 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPMFS: Global Foundation and Personalized Optimization for Multi-Label Feature Selection
Apr 17, 2025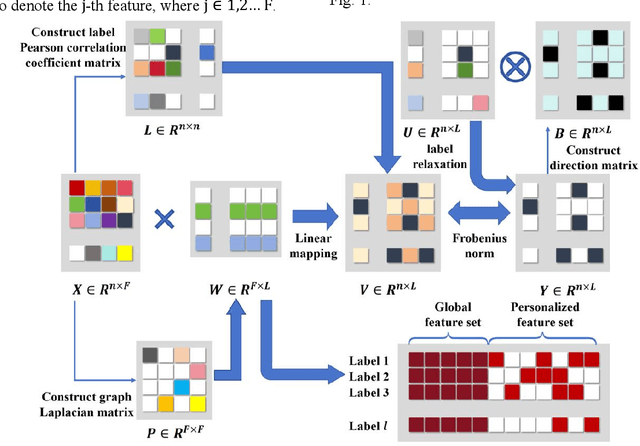
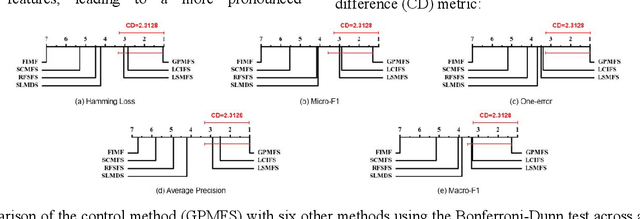
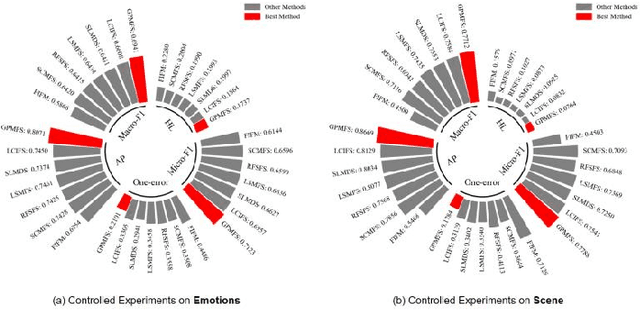
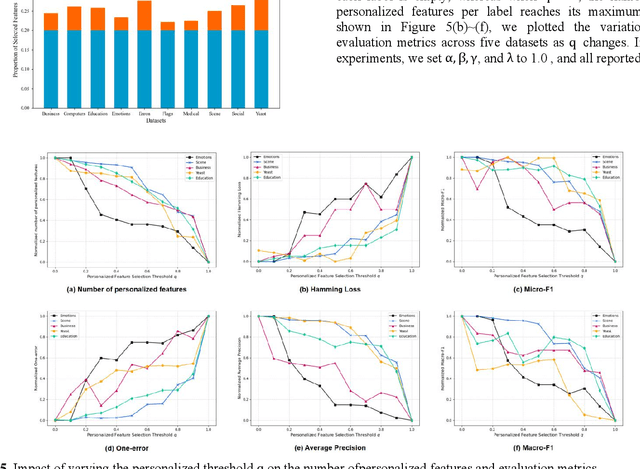
As artificial intelligence methods are increasingly applied to complex task scenarios, high dimensional multi-label learning has emerged as a prominent research focus. At present, the curse of dimensionality remains one of the major bottlenecks in high-dimensional multi-label learning, which can be effectively addressed through multi-label feature selection methods. However, existing multi-label feature selection methods mostly focus on identifying global features shared across all labels, which overlooks personalized characteristics and specific requirements of individual labels. This global-only perspective may limit the ability to capture label-specific discriminative information, thereby affecting overall performance. In this paper, we propose a novel method called GPMFS (Global Foundation and Personalized Optimization for Multi-Label Feature Selection). GPMFS firstly identifies global features by exploiting label correlations, then adaptively supplements each label with a personalized subset of discriminative features using a threshold-controlled strategy. Experiments on multiple real-world datasets demonstrate that GPMFS achieves superior performance while maintaining strong interpretability and robustness. Furthermore, GPMFS provides insights into the label-specific strength across different multi-label datasets, thereby demonstrating the necessity and potential applicability of personalized feature selection approaches.
Zero-shot Compound Expression Recognition with Visual Language Model at the 6th ABAW Challenge
Mar 18, 2024


Conventional approaches to facial expression recognition primarily focus on the classification of six basic facial expressions. Nevertheless, real-world situations present a wider range of complex compound expressions that consist of combinations of these basics ones due to limited availability of comprehensive training datasets. The 6th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW) offered unlabeled datasets containing compound expressions. In this study, we propose a zero-shot approach for recognizing compound expressions by leveraging a pretrained visual language model integrated with some traditional CNN networks.
Joint Prediction of Monocular Depth and Structure using Planar and Parallax Geometry
Jul 13, 2022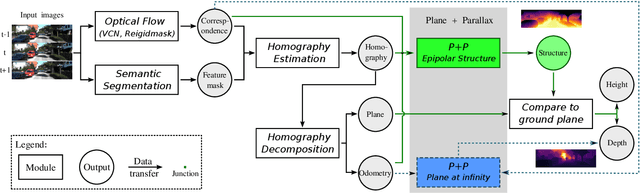
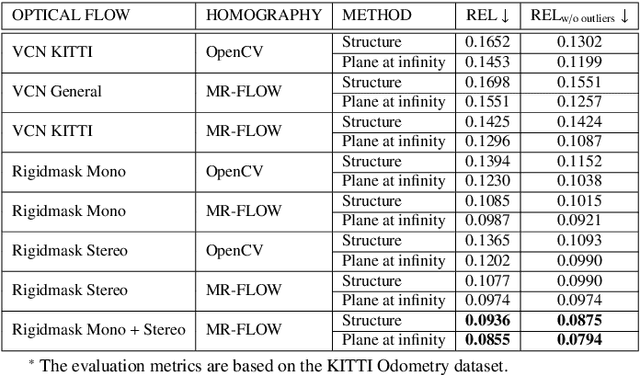
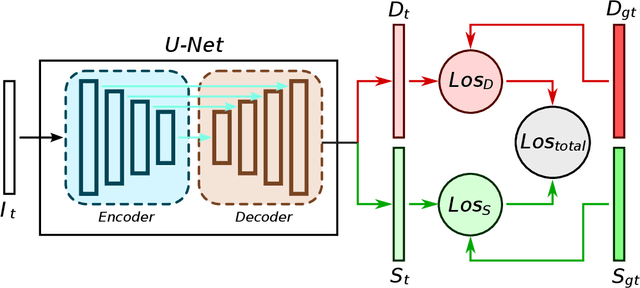
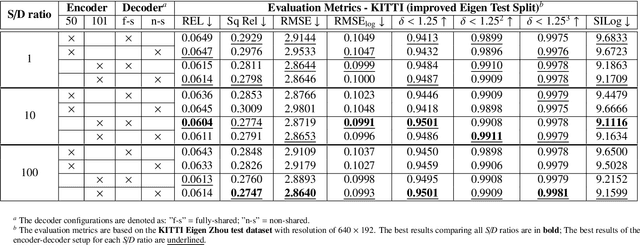
Supervised learning depth estimation methods can achieve good performance when trained on high-quality ground-truth, like LiDAR data. However, LiDAR can only generate sparse 3D maps which causes losing information. Obtaining high-quality ground-truth depth data per pixel is difficult to acquire. In order to overcome this limitation, we propose a novel approach combining structure information from a promising Plane and Parallax geometry pipeline with depth information into a U-Net supervised learning network, which results in quantitative and qualitative improvement compared to existing popular learning-based methods. In particular, the model is evaluated on two large-scale and challenging datasets: KITTI Vision Benchmark and Cityscapes dataset and achieve the best performance in terms of relative error. Compared with pure depth supervision models, our model has impressive performance on depth prediction of thin objects and edges, and compared to structure prediction baseline, our model performs more robustly.
Source-free Domain Adaptation for Multi-site and Lifespan Brain Skull Stripping
Mar 11, 2022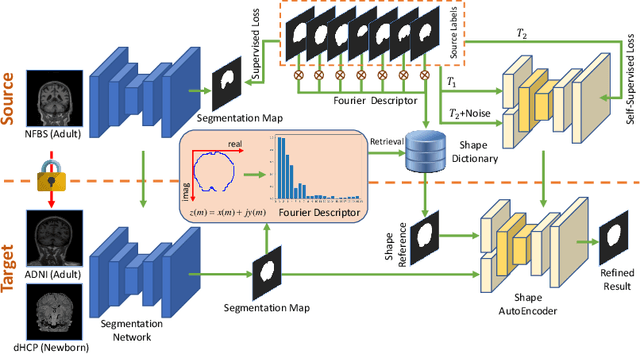

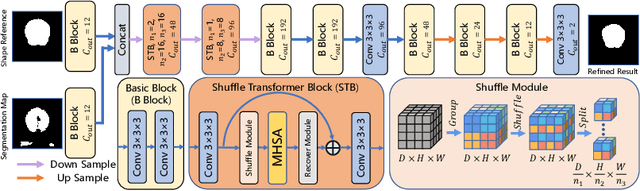

Skull stripping is a crucial prerequisite step in the analysis of brain magnetic resonance (MR) images. Although many excellent works or tools have been proposed, they suffer from low generalization capability. For instance, the model trained on a dataset with specific imaging parameters (source domain) cannot be well applied to other datasets with different imaging parameters (target domain). Especially, for the lifespan datasets, the model trained on an adult dataset is not applicable to an infant dataset due to the large domain difference. To address this issue, numerous domain adaptation (DA) methods have been proposed to align the extracted features between the source and target domains, requiring concurrent access to the input images of both domains. Unfortunately, it is problematic to share the images due to privacy. In this paper, we design a source-free domain adaptation framework (SDAF) for multi-site and lifespan skull stripping that can accomplish domain adaptation without access to source domain images. Our method only needs to share the source labels as shape dictionaries and the weights trained on the source data, without disclosing private information from source domain subjects. To deal with the domain shift between multi-site lifespan datasets, we take advantage of the brain shape prior which is invariant to imaging parameters and ages. Experiments demonstrate that our framework can significantly outperform the state-of-the-art methods on multi-site lifespan datasets.
Leveraging Uncertainties for Deep Multi-modal Object Detection in Autonomous Driving
Feb 01, 2020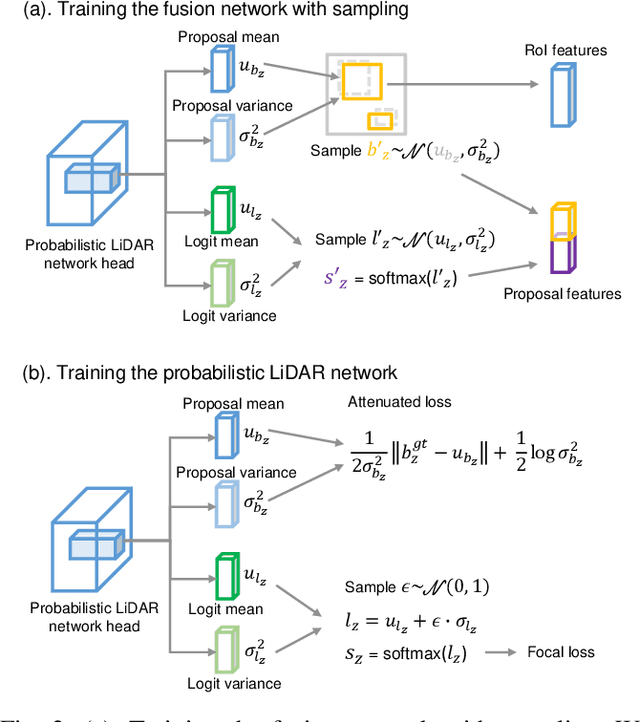
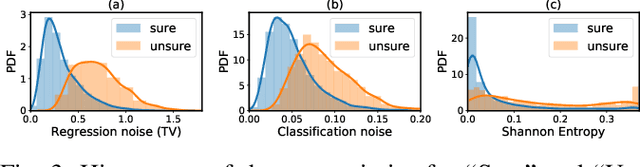
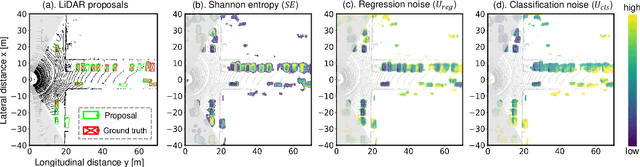
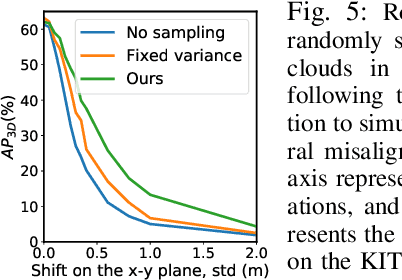
This work presents a probabilistic deep neural network that combines LiDAR point clouds and RGB camera images for robust, accurate 3D object detection. We explicitly model uncertainties in the classification and regression tasks, and leverage uncertainties to train the fusion network via a sampling mechanism. We validate our method on three datasets with challenging real-world driving scenarios. Experimental results show that the predicted uncertainties reflect complex environmental uncertainty like difficulties of a human expert to label objects. The results also show that our method consistently improves the Average Precision by up to 7% compared to the baseline method. When sensors are temporally misaligned, the sampling method improves the Average Precision by up to 20%, showing its high robustness against noisy sensor inputs.