 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Transmittance for Efficient Rendering of Reflectance Fields
Oct 25, 2021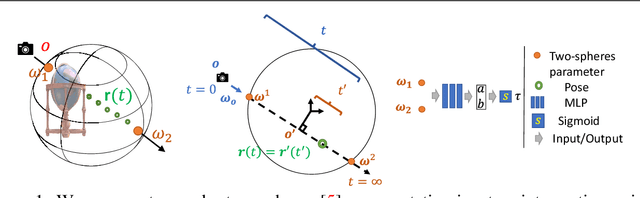
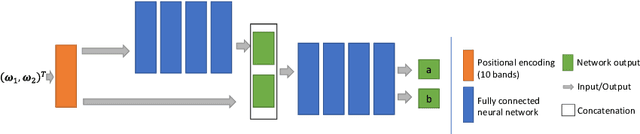
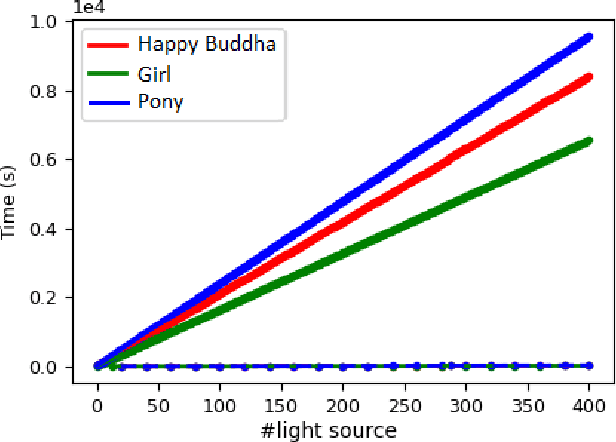
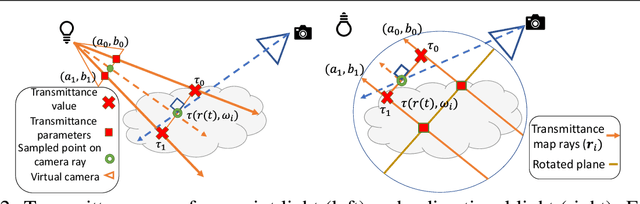
Recently neural volumetric representations such as neural reflectance fields have been widely applied to faithfully reproduce the appearance of real-world objects and scenes under novel viewpoints and lighting conditions. However, it remains challenging and time-consuming to render such representations under complex lighting such as environment maps, which requires individual ray marching towards each single light to calculate the transmittance at every sampled point. In this paper, we propose a novel method based on precomputed Neural Transmittance Functions to accelerate the rendering of neural reflectance fields. Our neural transmittance functions enable us to efficiently query the transmittance at an arbitrary point in space along an arbitrary ray without tedious ray marching, which effectively reduces the time-complexity of the rendering. We propose a novel formulation for the neural transmittance function, and train it jointly with the neural reflectance fields on images captured under collocated camera and light, while enforcing monotonicity. Results on real and synthetic scenes demonstrate almost two order of magnitude speedup for renderings under environment maps with minimal accuracy loss.
Live Illumination Decomposition of Videos
Aug 06, 2019
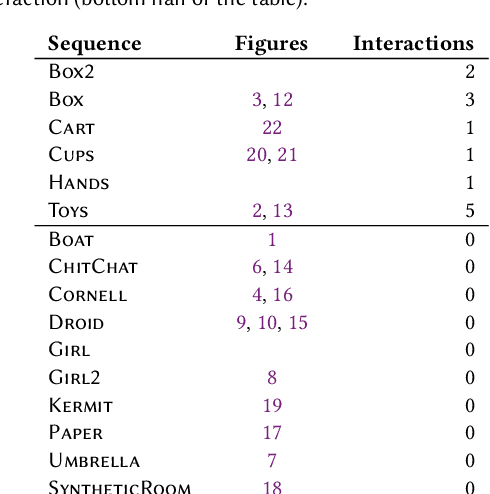
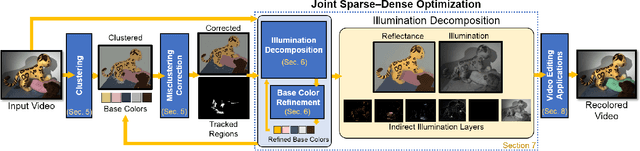
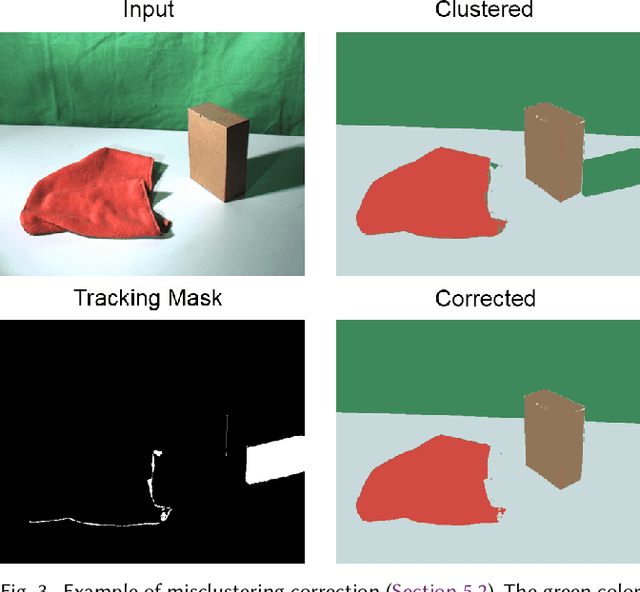
We propose the first approach for the decomposition of a monocular color video into direct and indirect illumination components in real-time. We retrieve, in separate layers, the contribution made to the scene appearance by the scene reflectance, the light sources and the reflections from various coherent scene regions to one another. Existing techniques that invert global light transport require image capture under multiplexed controlled lighting, or only enable the decomposition of a single image at slow off-line frame rates. In contrast, our approach works for regular videos and produces temporally coherent decomposition layers at real-time frame rates. At the core of our approach are several sparsity priors that enable the estimation of the per-pixel direct and indirect illumination layers based on a small set of jointly estimated base reflectance colors. The resulting variational decomposition problem uses a new formulation based on sparse and dense sets of non-linear equations that we solve efficiently using a novel alternating data-parallel optimization strategy. We evaluate our approach qualitatively and quantitatively, and show improvements over the state of the art in this field, in both quality and runtime. In addition, we demonstrate various real-time appearance editing applications for videos with consistent illumination.
Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF from a Single Image
May 07, 2019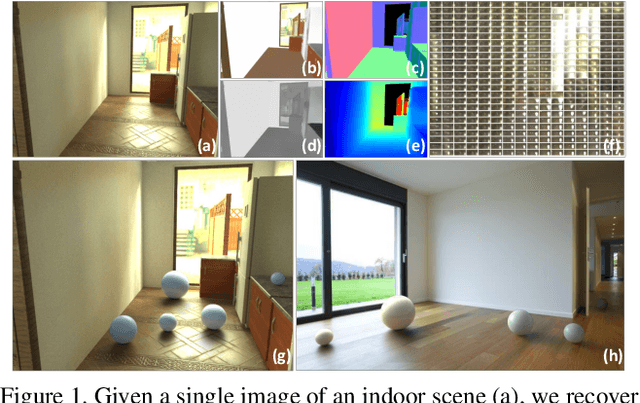


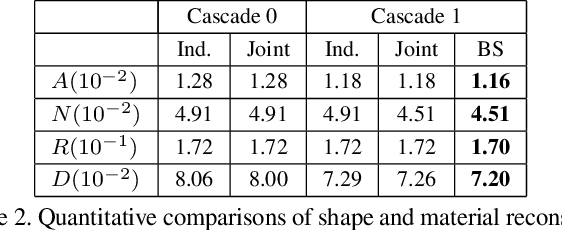
We propose a deep inverse rendering framework for indoor scenes. From a single RGB image of an arbitrary indoor scene, we create a complete scene reconstruction, estimating shape, spatially-varying lighting, and spatially-varying, non-Lambertian surface reflectance. To train this network, we augment the SUNCG indoor scene dataset with real-world materials and render them with a fast, high-quality, physically-based GPU renderer to create a large-scale, photorealistic indoor dataset. Our inverse rendering network incorporates physical insights -- including a spatially-varying spherical Gaussian lighting representation, a differentiable rendering layer to model scene appearance, a cascade structure to iteratively refine the predictions and a bilateral solver for refinement -- allowing us to jointly reason about shape, lighting, and reflectance. Experiments show that our framework outperforms previous methods for estimating individual scene components, which also enables various novel applications for augmented reality, such as photorealistic object insertion and material editing. Code and data will be made publicly available.
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
May 03, 2017
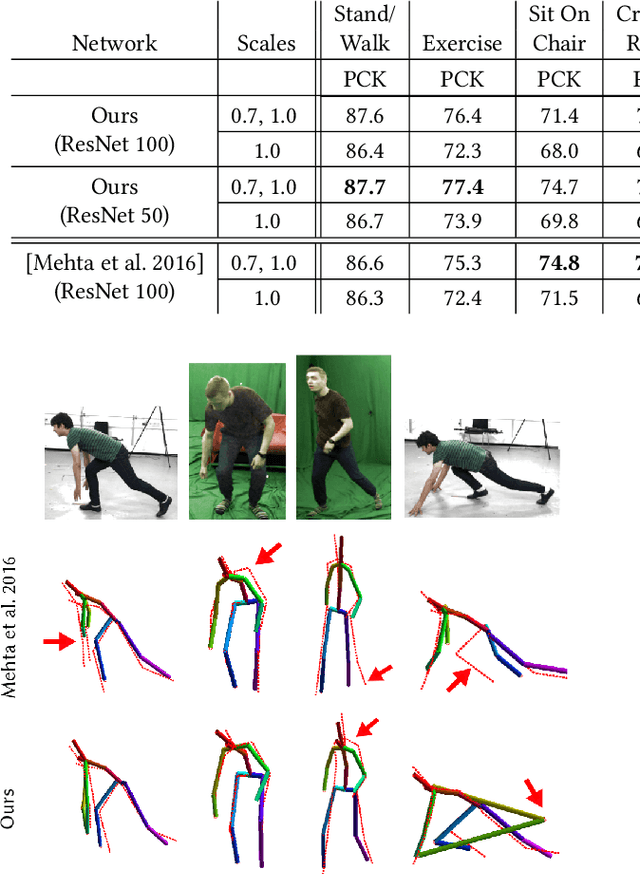

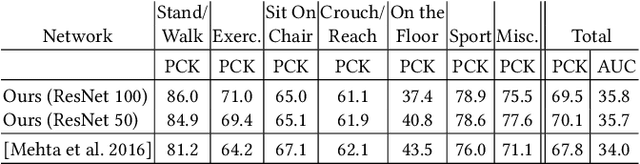
We present the first real-time method to capture the full global 3D skeletal pose of a human in a stable, temporally consistent manner using a single RGB camera. Our method combines a new convolutional neural network (CNN) based pose regressor with kinematic skeleton fitting. Our novel fully-convolutional pose formulation regresses 2D and 3D joint positions jointly in real time and does not require tightly cropped input frames. A real-time kinematic skeleton fitting method uses the CNN output to yield temporally stable 3D global pose reconstructions on the basis of a coherent kinematic skeleton. This makes our approach the first monocular RGB method usable in real-time applications such as 3D character control---thus far, the only monocular methods for such applications employed specialized RGB-D cameras. Our method's accuracy is quantitatively on par with the best offline 3D monocular RGB pose estimation methods. Our results are qualitatively comparable to, and sometimes better than, results from monocular RGB-D approaches, such as the Kinect. However, we show that our approach is more broadly applicable than RGB-D solutions, i.e. it works for outdoor scenes, community videos, and low quality commodity RGB cameras.
EgoCap: Egocentric Marker-less Motion Capture with Two Fisheye Cameras (Extended Abstract)
Dec 31, 2016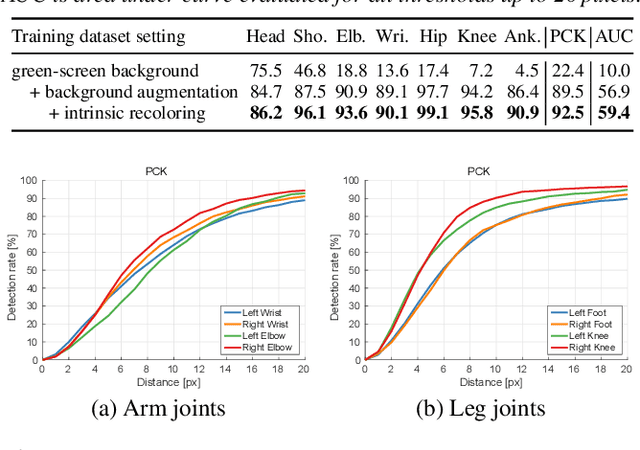
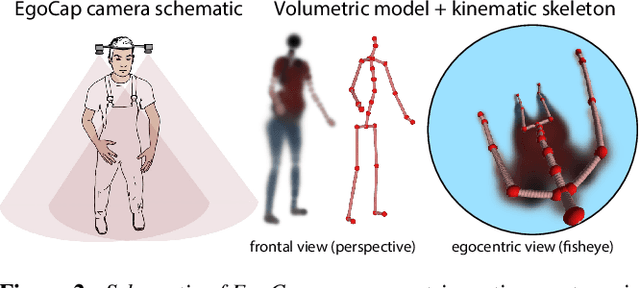
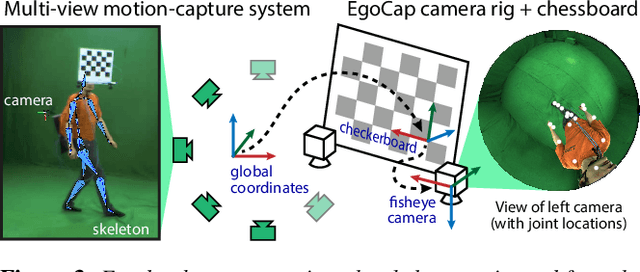
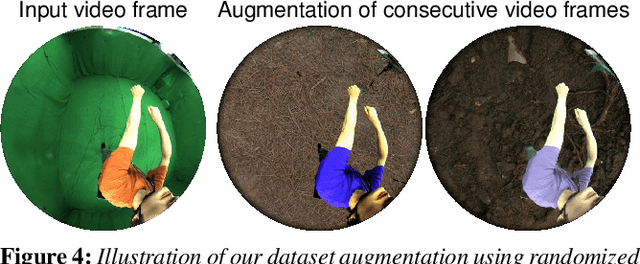
Marker-based and marker-less optical skeletal motion-capture methods use an outside-in arrangement of cameras placed around a scene, with viewpoints converging on the center. They often create discomfort by possibly needed marker suits, and their recording volume is severely restricted and often constrained to indoor scenes with controlled backgrounds. We therefore propose a new method for real-time, marker-less and egocentric motion capture which estimates the full-body skeleton pose from a lightweight stereo pair of fisheye cameras that are attached to a helmet or virtual-reality headset. It combines the strength of a new generative pose estimation framework for fisheye views with a ConvNet-based body-part detector trained on a new automatically annotated and augmented dataset. Our inside-in method captures full-body motion in general indoor and outdoor scenes, and also crowded scenes.
EgoCap: Egocentric Marker-less Motion Capture with Two Fisheye Cameras
Sep 23, 2016Marker-based and marker-less optical skeletal motion-capture methods use an outside-in arrangement of cameras placed around a scene, with viewpoints converging on the center. They often create discomfort by possibly needed marker suits, and their recording volume is severely restricted and often constrained to indoor scenes with controlled backgrounds. Alternative suit-based systems use several inertial measurement units or an exoskeleton to capture motion. This makes capturing independent of a confined volume, but requires substantial, often constraining, and hard to set up body instrumentation. We therefore propose a new method for real-time, marker-less and egocentric motion capture which estimates the full-body skeleton pose from a lightweight stereo pair of fisheye cameras that are attached to a helmet or virtual reality headset. It combines the strength of a new generative pose estimation framework for fisheye views with a ConvNet-based body-part detector trained on a large new dataset. Our inside-in method captures full-body motion in general indoor and outdoor scenes, and also crowded scenes with many people in close vicinity. The captured user can freely move around, which enables reconstruction of larger-scale activities and is particularly useful in virtual reality to freely roam and interact, while seeing the fully motion-captured virtual body.