 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Transmittance for Efficient Rendering of Reflectance Fields
Oct 25, 2021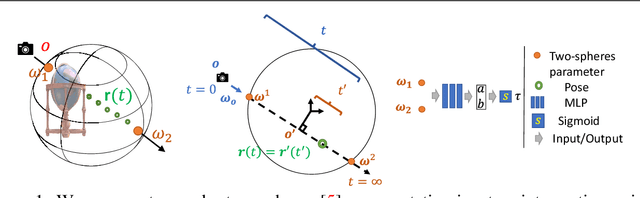
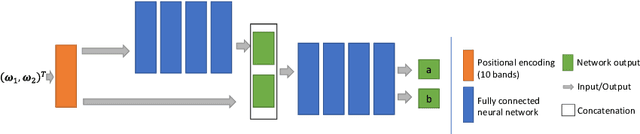
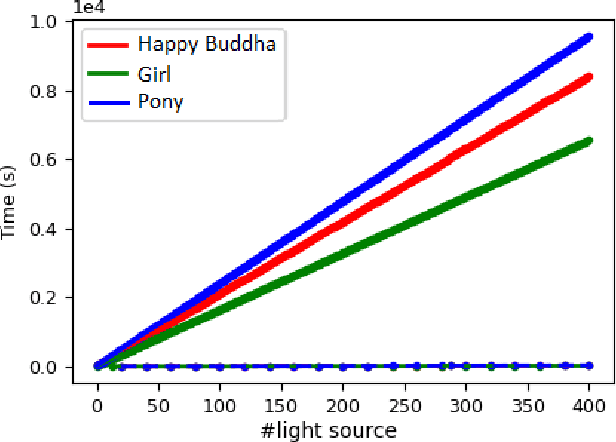
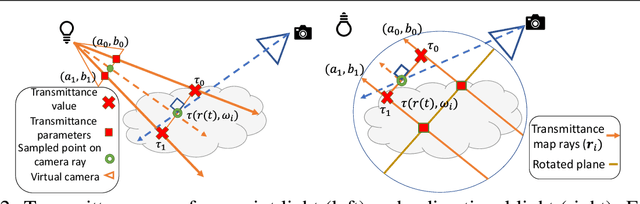
Recently neural volumetric representations such as neural reflectance fields have been widely applied to faithfully reproduce the appearance of real-world objects and scenes under novel viewpoints and lighting conditions. However, it remains challenging and time-consuming to render such representations under complex lighting such as environment maps, which requires individual ray marching towards each single light to calculate the transmittance at every sampled point. In this paper, we propose a novel method based on precomputed Neural Transmittance Functions to accelerate the rendering of neural reflectance fields. Our neural transmittance functions enable us to efficiently query the transmittance at an arbitrary point in space along an arbitrary ray without tedious ray marching, which effectively reduces the time-complexity of the rendering. We propose a novel formulation for the neural transmittance function, and train it jointly with the neural reflectance fields on images captured under collocated camera and light, while enforcing monotonicity. Results on real and synthetic scenes demonstrate almost two order of magnitude speedup for renderings under environment maps with minimal accuracy loss.
Weak Multi-View Supervision for Surface Mapping Estimation
May 04, 2021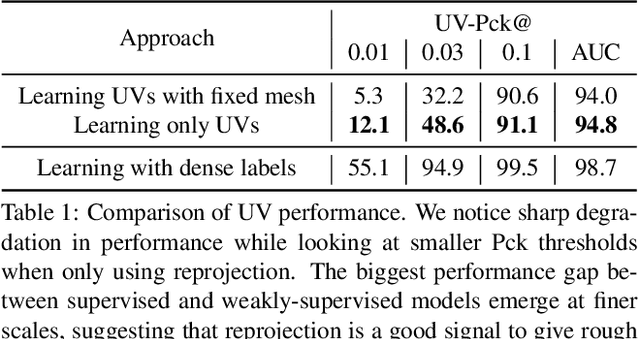
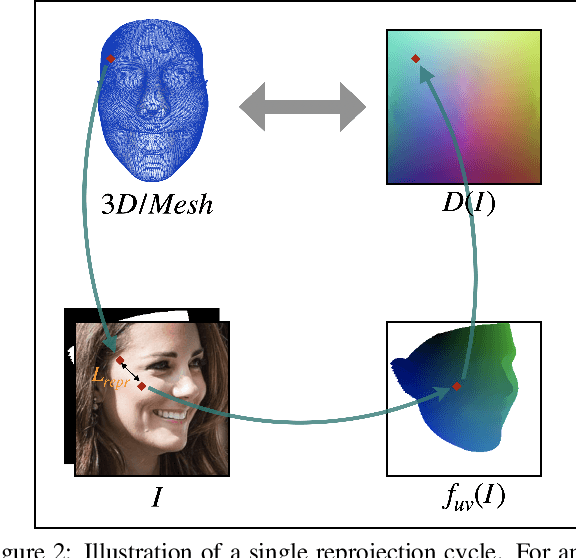
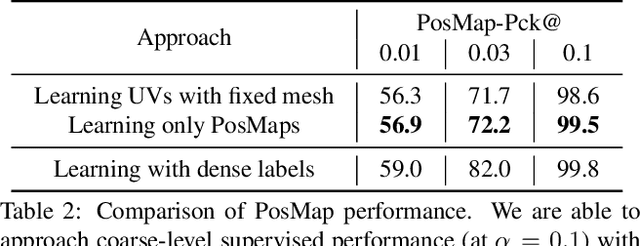

We propose a weakly-supervised multi-view learning approach to learn category-specific surface mapping without dense annotations. We learn the underlying surface geometry of common categories, such as human faces, cars, and airplanes, given instances from those categories. While traditional approaches solve this problem using extensive supervision in the form of pixel-level annotations, we take advantage of the fact that pixel-level UV and mesh predictions can be combined with 3D reprojections to form consistency cycles. As a result of exploiting these cycles, we can establish a dense correspondence mapping between image pixels and the mesh acting as a self-supervisory signal, which in turn helps improve our overall estimates. Our approach leverages information from multiple views of the object to establish additional consistency cycles, thus improving surface mapping understanding without the need for explicit annotations. We also propose the use of deformation fields for predictions of an instance specific mesh. Given the lack of datasets providing multiple images of similar object instances from different viewpoints, we generate and release a multi-view ShapeNet Cars and Airplanes dataset created by rendering ShapeNet meshes using a 360 degree camera trajectory around the mesh. For the human faces category, we process and adapt an existing dataset to a multi-view setup. Through experimental evaluations, we show that, at test time, our method can generate accurate variations away from the mean shape, is multi-view consistent, and performs comparably to fully supervised approaches.