 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALo: Learning Posture-Aware Locomotion for Quadruped Robots
Mar 06, 2025
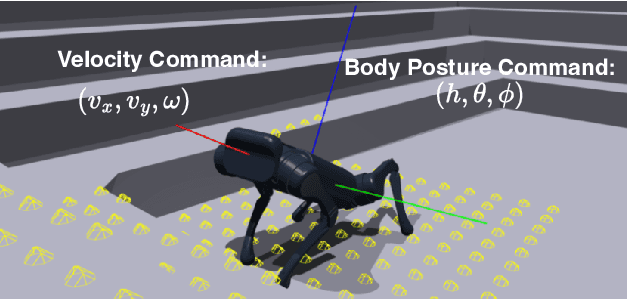
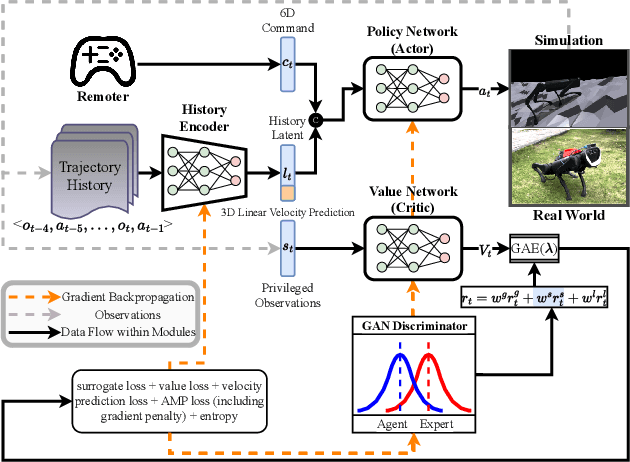
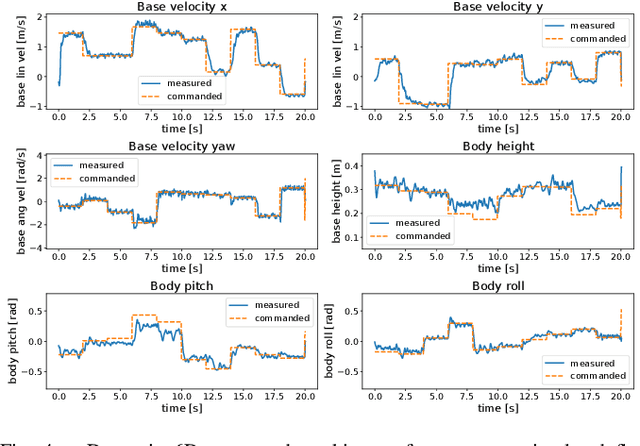
With the rapid development of embodied intelligence, locomotion control of quadruped robots on complex terrains has become a research hotspot. Unlike traditional locomotion control approaches focusing solely on velocity tracking, we pursue to balance the agility and robustness of quadruped robots on diverse and complex terrains. To this end, we propose an end-to-end deep reinforcement learning framework for posture-aware locomotion named PALo, which manages to handle simultaneous linear and angular velocity tracking and real-time adjustments of body height, pitch, and roll angles. In PALo, the locomotion control problem is formulated as a partially observable Markov decision process, and an asymmetric actor-critic architecture is adopted to overcome the sim-to-real challenge. Further, by incorporating customized training curricula, PALo achieves agile posture-aware locomotion control in simulated environments and successfully transfers to real-world settings without fine-tuning, allowing real-time control of the quadruped robot's locomotion and body posture across challenging terrains. Through in-depth experimental analysis, we identify the key components of PALo that contribute to its performance, further validating the effectiveness of the proposed method. The results of this study provide new possibilities for the low-level locomotion control of quadruped robots in higher dimensional command spaces and lay the foundation for future research on upper-level modules for embodied intelligence.
Emotional Reaction Intensity Estimation Based on Multimodal Data
Mar 16, 2023This paper introduces our method for the Emotional Reaction Intensity (ERI) Estimation Challenge, in CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Based on the multimodal data provided by the originazers, we extract acoustic and visual features with different pretrained models. The multimodal features are mixed together by Transformer Encoders with cross-modal attention mechnism. In this paper, 1. better features are extracted with the SOTA pretrained models. 2. Compared with the baseline, we improve the Pearson's Correlations Coefficient a lot. 3. We process the data with some special skills to enhance performance ability of our model.
Facial Affective Behavior Analysis Method for 5th ABAW Competition
Mar 16, 2023Facial affective behavior analysis is important for human-computer interaction. 5th ABAW competition includes three challenges from Aff-Wild2 database. Three common facial affective analysis tasks are involved, i.e. valence-arousal estimation, expression classification, action unit recognition. For the three challenges, we construct three different models to solve the corresponding problems to improve the results, such as data unbalance and data noise. For the experiments of three challenges, we train the models on the provided training data and validate the models on the validation data.
Multi-Task Learning for Emotion Descriptors Estimation at the fourth ABAW Challenge
Jul 20, 2022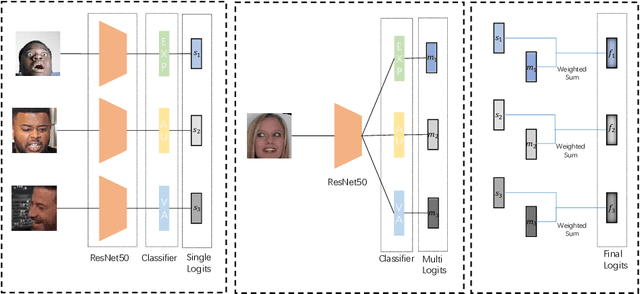

Facial valence/arousal, expression and action unit are related tasks in facial affective analysis. However, the tasks only have limited performance in the wild due to the various collected conditions. The 4th competition on affective behavior analysis in the wild (ABAW) provided images with valence/arousal, expression and action unit labels. In this paper, we introduce multi-task learning framework to enhance the performance of three related tasks in the wild. Feature sharing and label fusion are used to utilize their relations. We conduct experiments on the provided training and validating data.
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.