 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceding Horizon Task and Motion Planning in Dynamic Environments
Sep 07, 2020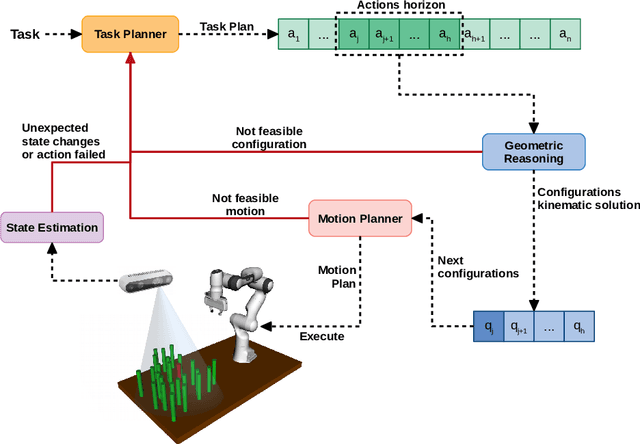


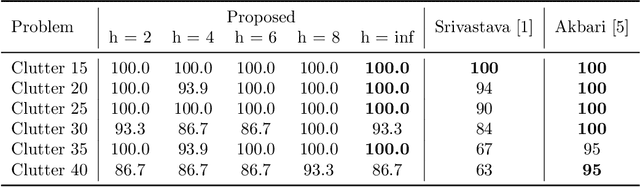
Complex manipulation tasks in crowded environments require careful integration of symbolic reasoning and motion planning. This problem, commonly defined as Task and Motion Planning (TAMP), is even more challenging if the working space is dynamic and perceived with noisy, non-ideal sensors. In this work, we propose an online, approximated TAMP method that combines a geometric reasoning module and a motion planner with a standard task planner in a receding horizon fashion. Our approach iteratively solves a reduced planning problem over a receding window of a limited number of future actions during the implementation of the actions. At each iteration, only the first action of the horizon is actually implemented, then the window is moved forward and the problem is solved again. This procedure allows to naturally take into account the dynamic changes on the scene while ensuring good runtime performance. We validate our approach within extensive simulated experiments that show that our approach is able to deal with unexpected random changes in the environment configuration while ensuring comparable performance with respect to other recent TAMP approaches in solving traditional, static problems. We release with this paper the open-source implementation of our method.
Robotic Arm Control and Task Training through Deep Reinforcement Learning
May 06, 2020

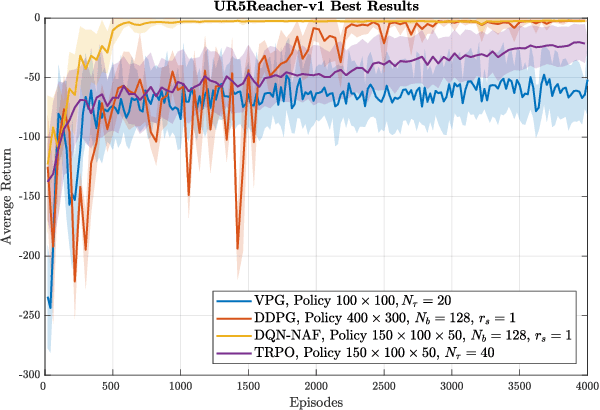
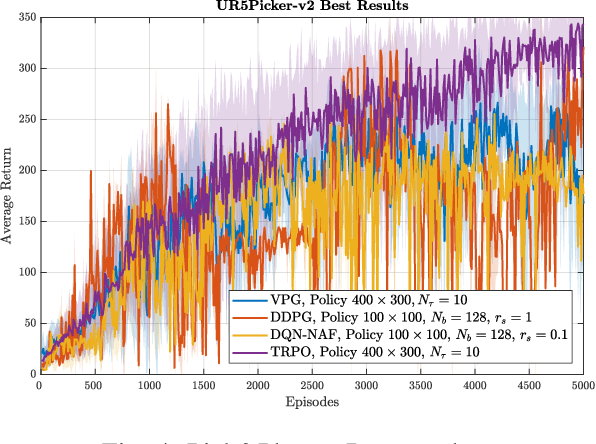
This paper proposes a detailed and extensive comparison of the Trust Region Policy Optimization and DeepQ-Network with Normalized Advantage Functions with respect to other state of the art algorithms, namely Deep Deterministic Policy Gradient and Vanilla Policy Gradient. Comparisons demonstrate that the former have better performances then the latter when asking robotic arms to accomplish manipulation tasks such as reaching a random target pose and pick &placing an object. Both simulated and real-world experiments are provided. Simulation lets us show the procedures that we adopted to precisely estimate the algorithms hyper-parameters and to correctly design good policies. Real-world experiments let show that our polices, if correctly trained on simulation, can be transferred and executed in a real environment with almost no changes.
Conditional Task and Motion Planning through an Effort-based Approach
Apr 18, 2018
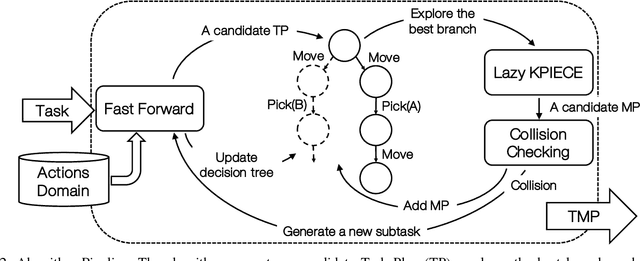
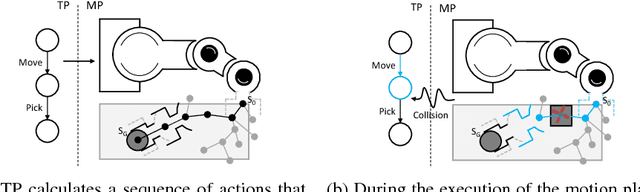
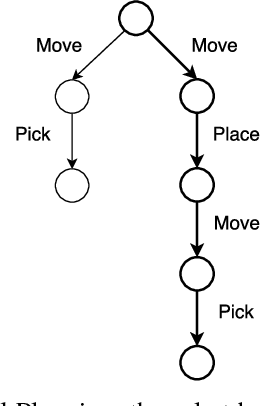
This paper proposes a preliminary work on a Conditional Task and Motion Planning algorithm able to find a plan that minimizes robot efforts while solving assigned tasks. Unlike most of the existing approaches that replan a path only when it becomes unfeasible (e.g., no collision-free paths exist), the proposed algorithm takes into consideration a replanning procedure whenever an effort-saving is possible. The effort is here considered as the execution time, but it is extensible to the robot energy consumption. The computed plan is both conditional and dynamically adaptable to the unexpected environmental changes. Based on the theoretical analysis of the algorithm, authors expect their proposal to be complete and scalable. In progress experiments aim to prove this investigation.
RUR53: an Unmanned Ground Vehicle for Navigation, Recognition and Manipulation
Nov 23, 2017
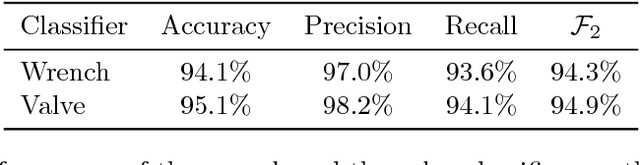
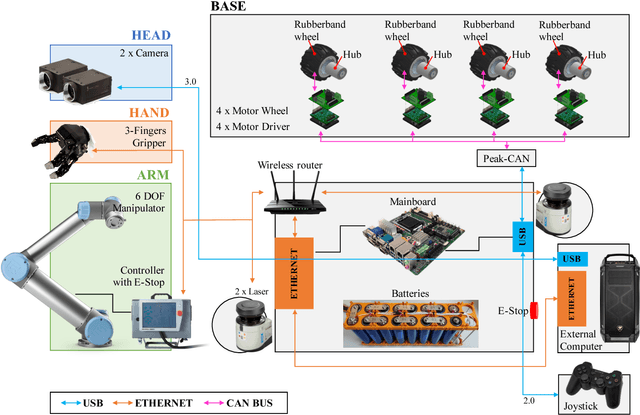
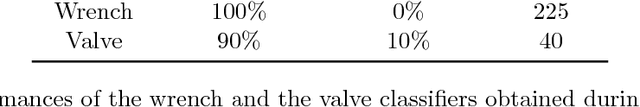
This paper describes RUR53, the unmanned mobile manipulator robot developed by the Desert Lion team of the University of Padova (Italy), and its experience in Challenge 2 and the Grand Challenge of the first Mohamed Bin Zayed International Robotics Challenge (Abu Dhabi, March 2017). According to the competition requirements, the robot is able to freely navigate inside an outdoor arena; locate and reach a panel; recognize and manipulate a wrench; use this wrench to physically operate a valve stem on the panel itself. RUR53 is able to perform these tasks both autonomously and in teleoperation mode. The paper details the adopted hardware and software architectures, focusing on its key aspects: modularity, generality, and the ability of exploiting sensor feedback. These features let the team rank third in the Gran Challenge in collaboration with the Czech Technical University in Prague, Czech Republic, the University of Pennsylvania, USA, and the University of Lincoln, UK. Tests performed both in the Challenge arena and in the lab are presented and discussed, focusing on the strengths and limitations of the proposed wrench and valve classification and recognition algorithms. Lessons learned are also detailed.