 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Prediction of Monocular Depth and Structure using Planar and Parallax Geometry
Paper and Code
Jul 13, 2022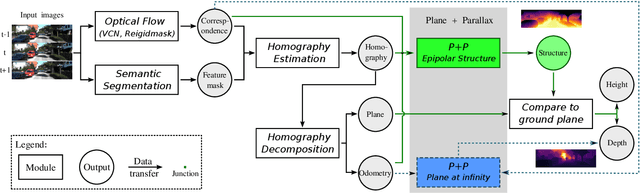
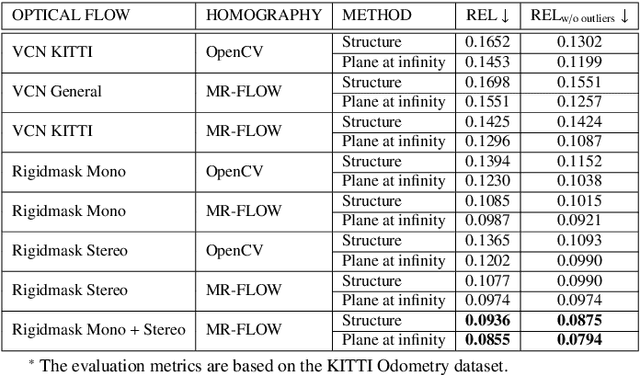
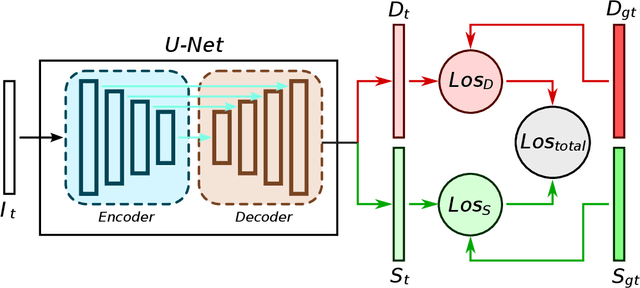
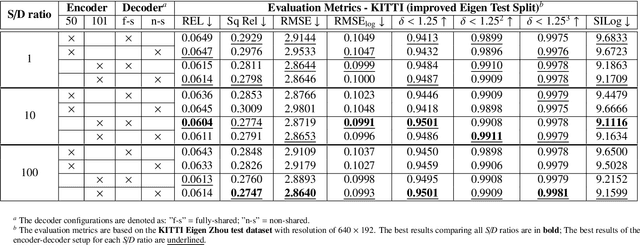
Supervised learning depth estimation methods can achieve good performance when trained on high-quality ground-truth, like LiDAR data. However, LiDAR can only generate sparse 3D maps which causes losing information. Obtaining high-quality ground-truth depth data per pixel is difficult to acquire. In order to overcome this limitation, we propose a novel approach combining structure information from a promising Plane and Parallax geometry pipeline with depth information into a U-Net supervised learning network, which results in quantitative and qualitative improvement compared to existing popular learning-based methods. In particular, the model is evaluated on two large-scale and challenging datasets: KITTI Vision Benchmark and Cityscapes dataset and achieve the best performance in terms of relative error. Compared with pure depth supervision models, our model has impressive performance on depth prediction of thin objects and edges, and compared to structure prediction baseline, our model performs more robustly.