 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Multi-View Supervision for Surface Mapping Estimation
May 04, 2021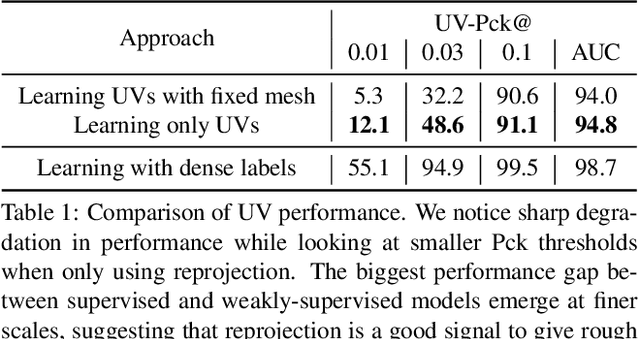
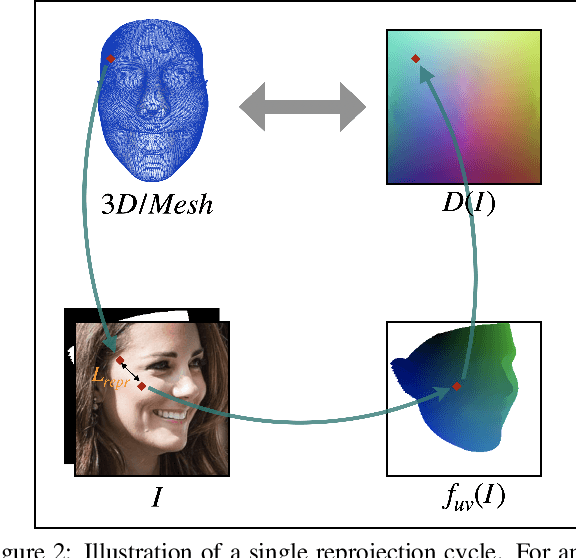
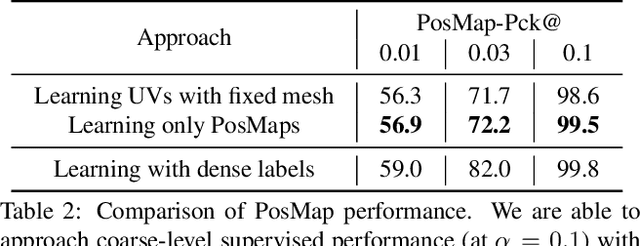

We propose a weakly-supervised multi-view learning approach to learn category-specific surface mapping without dense annotations. We learn the underlying surface geometry of common categories, such as human faces, cars, and airplanes, given instances from those categories. While traditional approaches solve this problem using extensive supervision in the form of pixel-level annotations, we take advantage of the fact that pixel-level UV and mesh predictions can be combined with 3D reprojections to form consistency cycles. As a result of exploiting these cycles, we can establish a dense correspondence mapping between image pixels and the mesh acting as a self-supervisory signal, which in turn helps improve our overall estimates. Our approach leverages information from multiple views of the object to establish additional consistency cycles, thus improving surface mapping understanding without the need for explicit annotations. We also propose the use of deformation fields for predictions of an instance specific mesh. Given the lack of datasets providing multiple images of similar object instances from different viewpoints, we generate and release a multi-view ShapeNet Cars and Airplanes dataset created by rendering ShapeNet meshes using a 360 degree camera trajectory around the mesh. For the human faces category, we process and adapt an existing dataset to a multi-view setup. Through experimental evaluations, we show that, at test time, our method can generate accurate variations away from the mean shape, is multi-view consistent, and performs comparably to fully supervised approaches.
RUR53: an Unmanned Ground Vehicle for Navigation, Recognition and Manipulation
Nov 23, 2017
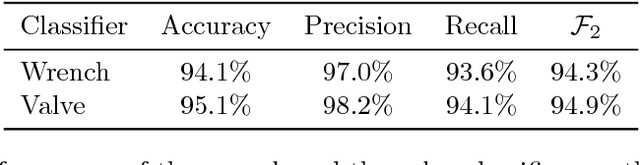
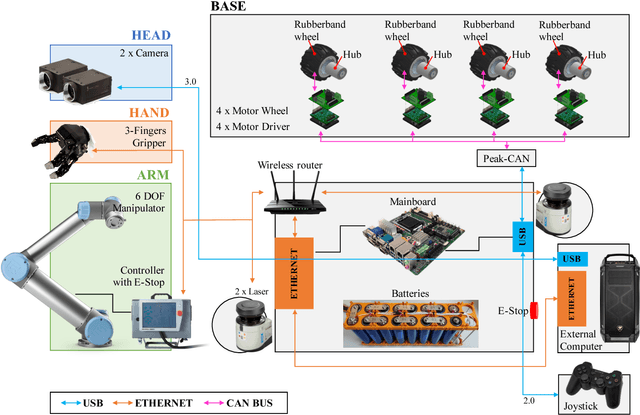
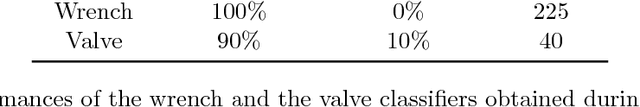
This paper describes RUR53, the unmanned mobile manipulator robot developed by the Desert Lion team of the University of Padova (Italy), and its experience in Challenge 2 and the Grand Challenge of the first Mohamed Bin Zayed International Robotics Challenge (Abu Dhabi, March 2017). According to the competition requirements, the robot is able to freely navigate inside an outdoor arena; locate and reach a panel; recognize and manipulate a wrench; use this wrench to physically operate a valve stem on the panel itself. RUR53 is able to perform these tasks both autonomously and in teleoperation mode. The paper details the adopted hardware and software architectures, focusing on its key aspects: modularity, generality, and the ability of exploiting sensor feedback. These features let the team rank third in the Gran Challenge in collaboration with the Czech Technical University in Prague, Czech Republic, the University of Pennsylvania, USA, and the University of Lincoln, UK. Tests performed both in the Challenge arena and in the lab are presented and discussed, focusing on the strengths and limitations of the proposed wrench and valve classification and recognition algorithms. Lessons learned are also detailed.
Real-time marker-less multi-person 3D pose estimation in RGB-Depth camera networks
Oct 17, 2017
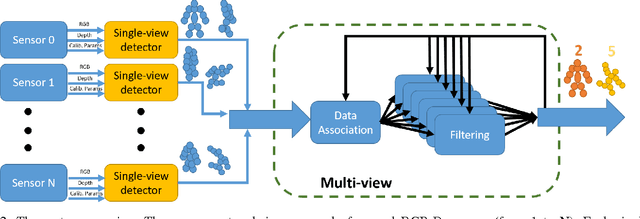


This paper proposes a novel system to estimate and track the 3D poses of multiple persons in calibrated RGB-Depth camera networks. The multi-view 3D pose of each person is computed by a central node which receives the single-view outcomes from each camera of the network. Each single-view outcome is computed by using a CNN for 2D pose estimation and extending the resulting skeletons to 3D by means of the sensor depth. The proposed system is marker-less, multi-person, independent of background and does not make any assumption on people appearance and initial pose. The system provides real-time outcomes, thus being perfectly suited for applications requiring user interaction. Experimental results show the effectiveness of this work with respect to a baseline multi-view approach in different scenarios. To foster research and applications based on this work, we released the source code in OpenPTrack, an open source project for RGB-D people tracking.