 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB2Hands: Real-Time Tracking of 3D Hand Interactions from Monocular RGB Video
Jun 22, 2021

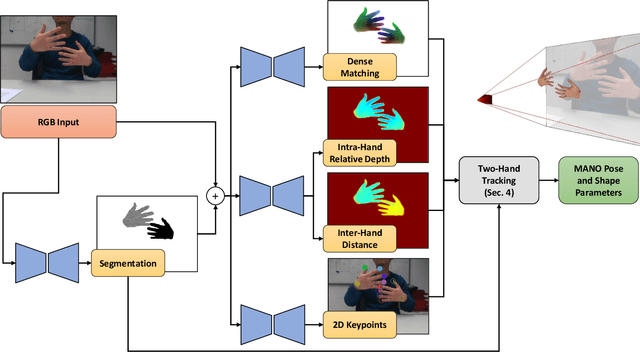
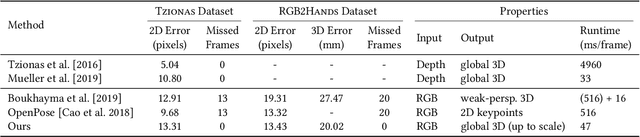
Tracking and reconstructing the 3D pose and geometry of two hands in interaction is a challenging problem that has a high relevance for several human-computer interaction applications, including AR/VR, robotics, or sign language recognition. Existing works are either limited to simpler tracking settings (e.g., considering only a single hand or two spatially separated hands), or rely on less ubiquitous sensors, such as depth cameras. In contrast, in this work we present the first real-time method for motion capture of skeletal pose and 3D surface geometry of hands from a single RGB camera that explicitly considers close interactions. In order to address the inherent depth ambiguities in RGB data, we propose a novel multi-task CNN that regresses multiple complementary pieces of information, including segmentation, dense matchings to a 3D hand model, and 2D keypoint positions, together with newly proposed intra-hand relative depth and inter-hand distance maps. These predictions are subsequently used in a generative model fitting framework in order to estimate pose and shape parameters of a 3D hand model for both hands. We experimentally verify the individual components of our RGB two-hand tracking and 3D reconstruction pipeline through an extensive ablation study. Moreover, we demonstrate that our approach offers previously unseen two-hand tracking performance from RGB, and quantitatively and qualitatively outperforms existing RGB-based methods that were not explicitly designed for two-hand interactions. Moreover, our method even performs on-par with depth-based real-time methods.
* SIGGRAPH Asia 2020
Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
Jun 15, 2021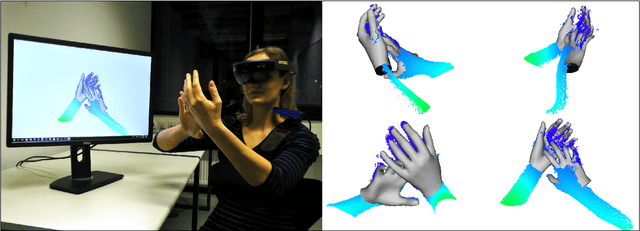

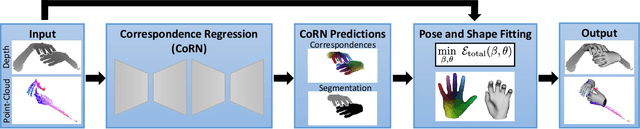

We present a novel method for real-time pose and shape reconstruction of two strongly interacting hands. Our approach is the first two-hand tracking solution that combines an extensive list of favorable properties, namely it is marker-less, uses a single consumer-level depth camera, runs in real time, handles inter- and intra-hand collisions, and automatically adjusts to the user's hand shape. In order to achieve this, we embed a recent parametric hand pose and shape model and a dense correspondence predictor based on a deep neural network into a suitable energy minimization framework. For training the correspondence prediction network, we synthesize a two-hand dataset based on physical simulations that includes both hand pose and shape annotations while at the same time avoiding inter-hand penetrations. To achieve real-time rates, we phrase the model fitting in terms of a nonlinear least-squares problem so that the energy can be optimized based on a highly efficient GPU-based Gauss-Newton optimizer. We show state-of-the-art results in scenes that exceed the complexity level demonstrated by previous work, including tight two-hand grasps, significant inter-hand occlusions, and gesture interaction.
XNect: Real-time Multi-person 3D Human Pose Estimation with a Single RGB Camera
Jul 01, 2019
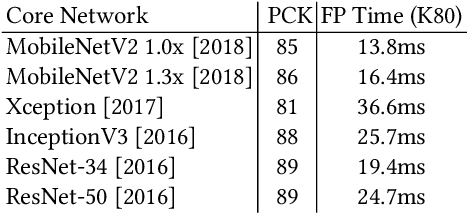
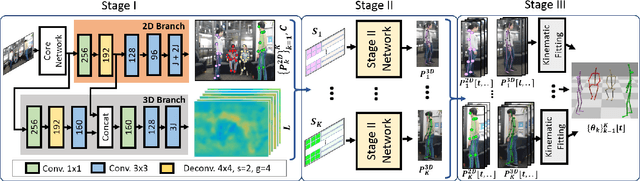
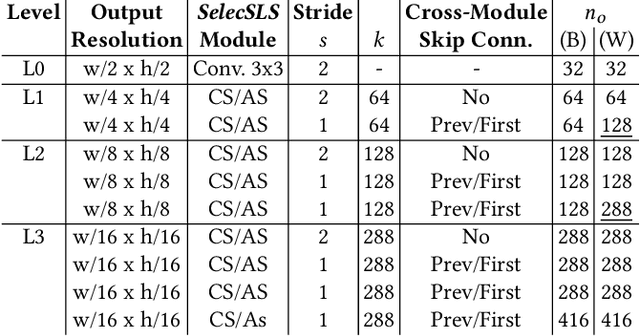
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates in generic scenes and is robust to difficult occlusions both by other people and objects. Our method operates in subsequent stages. The first stage is a convolutional neural network (CNN) that estimates 2D and 3D pose features along with identity assignments for all visible joints of all individuals. We contribute a new architecture for this CNN, called SelecSLS Net, that uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy. In the second stage, a fully-connected neural network turns the possibly partial (on account of occlusion) 2D pose and 3D pose features for each subject into a complete 3D pose estimate per individual. The third stage applies space-time skeletal model fitting to the predicted 2D and 3D pose per subject to further reconcile the 2D and 3D pose, and enforce temporal coherence. Our method returns the full skeletal pose in joint angles for each subject. This is a further key distinction from previous work that neither extracted global body positions nor joint angle results of a coherent skeleton in real time for multi-person scenes. The proposed system runs on consumer hardware at a previously unseen speed of more than 30 fps given 512x320 images as input while achieving state-of-the-art accuracy, which we will demonstrate on a range of challenging real-world scenes.
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB
Aug 28, 2018
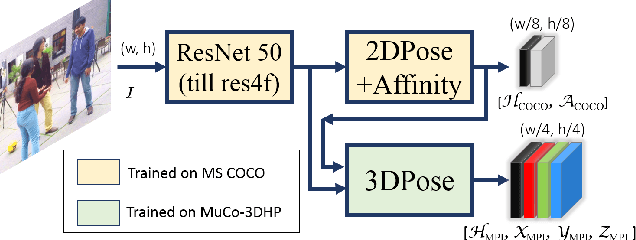

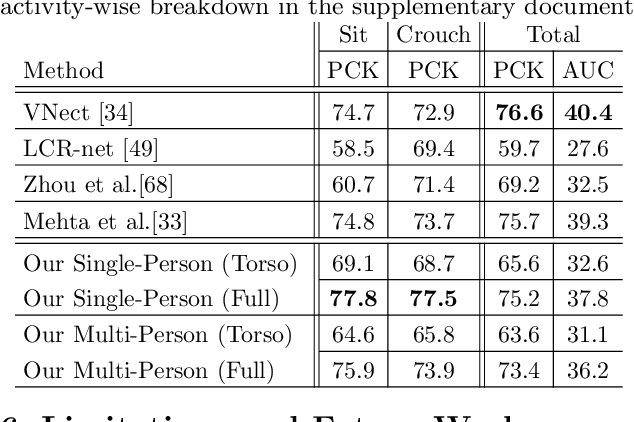
We propose a new single-shot method for multi-person 3D pose estimation in general scenes from a monocular RGB camera. Our approach uses novel occlusion-robust pose-maps (ORPM) which enable full body pose inference even under strong partial occlusions by other people and objects in the scene. ORPM outputs a fixed number of maps which encode the 3D joint locations of all people in the scene. Body part associations allow us to infer 3D pose for an arbitrary number of people without explicit bounding box prediction. To train our approach we introduce MuCo-3DHP, the first large scale training data set showing real images of sophisticated multi-person interactions and occlusions. We synthesize a large corpus of multi-person images by compositing images of individual people (with ground truth from mutli-view performance capture). We evaluate our method on our new challenging 3D annotated multi-person test set MuPoTs-3D where we achieve state-of-the-art performance. To further stimulate research in multi-person 3D pose estimation, we will make our new datasets, and associated code publicly available for research purposes.
GANerated Hands for Real-time 3D Hand Tracking from Monocular RGB
Dec 04, 2017
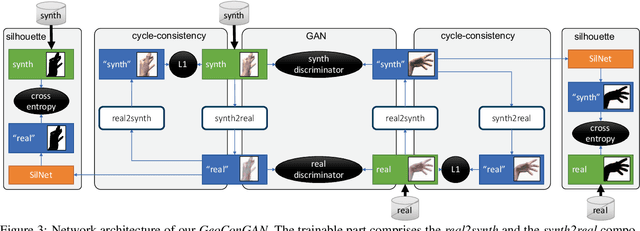


We address the highly challenging problem of real-time 3D hand tracking based on a monocular RGB-only sequence. Our tracking method combines a convolutional neural network with a kinematic 3D hand model, such that it generalizes well to unseen data, is robust to occlusions and varying camera viewpoints, and leads to anatomically plausible as well as temporally smooth hand motions. For training our CNN we propose a novel approach for the synthetic generation of training data that is based on a geometrically consistent image-to-image translation network. To be more specific, we use a neural network that translates synthetic images to "real" images, such that the so-generated images follow the same statistical distribution as real-world hand images. For training this translation network we combine an adversarial loss and a cycle-consistency loss with a geometric consistency loss in order to preserve geometric properties (such as hand pose) during translation. We demonstrate that our hand tracking system outperforms the current state-of-the-art on challenging RGB-only footage.
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor
Oct 05, 2017
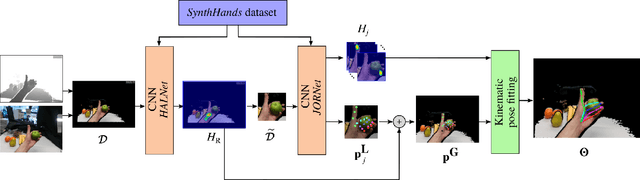


We present an approach for real-time, robust and accurate hand pose estimation from moving egocentric RGB-D cameras in cluttered real environments. Existing methods typically fail for hand-object interactions in cluttered scenes imaged from egocentric viewpoints, common for virtual or augmented reality applications. Our approach uses two subsequently applied Convolutional Neural Networks (CNNs) to localize the hand and regress 3D joint locations. Hand localization is achieved by using a CNN to estimate the 2D position of the hand center in the input, even in the presence of clutter and occlusions. The localized hand position, together with the corresponding input depth value, is used to generate a normalized cropped image that is fed into a second CNN to regress relative 3D hand joint locations in real time. For added accuracy, robustness and temporal stability, we refine the pose estimates using a kinematic pose tracking energy. To train the CNNs, we introduce a new photorealistic dataset that uses a merged reality approach to capture and synthesize large amounts of annotated data of natural hand interaction in cluttered scenes. Through quantitative and qualitative evaluation, we show that our method is robust to self-occlusion and occlusions by objects, particularly in moving egocentric perspectives.
Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision
Oct 04, 2017
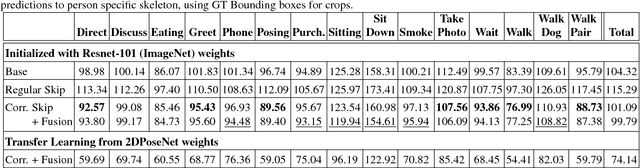
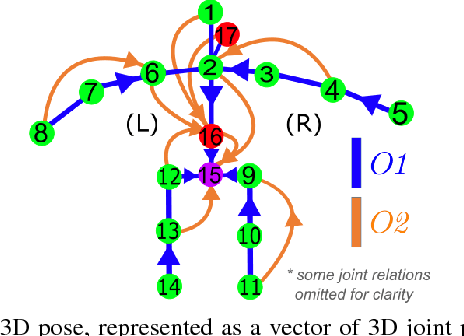
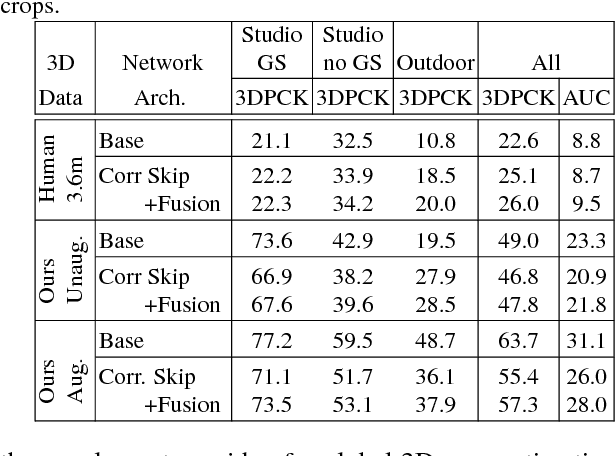
We propose a CNN-based approach for 3D human body pose estimation from single RGB images that addresses the issue of limited generalizability of models trained solely on the starkly limited publicly available 3D pose data. Using only the existing 3D pose data and 2D pose data, we show state-of-the-art performance on established benchmarks through transfer of learned features, while also generalizing to in-the-wild scenes. We further introduce a new training set for human body pose estimation from monocular images of real humans that has the ground truth captured with a multi-camera marker-less motion capture system. It complements existing corpora with greater diversity in pose, human appearance, clothing, occlusion, and viewpoints, and enables an increased scope of augmentation. We also contribute a new benchmark that covers outdoor and indoor scenes, and demonstrate that our 3D pose dataset shows better in-the-wild performance than existing annotated data, which is further improved in conjunction with transfer learning from 2D pose data. All in all, we argue that the use of transfer learning of representations in tandem with algorithmic and data contributions is crucial for general 3D body pose estimation.
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
May 03, 2017
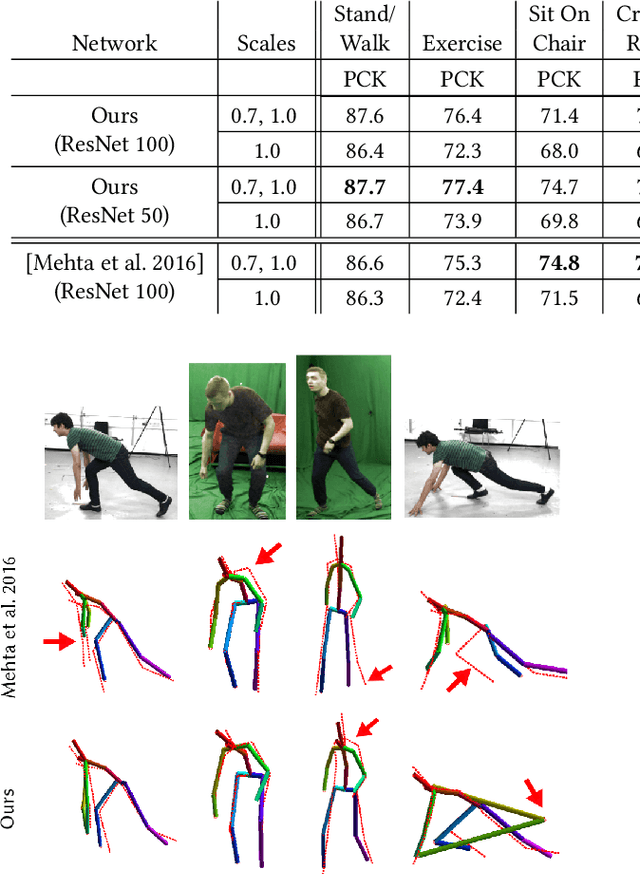

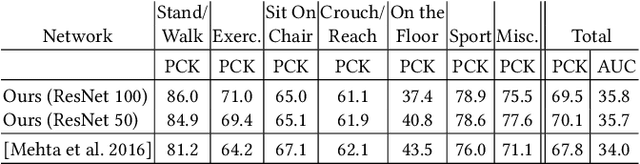
We present the first real-time method to capture the full global 3D skeletal pose of a human in a stable, temporally consistent manner using a single RGB camera. Our method combines a new convolutional neural network (CNN) based pose regressor with kinematic skeleton fitting. Our novel fully-convolutional pose formulation regresses 2D and 3D joint positions jointly in real time and does not require tightly cropped input frames. A real-time kinematic skeleton fitting method uses the CNN output to yield temporally stable 3D global pose reconstructions on the basis of a coherent kinematic skeleton. This makes our approach the first monocular RGB method usable in real-time applications such as 3D character control---thus far, the only monocular methods for such applications employed specialized RGB-D cameras. Our method's accuracy is quantitatively on par with the best offline 3D monocular RGB pose estimation methods. Our results are qualitatively comparable to, and sometimes better than, results from monocular RGB-D approaches, such as the Kinect. However, we show that our approach is more broadly applicable than RGB-D solutions, i.e. it works for outdoor scenes, community videos, and low quality commodity RGB cameras.