 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabels Are Not Perfect: Inferring Spatial Uncertainty in Object Detection
Dec 18, 2020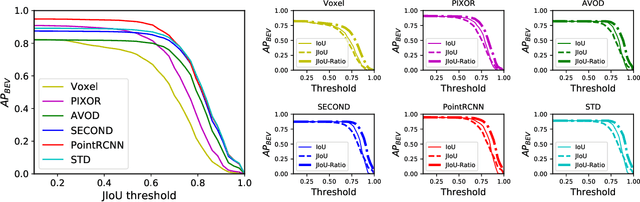

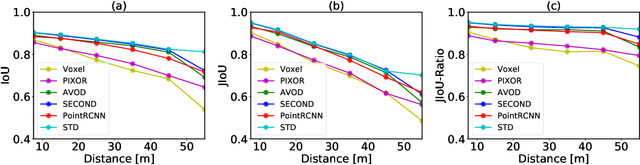
The availability of many real-world driving datasets is a key reason behind the recent progress of object detection algorithms in autonomous driving. However, there exist ambiguity or even failures in object labels due to error-prone annotation process or sensor observation noise. Current public object detection datasets only provide deterministic object labels without considering their inherent uncertainty, as does the common training process or evaluation metrics for object detectors. As a result, an in-depth evaluation among different object detection methods remains challenging, and the training process of object detectors is sub-optimal, especially in probabilistic object detection. In this work, we infer the uncertainty in bounding box labels from LiDAR point clouds based on a generative model, and define a new representation of the probabilistic bounding box through a spatial uncertainty distribution. Comprehensive experiments show that the proposed model reflects complex environmental noises in LiDAR perception and the label quality. Furthermore, we propose Jaccard IoU (JIoU) as a new evaluation metric that extends IoU by incorporating label uncertainty. We conduct an in-depth comparison among several LiDAR-based object detectors using the JIoU metric. Finally, we incorporate the proposed label uncertainty in a loss function to train a probabilistic object detector and to improve its detection accuracy. We verify our proposed methods on two public datasets (KITTI, Waymo), as well as on simulation data. Code is released at https://bit.ly/2W534yo.
DeepReflecs: Deep Learning for Automotive Object Classification with Radar Reflections
Oct 19, 2020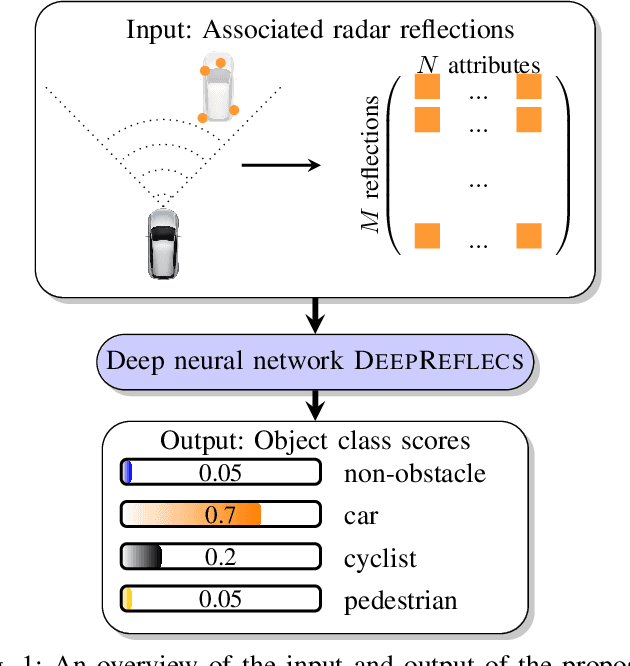
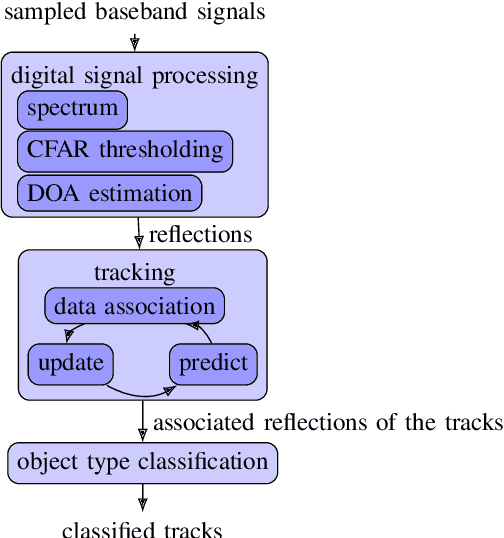
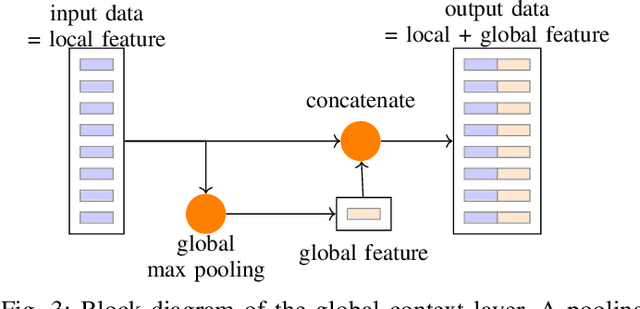
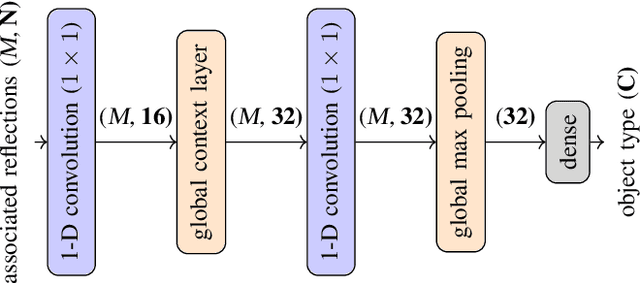
This paper presents an novel object type classification method for automotive applications which uses deep learning with radar reflections. The method provides object class information such as pedestrian, cyclist, car, or non-obstacle. The method is both powerful and efficient, by using a light-weight deep learning approach on reflection level radar data. It fills the gap between low-performant methods of handcrafted features and high-performant methods with convolutional neural networks. The proposed network exploits the specific characteristics of radar reflection data: It handles unordered lists of arbitrary length as input and it combines both extraction of local and global features. In experiments with real data the proposed network outperforms existing methods of handcrafted or learned features. An ablation study analyzes the impact of the proposed global context layer.
Holistic Filter Pruning for Efficient Deep Neural Networks
Sep 17, 2020
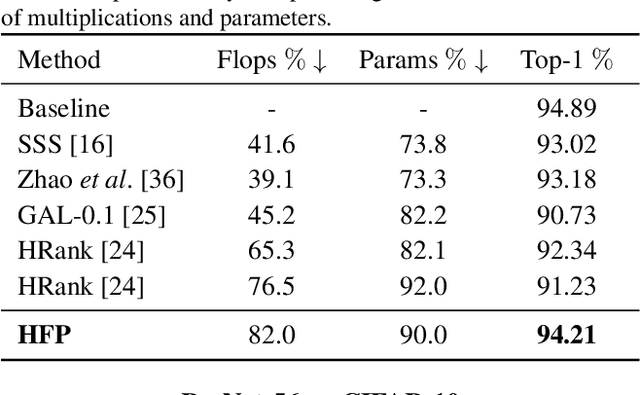

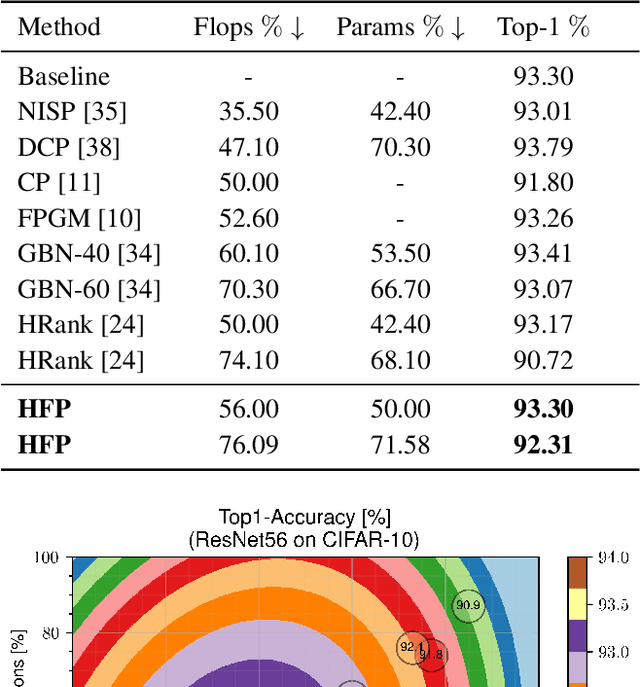
Deep neural networks (DNNs) are usually over-parameterized to increase the likelihood of getting adequate initial weights by random initialization. Consequently, trained DNNs have many redundancies which can be pruned from the model to reduce complexity and improve the ability to generalize. Structural sparsity, as achieved by filter pruning, directly reduces the tensor sizes of weights and activations and is thus particularly effective for reducing complexity. We propose "Holistic Filter Pruning" (HFP), a novel approach for common DNN training that is easy to implement and enables to specify accurate pruning rates for the number of both parameters and multiplications. After each forward pass, the current model complexity is calculated and compared to the desired target size. By gradient descent, a global solution can be found that allocates the pruning budget over the individual layers such that the desired target size is fulfilled. In various experiments, we give insights into the training and achieve state-of-the-art performance on CIFAR-10 and ImageNet (HFP prunes 60% of the multiplications of ResNet-50 on ImageNet with no significant loss in the accuracy). We believe our simple and powerful pruning approach to constitute a valuable contribution for users of DNNs in low-cost applications.
Labels Are Not Perfect: Improving Probabilistic Object Detection via Label Uncertainty
Aug 10, 2020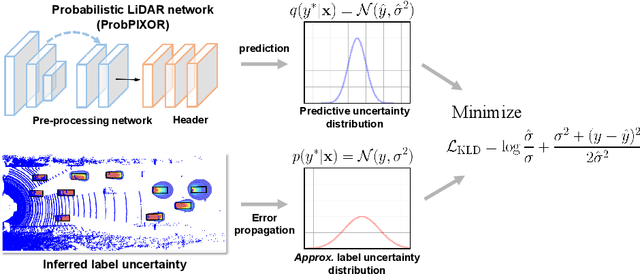
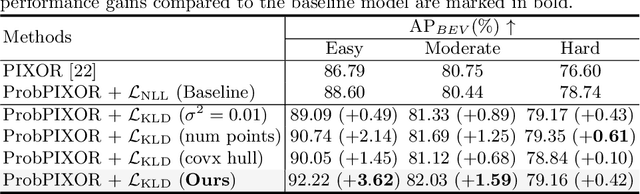
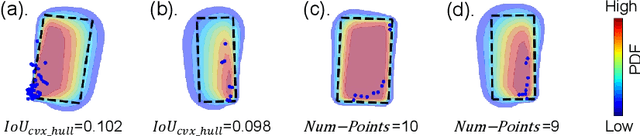

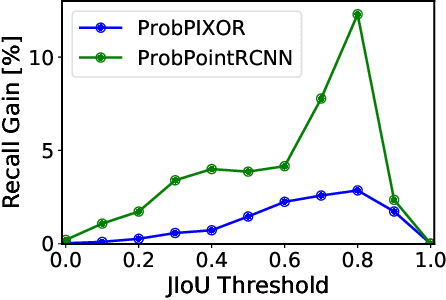
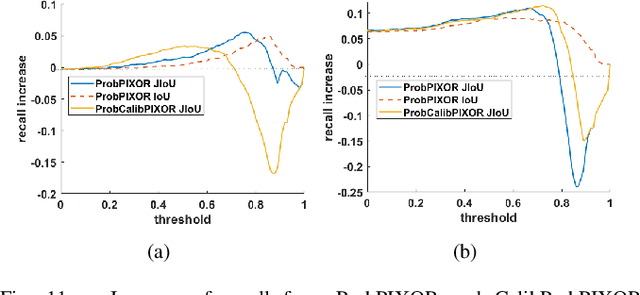
Reliable uncertainty estimation is crucial for robust object detection in autonomous driving. However, previous works on probabilistic object detection either learn predictive probability for bounding box regression in an un-supervised manner, or use simple heuristics to do uncertainty regularization. This leads to unstable training or suboptimal detection performance. In this work, we leverage our previously proposed method for estimating uncertainty inherent in ground truth bounding box parameters (which we call label uncertainty) to improve the detection accuracy of a probabilistic LiDAR-based object detector. Experimental results on the KITTI dataset show that our method surpasses both the baseline model and the models based on simple heuristics by up to 3.6% in terms of Average Precision.
Where can I drive? Deep Ego-Corridor Estimation for Robust Automated Driving
Apr 16, 2020


Lane detection is an essential part of the perception module of any automated driving (AD) or advanced driver assistance system (ADAS). So far, model-driven approaches for the detection of lane markings proved sufficient. More recently, however data-driven approaches have been proposed that show superior results. These deep learning approaches typically propose a classification of the free-space using for example semantic segmentation. While these examples focus and optimize on unmarked inner-city roads, we believe that mapless driving in complex highway scenarios is still not handled with sufficient robustness and availability. Especially in challenging weather situations such as heavy rain, fog at night or reflections in puddles, the reliable detection of lane markings will decrease significantly or completely fail with low-cost video-only AD systems. Therefore, we propose to specifically classify a drivable corridor in the ego-lane on a pixel level with a deep learning approach. Our approach is intentionally kept simple with only 660k parameters. Thus, we were able to easily integrate our algorithm into an online AD system of a test vehicle. We demonstrate the performance of our approach under challenging conditions qualitatively and quantitatively in comparison to a state-of-the-art model-driven approach. We see the current approach as a fallback method whenever a model-driven approach cannot cope with a specific scenario. Due to this, a fallback method does not have to fulfill the same requirements on comfort in lateral control as the primary algorithm: Its task is to catch the temporal shortcomings of the main perception task.
Inferring Spatial Uncertainty in Object Detection
Mar 07, 2020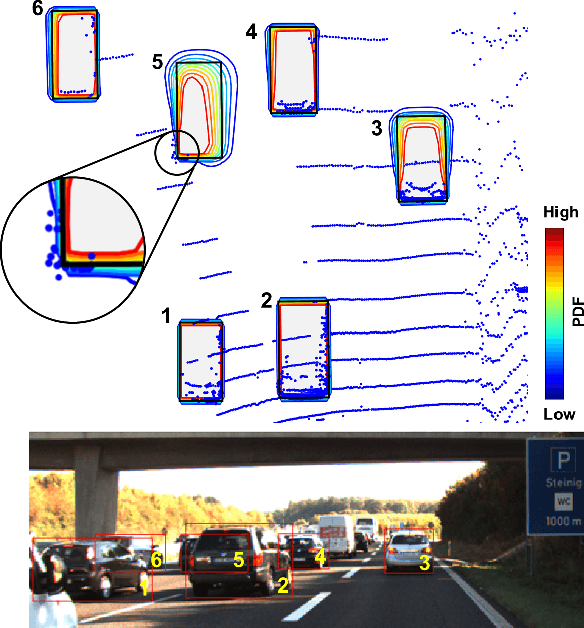
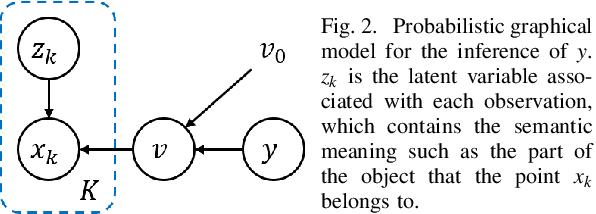
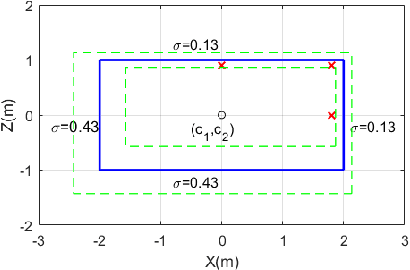
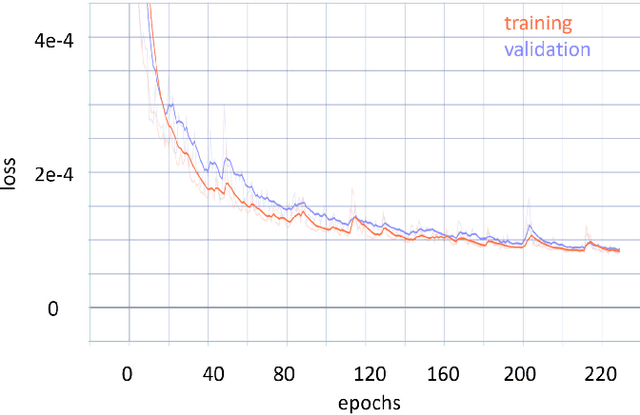
The availability of real-world datasets is the prerequisite to develop object detection methods for autonomous driving. While ambiguity exists in object labels due to error-prone annotation process or sensor observation noises, current object detection datasets only provide deterministic annotations, without considering their uncertainty. This precludes an in-depth evaluation among different object detection methods, especially for those that explicitly model predictive probability. In this work, we propose a generative model to estimate bounding box label uncertainties from LiDAR point clouds, and define a new representation of the probabilistic bounding box through spatial distribution. Comprehensive experiments show that the proposed model represents uncertainties commonly seen in driving scenarios. Based on the spatial distribution, we further propose an extension of IoU, called the Jaccard IoU (JIoU), as a new evaluation metric that incorporates label uncertainty. The experiments on the KITTI and the Waymo Open Datasets show that JIoU is superior to IoU when evaluating probabilistic object detectors.
SYMOG: learning symmetric mixture of Gaussian modes for improved fixed-point quantization
Feb 19, 2020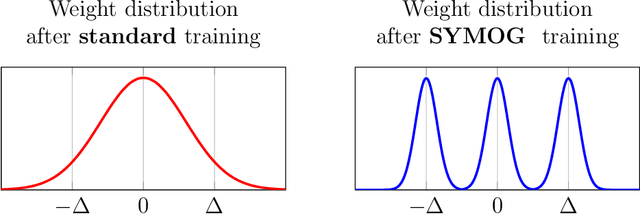
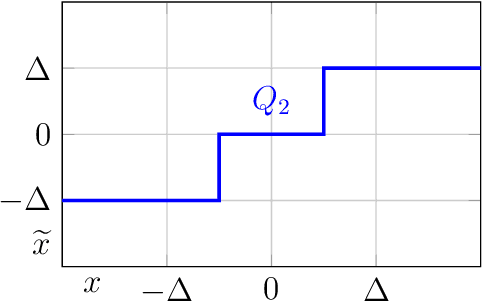
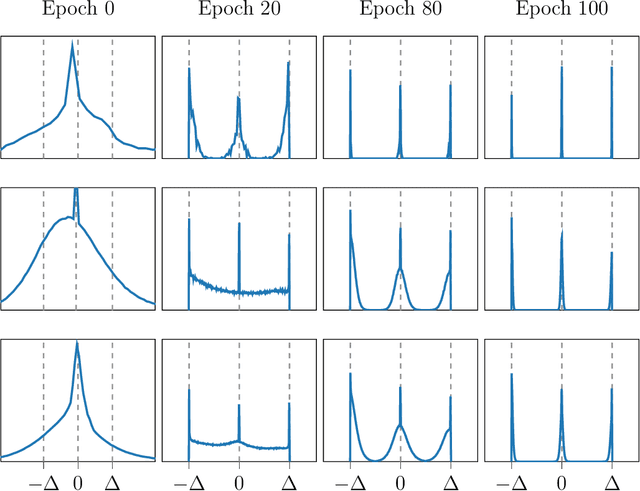

Deep neural networks (DNNs) have been proven to outperform classical methods on several machine learning benchmarks. However, they have high computational complexity and require powerful processing units. Especially when deployed on embedded systems, model size and inference time must be significantly reduced. We propose SYMOG (symmetric mixture of Gaussian modes), which significantly decreases the complexity of DNNs through low-bit fixed-point quantization. SYMOG is a novel soft quantization method such that the learning task and the quantization are solved simultaneously. During training the weight distribution changes from an unimodal Gaussian distribution to a symmetric mixture of Gaussians, where each mean value belongs to a particular fixed-point mode. We evaluate our approach with different architectures (LeNet5, VGG7, VGG11, DenseNet) on common benchmark data sets (MNIST, CIFAR-10, CIFAR-100) and we compare with state-of-the-art quantization approaches. We achieve excellent results and outperform 2-bit state-of-the-art performance with an error rate of only 5.71% on CIFAR-10 and 27.65% on CIFAR-100.
Leveraging Uncertainties for Deep Multi-modal Object Detection in Autonomous Driving
Feb 01, 2020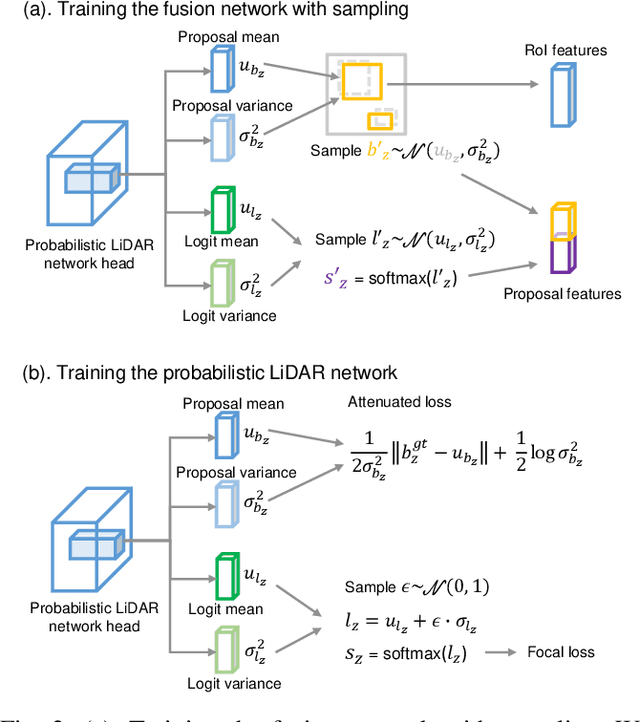
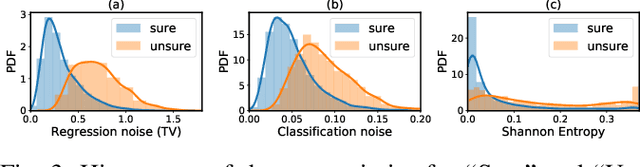
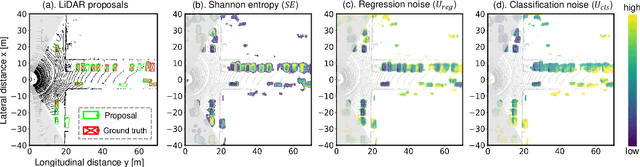
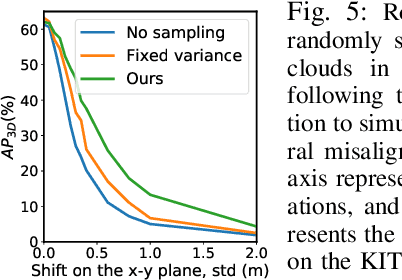
This work presents a probabilistic deep neural network that combines LiDAR point clouds and RGB camera images for robust, accurate 3D object detection. We explicitly model uncertainties in the classification and regression tasks, and leverage uncertainties to train the fusion network via a sampling mechanism. We validate our method on three datasets with challenging real-world driving scenarios. Experimental results show that the predicted uncertainties reflect complex environmental uncertainty like difficulties of a human expert to label objects. The results also show that our method consistently improves the Average Precision by up to 7% compared to the baseline method. When sensors are temporally misaligned, the sampling method improves the Average Precision by up to 20%, showing its high robustness against noisy sensor inputs.
Can We Trust You? On Calibration of a Probabilistic Object Detector for Autonomous Driving
Sep 26, 2019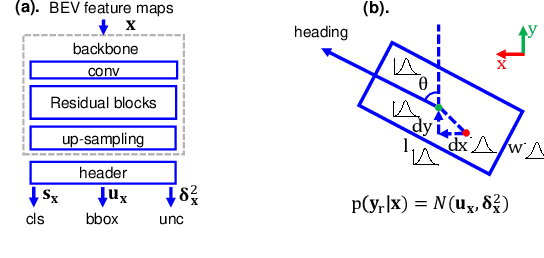
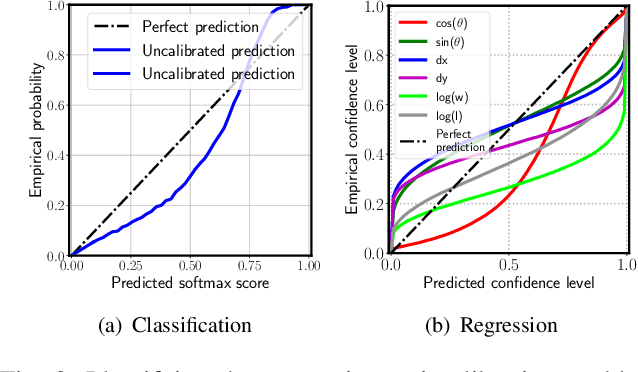
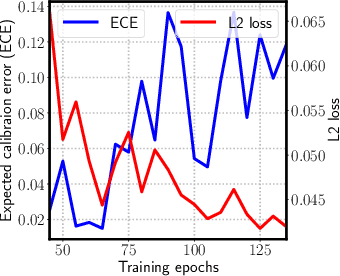
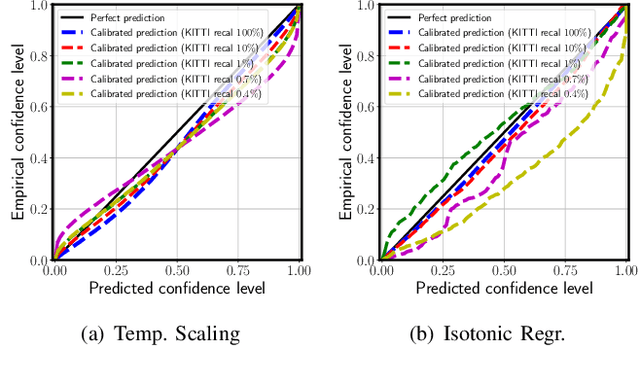
Reliable uncertainty estimation is crucial for perception systems in safe autonomous driving. Recently, many methods have been proposed to model uncertainties in deep learning based object detectors. However, the estimated probabilities are often uncalibrated, which may lead to severe problems in safety critical scenarios. In this work, we identify such uncertainty miscalibration problems in a probabilistic LiDAR 3D object detection network, and propose three practical methods to significantly reduce errors in uncertainty calibration. Extensive experiments on several datasets show that our methods produce well-calibrated uncertainties, and generalize well between different datasets.
Learning Multimodal Fixed-Point Weights using Gradient Descent
Jul 16, 2019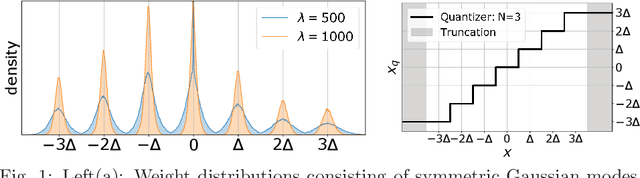
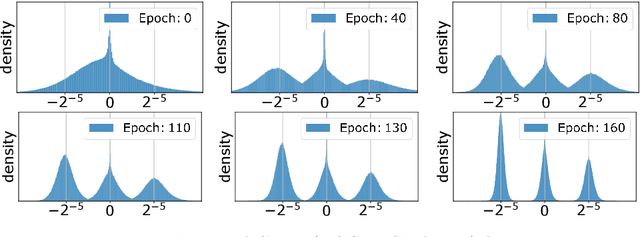
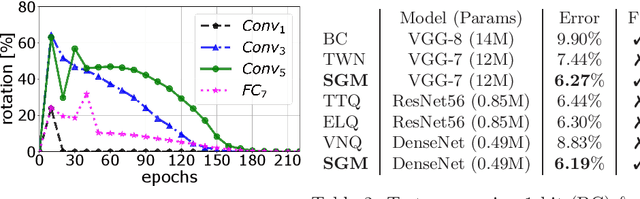
Due to their high computational complexity, deep neural networks are still limited to powerful processing units. To promote a reduced model complexity by dint of low-bit fixed-point quantization, we propose a gradient-based optimization strategy to generate a symmetric mixture of Gaussian modes (SGM) where each mode belongs to a particular quantization stage. We achieve 2-bit state-of-the-art performance and illustrate the model's ability for self-dependent weight adaptation during training.
* presented at ESANN 2019 (European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning)