 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Filter Pruning for Efficient Deep Neural Networks
Sep 17, 2020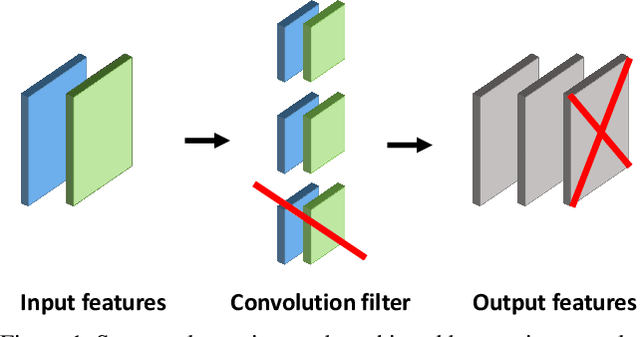
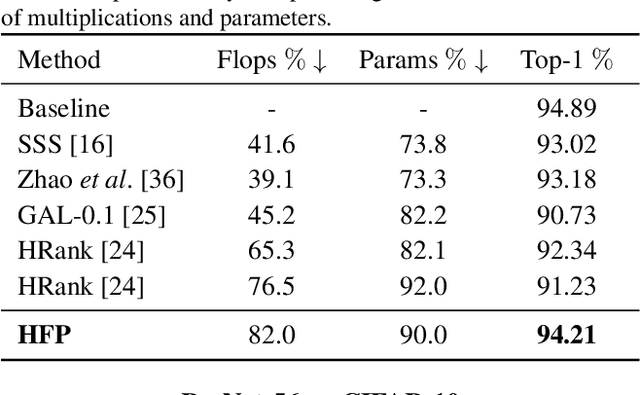

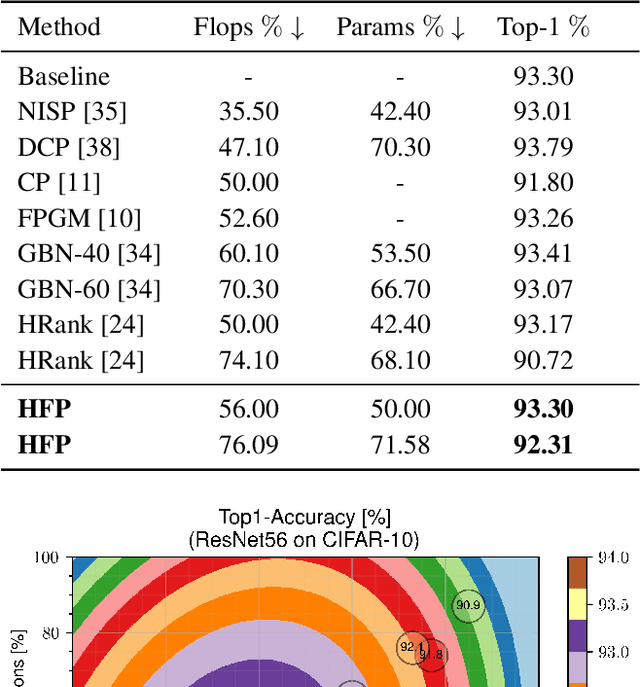
Deep neural networks (DNNs) are usually over-parameterized to increase the likelihood of getting adequate initial weights by random initialization. Consequently, trained DNNs have many redundancies which can be pruned from the model to reduce complexity and improve the ability to generalize. Structural sparsity, as achieved by filter pruning, directly reduces the tensor sizes of weights and activations and is thus particularly effective for reducing complexity. We propose "Holistic Filter Pruning" (HFP), a novel approach for common DNN training that is easy to implement and enables to specify accurate pruning rates for the number of both parameters and multiplications. After each forward pass, the current model complexity is calculated and compared to the desired target size. By gradient descent, a global solution can be found that allocates the pruning budget over the individual layers such that the desired target size is fulfilled. In various experiments, we give insights into the training and achieve state-of-the-art performance on CIFAR-10 and ImageNet (HFP prunes 60% of the multiplications of ResNet-50 on ImageNet with no significant loss in the accuracy). We believe our simple and powerful pruning approach to constitute a valuable contribution for users of DNNs in low-cost applications.
SYMOG: learning symmetric mixture of Gaussian modes for improved fixed-point quantization
Feb 19, 2020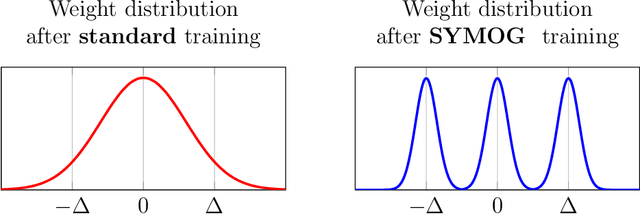
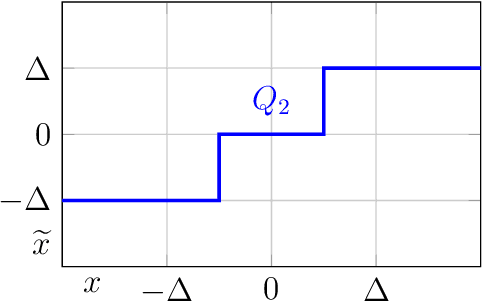
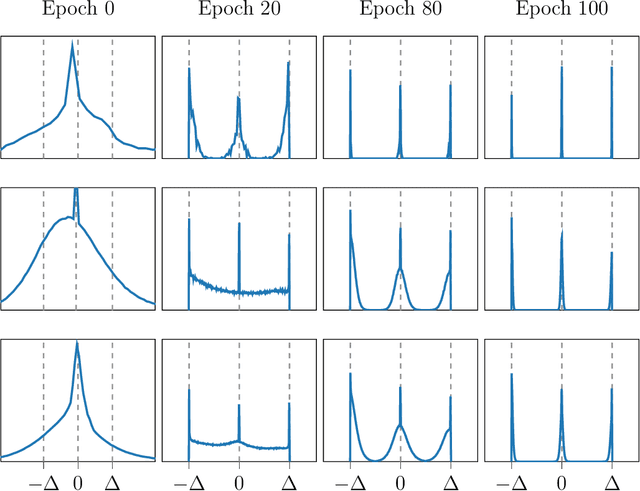

Deep neural networks (DNNs) have been proven to outperform classical methods on several machine learning benchmarks. However, they have high computational complexity and require powerful processing units. Especially when deployed on embedded systems, model size and inference time must be significantly reduced. We propose SYMOG (symmetric mixture of Gaussian modes), which significantly decreases the complexity of DNNs through low-bit fixed-point quantization. SYMOG is a novel soft quantization method such that the learning task and the quantization are solved simultaneously. During training the weight distribution changes from an unimodal Gaussian distribution to a symmetric mixture of Gaussians, where each mean value belongs to a particular fixed-point mode. We evaluate our approach with different architectures (LeNet5, VGG7, VGG11, DenseNet) on common benchmark data sets (MNIST, CIFAR-10, CIFAR-100) and we compare with state-of-the-art quantization approaches. We achieve excellent results and outperform 2-bit state-of-the-art performance with an error rate of only 5.71% on CIFAR-10 and 27.65% on CIFAR-100.
Learning Multimodal Fixed-Point Weights using Gradient Descent
Jul 16, 2019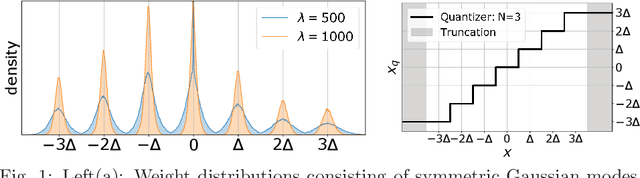
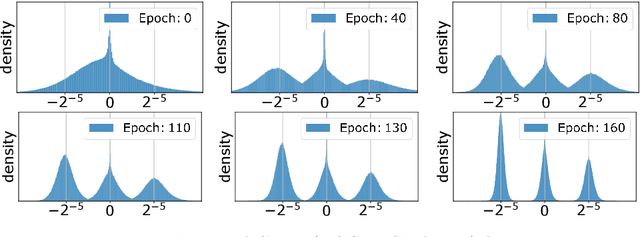
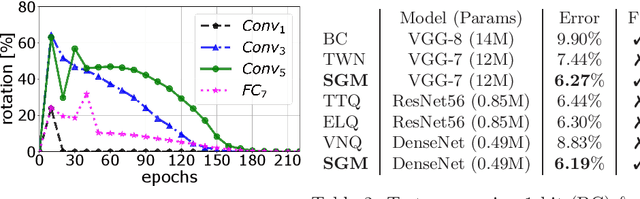
Due to their high computational complexity, deep neural networks are still limited to powerful processing units. To promote a reduced model complexity by dint of low-bit fixed-point quantization, we propose a gradient-based optimization strategy to generate a symmetric mixture of Gaussian modes (SGM) where each mode belongs to a particular quantization stage. We achieve 2-bit state-of-the-art performance and illustrate the model's ability for self-dependent weight adaptation during training.
* presented at ESANN 2019 (European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning)