 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving
May 25, 2023
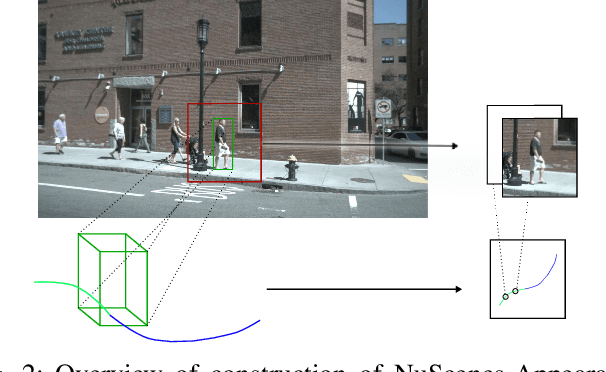
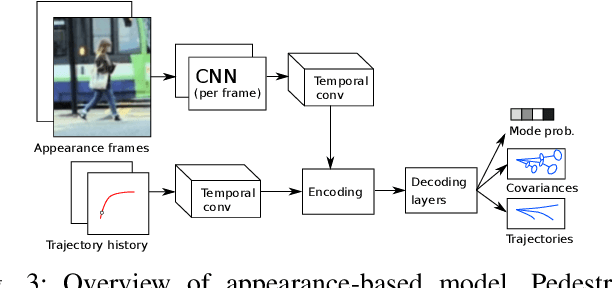
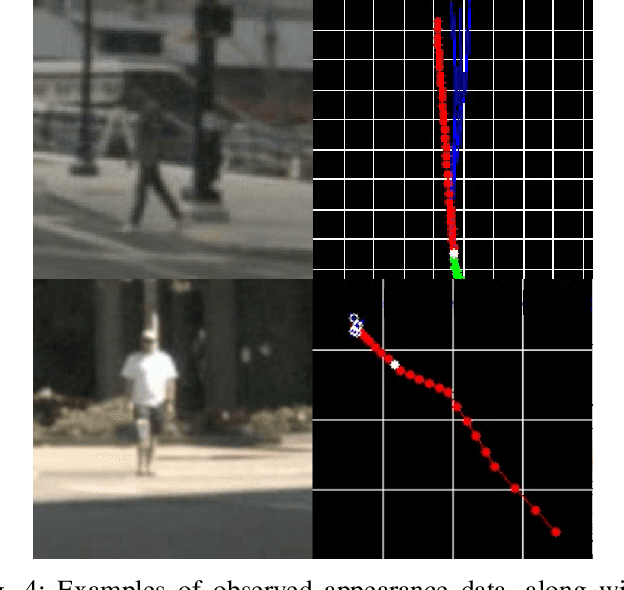
The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.
Perspectives on the System-level Design of a Safe Autonomous Driving Stack
Jul 29, 2022
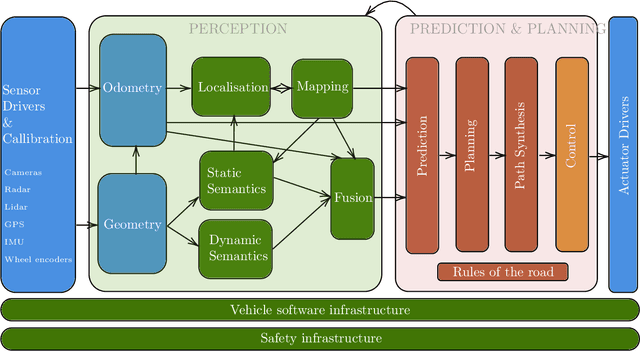
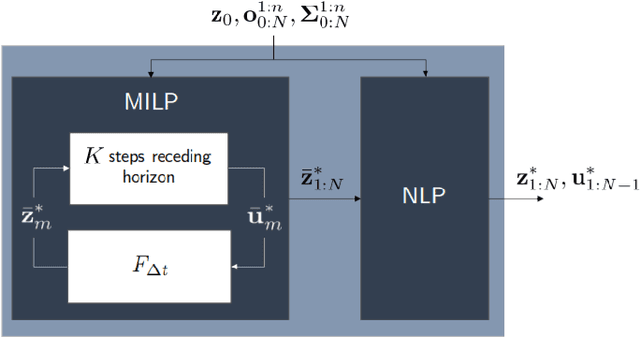
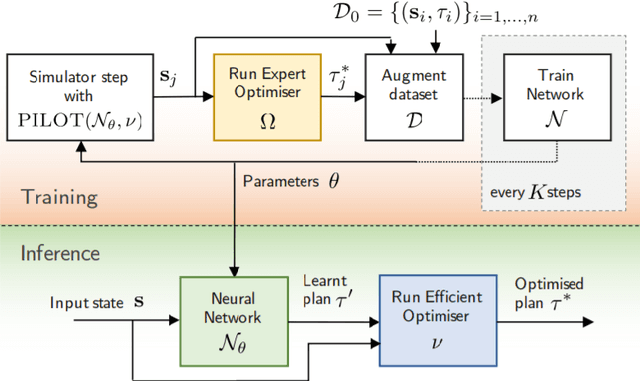
Achieving safe and robust autonomy is the key bottleneck on the path towards broader adoption of autonomous vehicles technology. This motivates going beyond extrinsic metrics such as miles between disengagement, and calls for approaches that embody safety by design. In this paper, we address some aspects of this challenge, with emphasis on issues of motion planning and prediction. We do this through description of novel approaches taken to solving selected sub-problems within an autonomous driving stack, in the process introducing the design philosophy being adopted within Five. This includes safe-by-design planning, interpretable as well as verifiable prediction, and modelling of perception errors to enable effective sim-to-real and real-to-sim transfer within the testing pipeline of a realistic autonomous system.
Beyond RMSE: Do machine-learned models of road user interaction produce human-like behavior?
Jun 22, 2022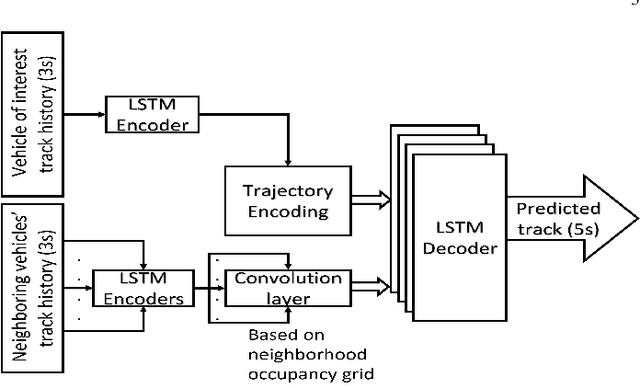
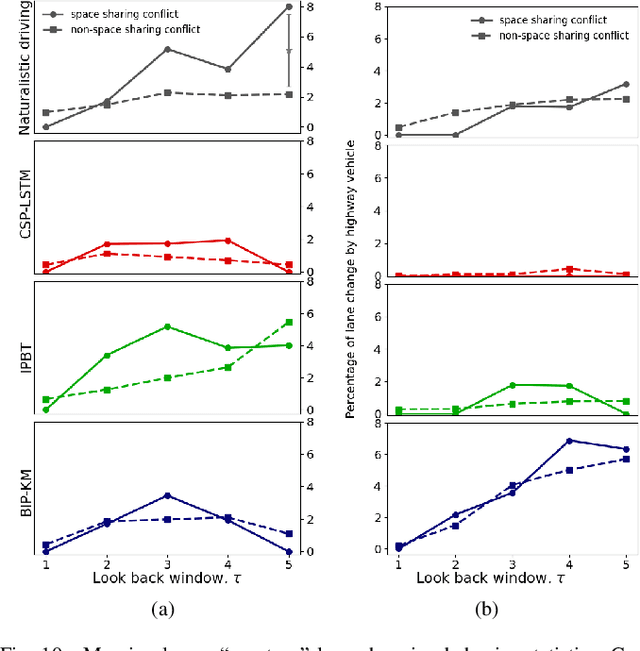
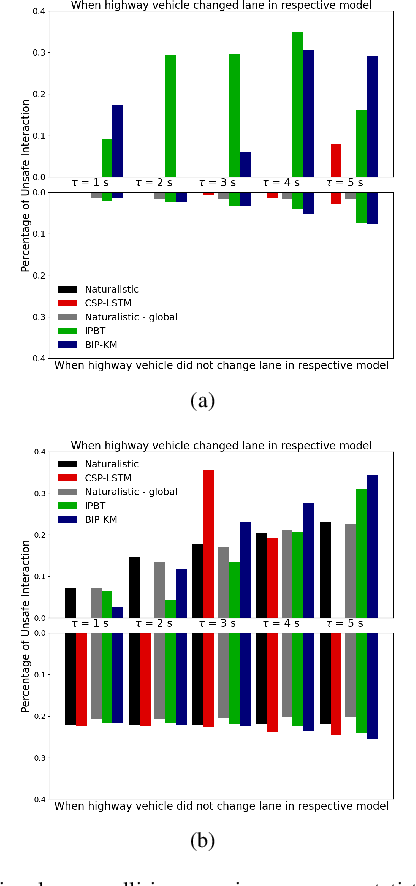
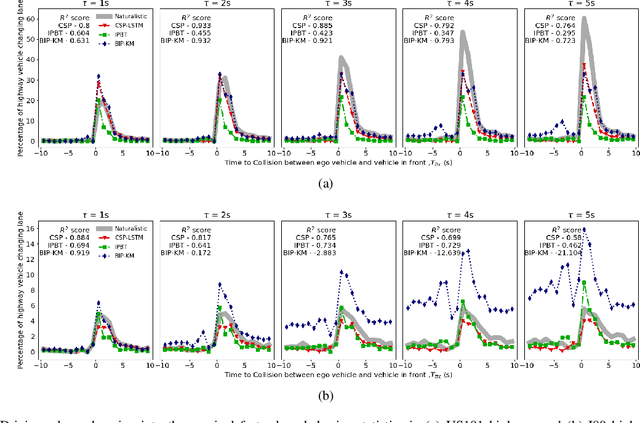
Autonomous vehicles use a variety of sensors and machine-learned models to predict the behavior of surrounding road users. Most of the machine-learned models in the literature focus on quantitative error metrics like the root mean square error (RMSE) to learn and report their models' capabilities. This focus on quantitative error metrics tends to ignore the more important behavioral aspect of the models, raising the question of whether these models really predict human-like behavior. Thus, we propose to analyze the output of machine-learned models much like we would analyze human data in conventional behavioral research. We introduce quantitative metrics to demonstrate presence of three different behavioral phenomena in a naturalistic highway driving dataset: 1) The kinematics-dependence of who passes a merging point first 2) Lane change by an on-highway vehicle to accommodate an on-ramp vehicle 3) Lane changes by vehicles on the highway to avoid lead vehicle conflicts. Then, we analyze the behavior of three machine-learned models using the same metrics. Even though the models' RMSE value differed, all the models captured the kinematic-dependent merging behavior but struggled at varying degrees to capture the more nuanced courtesy lane change and highway lane change behavior. Additionally, the collision aversion analysis during lane changes showed that the models struggled to capture the physical aspect of human driving: leaving adequate gap between the vehicles. Thus, our analysis highlighted the inadequacy of simple quantitative metrics and the need to take a broader behavioral perspective when analyzing machine-learned models of human driving predictions.
Flash: Fast and Light Motion Prediction for Autonomous Driving with Bayesian Inverse Planning and Learned Motion Profiles
Mar 15, 2022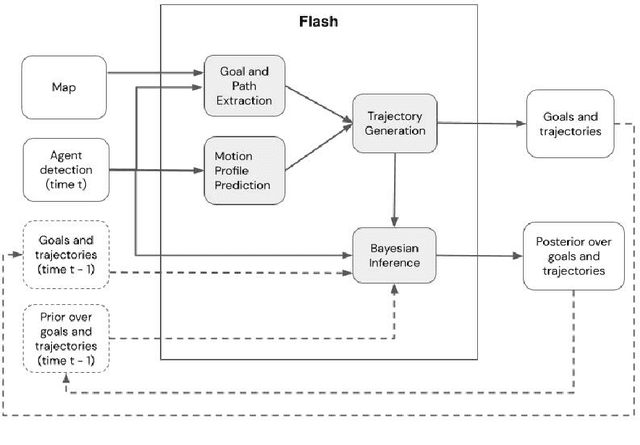
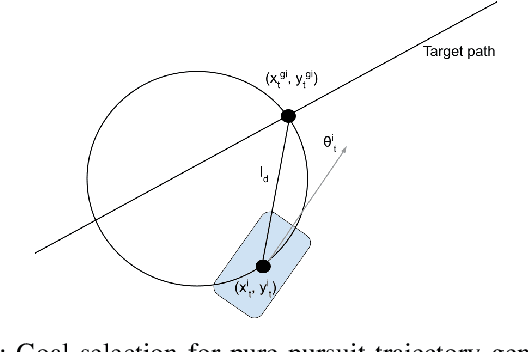
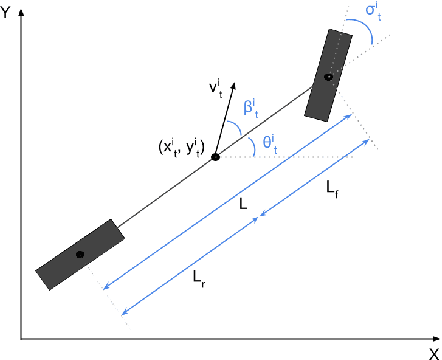
Motion prediction of road users in traffic scenes is critical for autonomous driving systems that must take safe and robust decisions in complex dynamic environments. We present a novel motion prediction system for autonomous driving. Our system is based on the Bayesian inverse planning framework, which efficiently orchestrates map-based goal extraction, a classical control-based trajectory generator and an ensemble of light-weight neural networks specialised in motion profile prediction. In contrast to many alternative methods, this modularity helps isolate performance factors and better interpret results, without compromising performance. This system addresses multiple aspects of interest, namely multi-modality, motion profile uncertainty and trajectory physical feasibility. We report on several experiments with the popular highway dataset NGSIM, demonstrating state-of-the-art performance in terms of trajectory error. We also perform a detailed analysis of our system's components, along with experiments that stratify the data based on behaviours, such as change lane versus follow lane, to provide insights into the challenges in this domain. Finally, we present a qualitative analysis to show other benefits of our approach, such as the ability to interpret the outputs.
Brain-Computer Interface meets ROS: A robotic approach to mentally drive telepresence robots
Apr 04, 2019
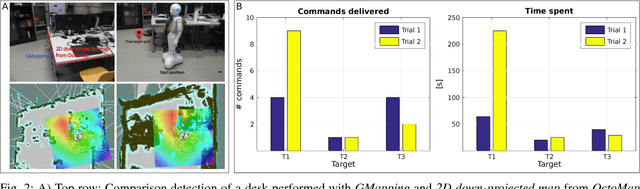
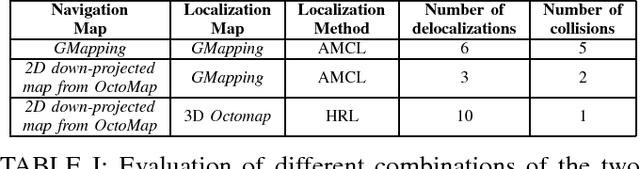
This paper shows and evaluates a novel approach to integrate a non-invasive Brain-Computer Interface (BCI) with the Robot Operating System (ROS) to mentally drive a telepresence robot. Controlling a mobile device by using human brain signals might improve the quality of life of people suffering from severe physical disabilities or elderly people who cannot move anymore. Thus, the BCI user is able to actively interact with relatives and friends located in different rooms thanks to a video streaming connection to the robot. To facilitate the control of the robot via BCI, we explore new ROS-based algorithms for navigation and obstacle avoidance, making the system safer and more reliable. In this regard, the robot can exploit two maps of the environment, one for localization and one for navigation, and both can be used also by the BCI user to watch the position of the robot while it is moving. As demonstrated by the experimental results, the user's cognitive workload is reduced, decreasing the number of commands necessary to complete the task and helping him/her to keep attention for longer periods of time.
RUR53: an Unmanned Ground Vehicle for Navigation, Recognition and Manipulation
Nov 23, 2017
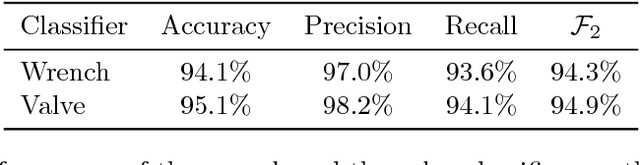
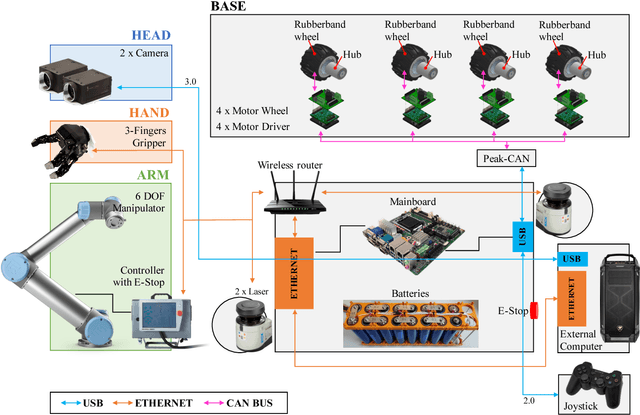
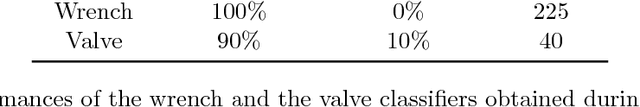
This paper describes RUR53, the unmanned mobile manipulator robot developed by the Desert Lion team of the University of Padova (Italy), and its experience in Challenge 2 and the Grand Challenge of the first Mohamed Bin Zayed International Robotics Challenge (Abu Dhabi, March 2017). According to the competition requirements, the robot is able to freely navigate inside an outdoor arena; locate and reach a panel; recognize and manipulate a wrench; use this wrench to physically operate a valve stem on the panel itself. RUR53 is able to perform these tasks both autonomously and in teleoperation mode. The paper details the adopted hardware and software architectures, focusing on its key aspects: modularity, generality, and the ability of exploiting sensor feedback. These features let the team rank third in the Gran Challenge in collaboration with the Czech Technical University in Prague, Czech Republic, the University of Pennsylvania, USA, and the University of Lincoln, UK. Tests performed both in the Challenge arena and in the lab are presented and discussed, focusing on the strengths and limitations of the proposed wrench and valve classification and recognition algorithms. Lessons learned are also detailed.
Fast and Robust Detection of Fallen People from a Mobile Robot
Mar 09, 2017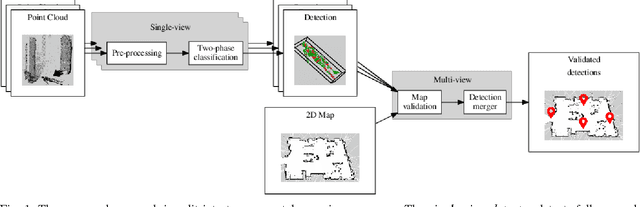

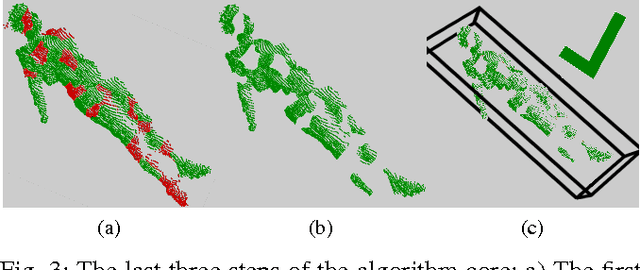

This paper deals with the problem of detecting fallen people lying on the floor by means of a mobile robot equipped with a 3D depth sensor. In the proposed algorithm, inspired by semantic segmentation techniques, the 3D scene is over-segmented into small patches. Fallen people are then detected by means of two SVM classifiers: the first one labels each patch, while the second one captures the spatial relations between them. This novel approach showed to be robust and fast. Indeed, thanks to the use of small patches, fallen people in real cluttered scenes with objects side by side are correctly detected. Moreover, the algorithm can be executed on a mobile robot fitted with a standard laptop making it possible to exploit the 2D environmental map built by the robot and the multiple points of view obtained during the robot navigation. Additionally, this algorithm is robust to illumination changes since it does not rely on RGB data but on depth data. All the methods have been thoroughly validated on the IASLAB-RGBD Fallen Person Dataset, which is published online as a further contribution. It consists of several static and dynamic sequences with 15 different people and 2 different environments.