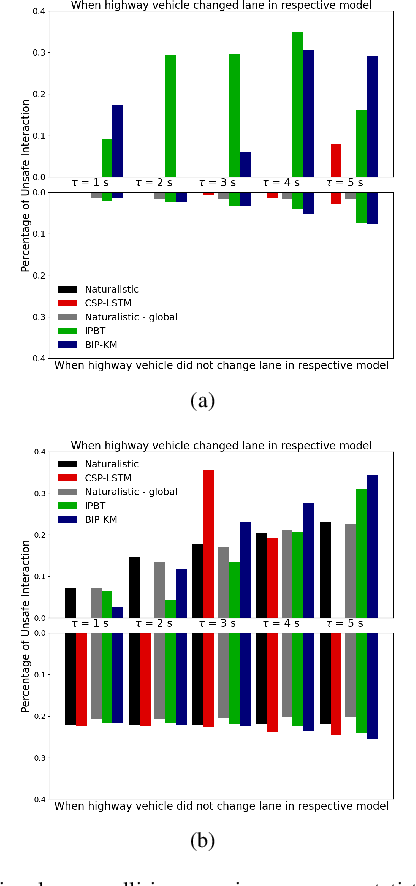
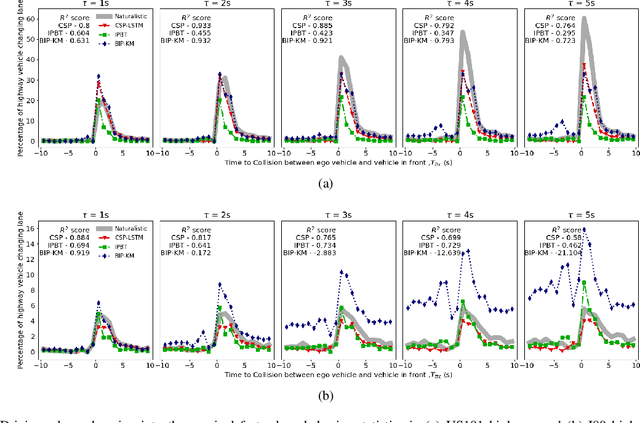
Autonomous vehicles use a variety of sensors and machine-learned models to predict the behavior of surrounding road users. Most of the machine-learned models in the literature focus on quantitative error metrics like the root mean square error (RMSE) to learn and report their models' capabilities. This focus on quantitative error metrics tends to ignore the more important behavioral aspect of the models, raising the question of whether these models really predict human-like behavior. Thus, we propose to analyze the output of machine-learned models much like we would analyze human data in conventional behavioral research. We introduce quantitative metrics to demonstrate presence of three different behavioral phenomena in a naturalistic highway driving dataset: 1) The kinematics-dependence of who passes a merging point first 2) Lane change by an on-highway vehicle to accommodate an on-ramp vehicle 3) Lane changes by vehicles on the highway to avoid lead vehicle conflicts. Then, we analyze the behavior of three machine-learned models using the same metrics. Even though the models' RMSE value differed, all the models captured the kinematic-dependent merging behavior but struggled at varying degrees to capture the more nuanced courtesy lane change and highway lane change behavior. Additionally, the collision aversion analysis during lane changes showed that the models struggled to capture the physical aspect of human driving: leaving adequate gap between the vehicles. Thus, our analysis highlighted the inadequacy of simple quantitative metrics and the need to take a broader behavioral perspective when analyzing machine-learned models of human driving predictions.
Sparse, guided feature connections in an Abstract Deep Network
Dec 16, 2014
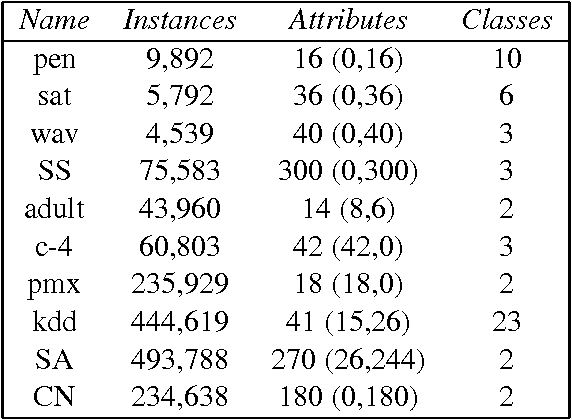

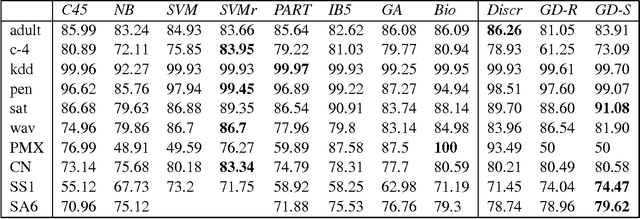
We present a technique for developing a network of re-used features, where the topology is formed using a coarse learning method, that allows gradient-descent fine tuning, known as an Abstract Deep Network (ADN). New features are built based on observed co-occurrences, and the network is maintained using a selection process related to evolutionary algorithms. This allows coarse ex- ploration of the problem space, effective for irregular domains, while gradient descent allows pre- cise solutions. Accuracy on standard UCI and Protein-Structure Prediction problems is comparable with benchmark SVM and optimized GBML approaches, and shows scalability for addressing large problems. The discrete implementation is symbolic, allowing interpretability, while the continuous method using fine-tuning shows improved accuracy. The binary multiplexer problem is explored, as an irregular domain that does not support gradient descent learning, showing solution to the bench- mark 135-bit problem. A convolutional implementation is demonstrated on image classification, showing an error-rate of 0.79% on the MNIST problem, without a pre-defined topology. The ADN system provides a method for developing a very sparse, deep feature topology, based on observed relationships between features, that is able to find solutions in irregular domains, and initialize a network prior to gradient descent learning.