 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Jun 04, 2026Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failures. Diagnosing these failures requires instance-level feedback that answers where a defect occurs, what type it is, why it is defective, and its importance to overall image quality. While recent dense-feedback methods move beyond scalar supervision, their heatmap-centric representations still formulate diagnosis as pixel-field regression, making it difficult to localize variable-cardinality defects and bind semantic reasons to individual failures. To address this representation bottleneck, we propose Structured Defect Grounding (SDG), which casts T2I diagnosis as structured set prediction by modeling each defect as a (location, type, reason, importance) tuple. To make this formulation trainable and measurable, we introduce SDG-30K, a 30K-image dataset with box-grounded annotations across four modern T2I generators, together with a dedicated evaluation protocol, SDG-Eval. Building on this structured representation, we further present a diagnosis-to-alignment framework in which a Vision-Language Model (VLM) serves as the SDG detector, and BoxFlow-GRPO converts predicted defect sets into box-derived, importance-weighted spatial rewards for diffusion model alignment. Extensive experiments show that our SDG detector outperforms leading proprietary VLMs on structured defect grounding, while SDG-guided rewards consistently improve T2I alignment and support localized image refinement. These results establish SDG as a unified, instance-level interface for diagnosing, evaluating, and enhancing modern generative models.
AgentCVR: Active Multi-Agent Cross-Video Reasoning via Script-Simulated Reinforcement Learning
May 28, 2026Cross-Video Reasoning (CVR) has emerged as a critical frontier in multimodal intelligence, requiring models to retrieve, align, and aggregate evidence distributed across multiple videos. Current Multimodal Large Language Models (MLLMs) often struggle with CVR, as simple single-pass strategies encode multiple videos into a shared compressed context, potentially obscuring rare but critical evidence. In this paper, we propose AgentCVR, a multi-agent framework that treats CVR as an active evidence-acquisition task. AgentCVR employs a Master Agent to iteratively coordinate specialized Visual and Audio Agents for targeted evidence extraction. To ensure efficient training, we introduce Script-Simulated RL, which optimizes the agent's policy with LLM-generated semantic scripts and a lightweight text-based simulator, bypassing costly multimodal inference during online exploration. Experimental results on a comprehensive CVR benchmark show that AgentCVR outperforms single-pass baselines and achieves comparable performance to state-of-the-art closed-source systems, particularly in complex cross-video alignment and localization. To ensure reproducibility, our code is available at https://github.com/wang-jh24/AgentCVR.
AU Codes, Language, and Synthesis: Translating Anatomy to Text for Facial Behavior Synthesis
Mar 19, 2026Facial behavior synthesis remains a critical yet underexplored challenge. While text-to-face models have made progress, they often rely on coarse emotion categories, which lack the nuance needed to capture the full spectrum of human nonverbal communication. Action Units (AUs) provide a more precise and anatomically grounded alternative. However, current AU-based approaches typically encode AUs as one-hot vectors, modeling compound expressions as simple linear combinations of individual AUs. This linearity becomes problematic when handling conflicting AUs--defined as those which activate the same facial muscle with opposing actions. Such cases lead to anatomically implausible artifacts and unnatural motion superpositions. To address this, we propose a novel method that represents facial behavior through natural language descriptions of AUs. This approach preserves the expressiveness of the AU framework while enabling explicit modeling of complex and conflicting AUs. It also unlocks the potential of modern text-to-image models for high-fidelity facial synthesis. Supporting this direction, we introduce BP4D-AUText, the first large-scale text-image paired dataset for complex facial behavior. It is synthesized by applying a rule-based Dynamic AU Text Processor to the BP4D and BP4D+ datasets. We further propose VQ-AUFace, a generative model that leverages facial structural priors to synthesize realistic and diverse facial behaviors from text. Extensive quantitative experiments and user studies demonstrate that our approach significantly outperforms existing methods. It excels in generating facial expressions that are anatomically plausible, behaviorally rich, and perceptually convincing, particularly under challenging conditions involving conflicting AUs.
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
Panonut360: A Head and Eye Tracking Dataset for Panoramic Video
Mar 26, 2024With the rapid development and widespread application of VR/AR technology, maximizing the quality of immersive panoramic video services that match users' personal preferences and habits has become a long-standing challenge. Understanding the saliency region where users focus, based on data collected with HMDs, can promote multimedia encoding, transmission, and quality assessment. At the same time, large-scale datasets are essential for researchers and developers to explore short/long-term user behavior patterns and train AI models related to panoramic videos. However, existing panoramic video datasets often include low-frequency user head or eye movement data through short-term videos only, lacking sufficient data for analyzing users' Field of View (FoV) and generating video saliency regions. Driven by these practical factors, in this paper, we present a head and eye tracking dataset involving 50 users (25 males and 25 females) watching 15 panoramic videos. The dataset provides details on the viewport and gaze attention locations of users. Besides, we present some statistics samples extracted from the dataset. For example, the deviation between head and eye movements challenges the widely held assumption that gaze attention decreases from the center of the FoV following a Gaussian distribution. Our analysis reveals a consistent downward offset in gaze fixations relative to the FoV in experimental settings involving multiple users and videos. That's why we name the dataset Panonut, a saliency weighting shaped like a donut. Finally, we also provide a script that generates saliency distributions based on given head or eye coordinates and pre-generated saliency distribution map sets of each video from the collected eye tracking data. The dataset is available on website: https://dianvrlab.github.io/Panonut360/.
Zero-shot Compound Expression Recognition with Visual Language Model at the 6th ABAW Challenge
Mar 18, 2024


Conventional approaches to facial expression recognition primarily focus on the classification of six basic facial expressions. Nevertheless, real-world situations present a wider range of complex compound expressions that consist of combinations of these basics ones due to limited availability of comprehensive training datasets. The 6th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW) offered unlabeled datasets containing compound expressions. In this study, we propose a zero-shot approach for recognizing compound expressions by leveraging a pretrained visual language model integrated with some traditional CNN networks.
Facial Affective Behavior Analysis Method for 5th ABAW Competition
Mar 16, 2023Facial affective behavior analysis is important for human-computer interaction. 5th ABAW competition includes three challenges from Aff-Wild2 database. Three common facial affective analysis tasks are involved, i.e. valence-arousal estimation, expression classification, action unit recognition. For the three challenges, we construct three different models to solve the corresponding problems to improve the results, such as data unbalance and data noise. For the experiments of three challenges, we train the models on the provided training data and validate the models on the validation data.
Multi-Task Learning for Emotion Descriptors Estimation at the fourth ABAW Challenge
Jul 20, 2022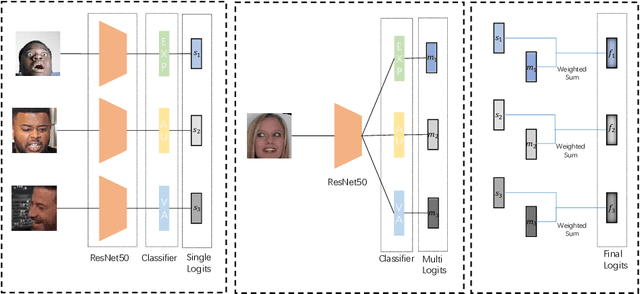

Facial valence/arousal, expression and action unit are related tasks in facial affective analysis. However, the tasks only have limited performance in the wild due to the various collected conditions. The 4th competition on affective behavior analysis in the wild (ABAW) provided images with valence/arousal, expression and action unit labels. In this paper, we introduce multi-task learning framework to enhance the performance of three related tasks in the wild. Feature sharing and label fusion are used to utilize their relations. We conduct experiments on the provided training and validating data.
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.
Facial Action Unit Recognition Based on Transfer Learning
Mar 25, 2022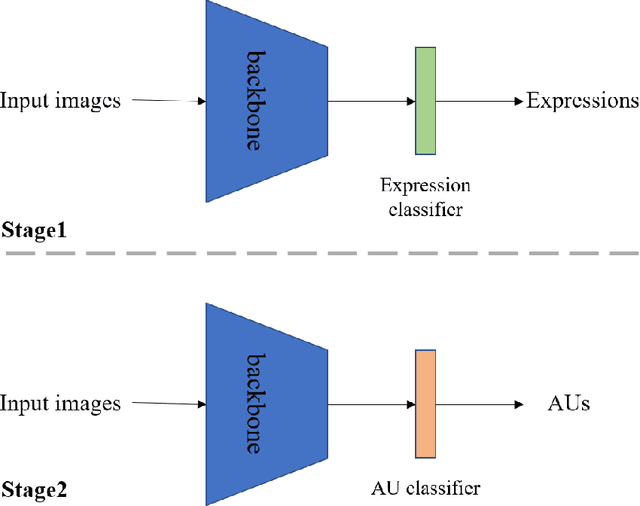
Facial action unit recognition is an important task for facial analysis. Owing to the complex collection environment, facial action unit recognition in the wild is still challenging. The 3rd competition on affective behavior analysis in-the-wild (ABAW) has provided large amount of facial images with facial action unit annotations. In this paper, we introduce a facial action unit recognition method based on transfer learning. We first use available facial images with expression labels to train the feature extraction network. Then we fine-tune the network for facial action unit recognition.