 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Unscented Autoencoders for Trajectory Prediction
Oct 30, 2023



The \ac{CVAE} is one of the most widely-used models in trajectory prediction for \ac{AD}. It captures the interplay between a driving context and its ground-truth future into a probabilistic latent space and uses it to produce predictions. In this paper, we challenge key components of the CVAE. We leverage recent advances in the space of the VAE, the foundation of the CVAE, which show that a simple change in the sampling procedure can greatly benefit performance. We find that unscented sampling, which draws samples from any learned distribution in a deterministic manner, can naturally be better suited to trajectory prediction than potentially dangerous random sampling. We go further and offer additional improvements, including a more structured mixture latent space, as well as a novel, potentially more expressive way to do inference with CVAEs. We show wide applicability of our models by evaluating them on the INTERACTION prediction dataset, outperforming the state of the art, as well as at the task of image modeling on the CelebA dataset, outperforming the baseline vanilla CVAE. Code is available at https://github.com/boschresearch/cuae-prediction.
Unscented Autoencoder
Jun 08, 2023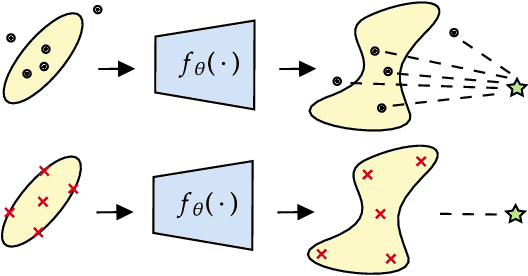



The Variational Autoencoder (VAE) is a seminal approach in deep generative modeling with latent variables. Interpreting its reconstruction process as a nonlinear transformation of samples from the latent posterior distribution, we apply the Unscented Transform (UT) -- a well-known distribution approximation used in the Unscented Kalman Filter (UKF) from the field of filtering. A finite set of statistics called sigma points, sampled deterministically, provides a more informative and lower-variance posterior representation than the ubiquitous noise-scaling of the reparameterization trick, while ensuring higher-quality reconstruction. We further boost the performance by replacing the Kullback-Leibler (KL) divergence with the Wasserstein distribution metric that allows for a sharper posterior. Inspired by the two components, we derive a novel, deterministic-sampling flavor of the VAE, the Unscented Autoencoder (UAE), trained purely with regularization-like terms on the per-sample posterior. We empirically show competitive performance in Fr\'echet Inception Distance (FID) scores over closely-related models, in addition to a lower training variance than the VAE.
Bridging the Gap Between Multi-Step and One-Shot Trajectory Prediction via Self-Supervision
Jun 06, 2023



Accurate vehicle trajectory prediction is an unsolved problem in autonomous driving with various open research questions. State-of-the-art approaches regress trajectories either in a one-shot or step-wise manner. Although one-shot approaches are usually preferred for their simplicity, they relinquish powerful self-supervision schemes that can be constructed by chaining multiple time-steps. We address this issue by proposing a middle-ground where multiple trajectory segments are chained together. Our proposed Multi-Branch Self-Supervised Predictor receives additional training on new predictions starting at intermediate future segments. In addition, the model 'imagines' the latent context and 'predicts the past' while combining multi-modal trajectories in a tree-like manner. We deliberately keep aspects such as interaction and environment modeling simplistic and nevertheless achieve competitive results on the INTERACTION dataset. Furthermore, we investigate the sparsely explored uncertainty estimation of deterministic predictors. We find positive correlations between the prediction error and two proposed metrics, which might pave way for determining prediction confidence.
Scaling Planning for Automated Driving using Simplistic Synthetic Data
May 30, 2023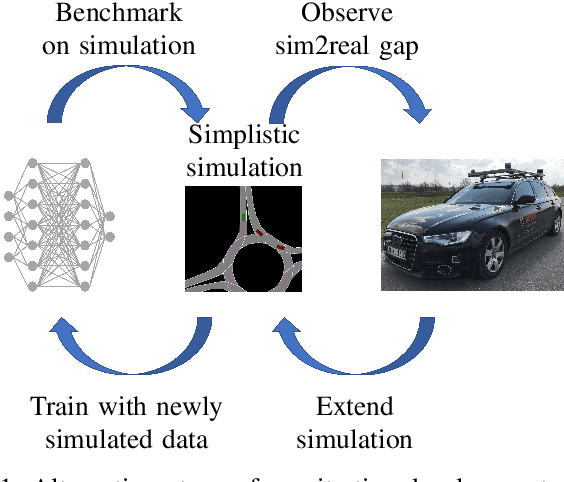
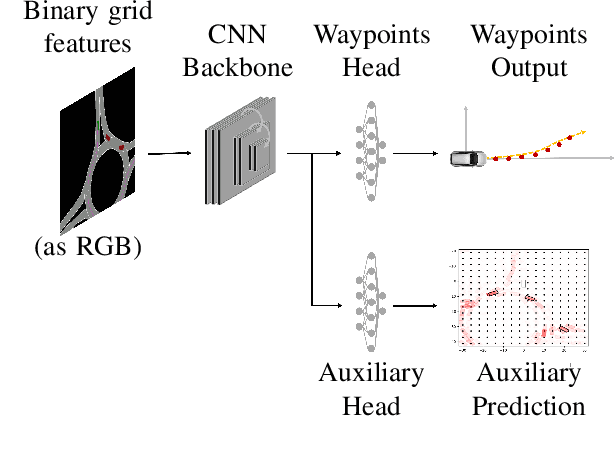


We challenge the perceived consensus that the application of deep learning to solve the automated driving planning task requires a huge amount of real-world data or a realistic simulator. Using a roundabout scenario, we show that this requirement can be relaxed in favour of targeted, simplistic simulated data. A benefit is that such data can be easily generated for critical scenarios that are typically underrepresented in realistic datasets. By applying vanilla behavioural cloning almost exclusively to lightweight simulated data, we achieve reliable and comfortable real-world driving. Our key insight lies in an incremental development approach that includes regular in-vehicle testing to identify sim-to-real gaps, targeted data augmentation, and training scenario variations. In addition to the methodology, we offer practical guidelines for deploying such a policy within a real-world vehicle, along with insights of the resulting qualitative driving behaviour. This approach serves as a blueprint for many automated driving use cases, providing valuable insights for future research and helping develop efficient and effective solutions.
StarNet: Joint Action-Space Prediction with Star Graphs and Implicit Global Frame Self-Attention
Nov 26, 2021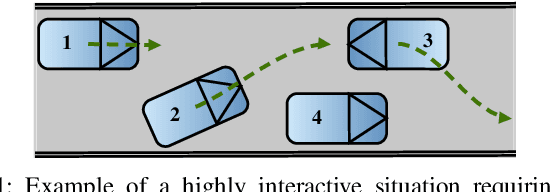
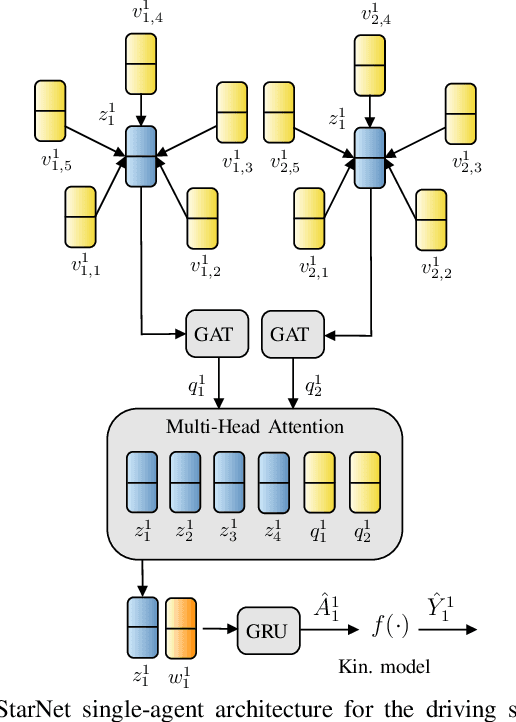

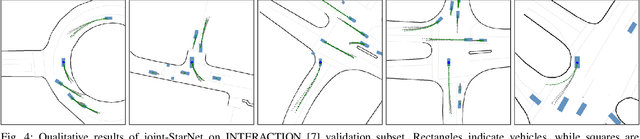
In this work, we present a novel multi-modal multi-agent trajectory prediction architecture, focusing on map and interaction modeling using graph representation. For the purposes of map modeling, we capture rich topological structure into vector-based star graphs, which enable an agent to directly attend to relevant regions along polylines that are used to represent the map. We denote this architecture StarNet, and integrate it in a single-agent prediction setting. As the main result, we extend this architecture to joint scene-level prediction, which produces multiple agents' predictions simultaneously. The key idea in joint-StarNet is integrating the awareness of one agent in its own reference frame with how it is perceived from the points of view of other agents. We achieve this via masked self-attention. Both proposed architectures are built on top of the action-space prediction framework introduced in our previous work, which ensures kinematically feasible trajectory predictions. We evaluate the methods on the interaction-rich inD and INTERACTION datasets, with both StarNet and joint-StarNet achieving improvements over state of the art.
Self-Supervised Action-Space Prediction for Automated Driving
Sep 21, 2021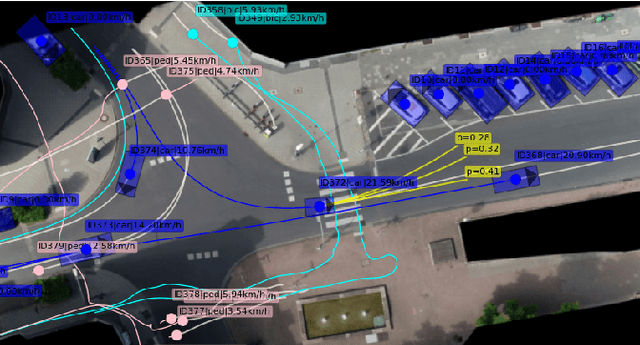
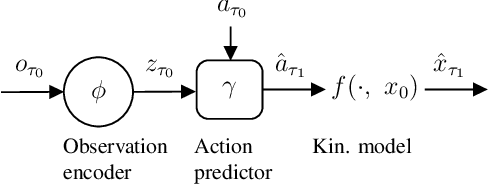
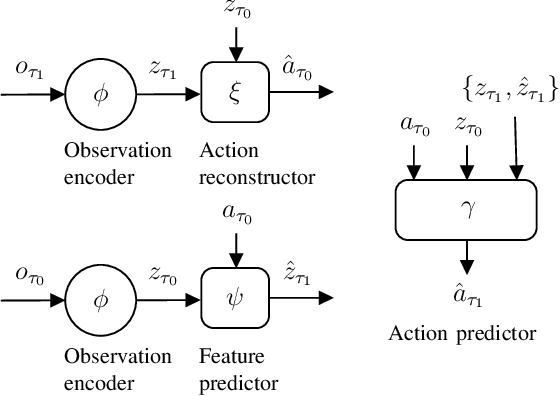
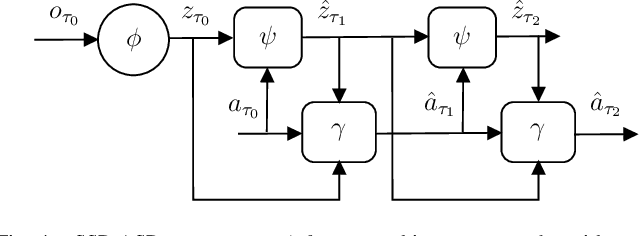
Making informed driving decisions requires reliable prediction of other vehicles' trajectories. In this paper, we present a novel learned multi-modal trajectory prediction architecture for automated driving. It achieves kinematically feasible predictions by casting the learning problem into the space of accelerations and steering angles -- by performing action-space prediction, we can leverage valuable model knowledge. Additionally, the dimensionality of the action manifold is lower than that of the state manifold, whose intrinsically correlated states are more difficult to capture in a learned manner. For the purpose of action-space prediction, we present the simple Feed-Forward Action-Space Prediction (FFW-ASP) architecture. Then, we build on this notion and introduce the novel Self-Supervised Action-Space Prediction (SSP-ASP) architecture that outputs future environment context features in addition to trajectories. A key element in the self-supervised architecture is that, based on an observed action history and past context features, future context features are predicted prior to future trajectories. The proposed methods are evaluated on real-world datasets containing urban intersections and roundabouts, and show accurate predictions, outperforming state-of-the-art for kinematically feasible predictions in several prediction metrics.
Where can I drive? Deep Ego-Corridor Estimation for Robust Automated Driving
Apr 16, 2020


Lane detection is an essential part of the perception module of any automated driving (AD) or advanced driver assistance system (ADAS). So far, model-driven approaches for the detection of lane markings proved sufficient. More recently, however data-driven approaches have been proposed that show superior results. These deep learning approaches typically propose a classification of the free-space using for example semantic segmentation. While these examples focus and optimize on unmarked inner-city roads, we believe that mapless driving in complex highway scenarios is still not handled with sufficient robustness and availability. Especially in challenging weather situations such as heavy rain, fog at night or reflections in puddles, the reliable detection of lane markings will decrease significantly or completely fail with low-cost video-only AD systems. Therefore, we propose to specifically classify a drivable corridor in the ego-lane on a pixel level with a deep learning approach. Our approach is intentionally kept simple with only 660k parameters. Thus, we were able to easily integrate our algorithm into an online AD system of a test vehicle. We demonstrate the performance of our approach under challenging conditions qualitatively and quantitatively in comparison to a state-of-the-art model-driven approach. We see the current approach as a fallback method whenever a model-driven approach cannot cope with a specific scenario. Due to this, a fallback method does not have to fulfill the same requirements on comfort in lateral control as the primary algorithm: Its task is to catch the temporal shortcomings of the main perception task.