 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOOD: Exploiting Language Representations for LiDAR-based Out-of-Distribution Object Detection
Mar 09, 2026LiDAR-based 3D object detection plays a critical role for reliable and safe autonomous driving systems. However, existing detectors often produce overly confident predictions for objects not belonging to known categories, posing significant safety risks. This is caused by so-called out-of-distribution (OOD) objects, which were not part of the training data, resulting in incorrect predictions. To address this challenge, we propose ALOOD (Aligned LiDAR representations for Out-Of-Distribution Detection), a novel approach that incorporates language representations from a vision-language model (VLM). By aligning the object features from the object detector to the feature space of the VLM, we can treat the detection of OOD objects as a zero-shot classification task. We demonstrate competitive performance on the nuScenes OOD benchmark, establishing a novel approach to OOD object detection in LiDAR using language representations. The source code is available at https://github.com/uulm-mrm/mmood3d.
Open-Set LiDAR Panoptic Segmentation Guided by Uncertainty-Aware Learning
Jun 16, 2025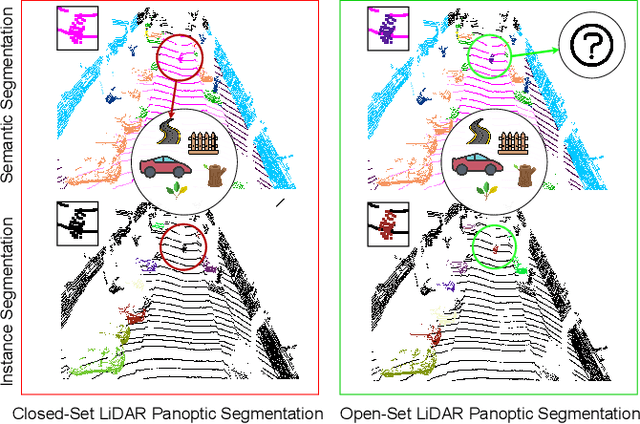
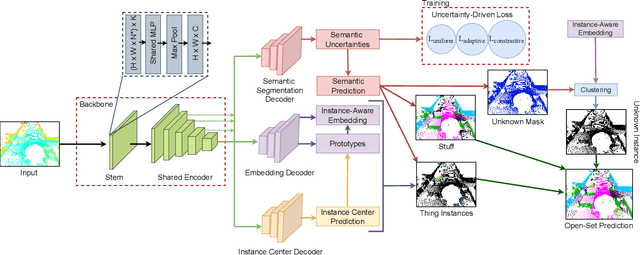
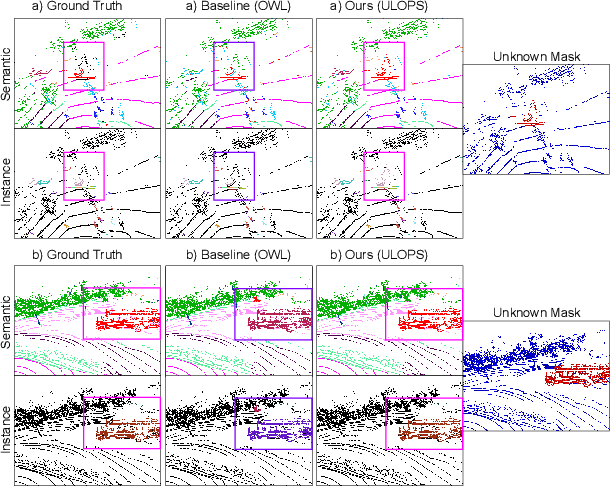
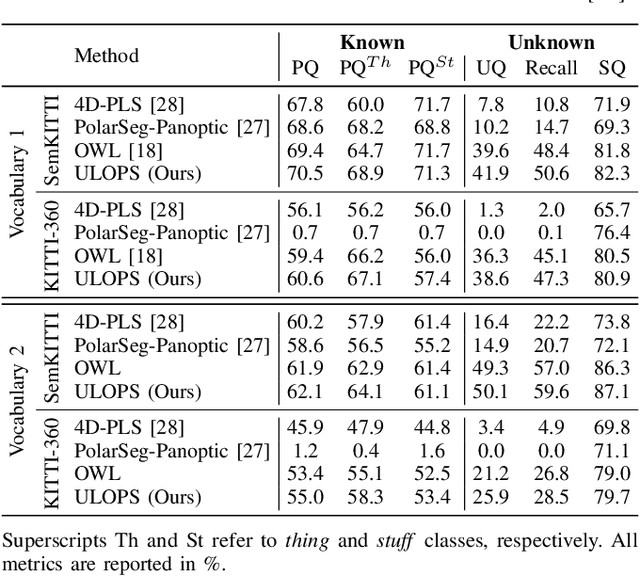
Autonomous vehicles that navigate in open-world environments may encounter previously unseen object classes. However, most existing LiDAR panoptic segmentation models rely on closed-set assumptions, failing to detect unknown object instances. In this work, we propose ULOPS, an uncertainty-guided open-set panoptic segmentation framework that leverages Dirichlet-based evidential learning to model predictive uncertainty. Our architecture incorporates separate decoders for semantic segmentation with uncertainty estimation, embedding with prototype association, and instance center prediction. During inference, we leverage uncertainty estimates to identify and segment unknown instances. To strengthen the model's ability to differentiate between known and unknown objects, we introduce three uncertainty-driven loss functions. Uniform Evidence Loss to encourage high uncertainty in unknown regions. Adaptive Uncertainty Separation Loss ensures a consistent difference in uncertainty estimates between known and unknown objects at a global scale. Contrastive Uncertainty Loss refines this separation at the fine-grained level. To evaluate open-set performance, we extend benchmark settings on KITTI-360 and introduce a new open-set evaluation for nuScenes. Extensive experiments demonstrate that ULOPS consistently outperforms existing open-set LiDAR panoptic segmentation methods.
Multi-Scale Neighborhood Occupancy Masked Autoencoder for Self-Supervised Learning in LiDAR Point Clouds
Feb 27, 2025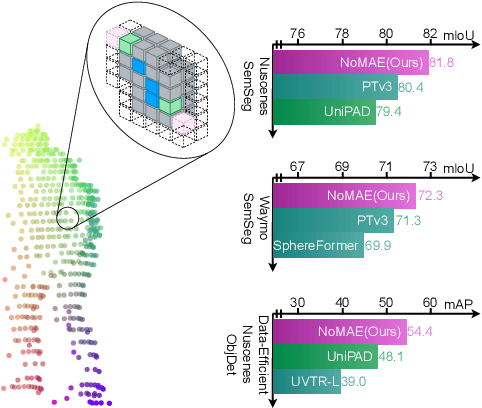
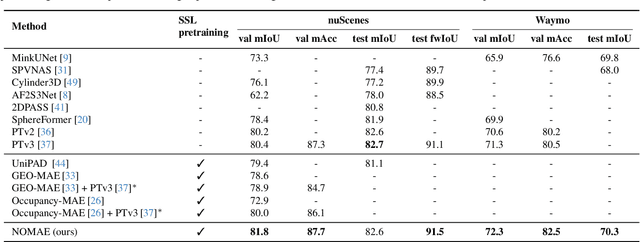
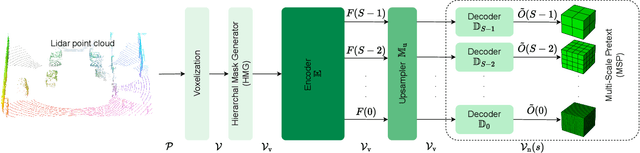
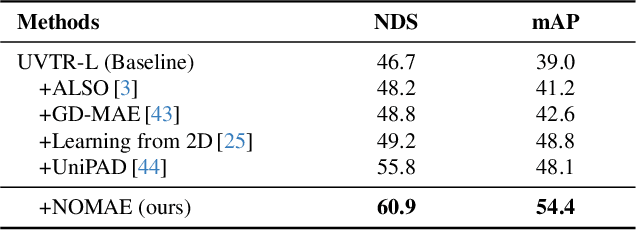
Masked autoencoders (MAE) have shown tremendous potential for self-supervised learning (SSL) in vision and beyond. However, point clouds from LiDARs used in automated driving are particularly challenging for MAEs since large areas of the 3D volume are empty. Consequently, existing work suffers from leaking occupancy information into the decoder and has significant computational complexity, thereby limiting the SSL pre-training to only 2D bird's eye view encoders in practice. In this work, we propose the novel neighborhood occupancy MAE (NOMAE) that overcomes the aforementioned challenges by employing masked occupancy reconstruction only in the neighborhood of non-masked voxels. We incorporate voxel masking and occupancy reconstruction at multiple scales with our proposed hierarchical mask generation technique to capture features of objects of different sizes in the point cloud. NOMAEs are extremely flexible and can be directly employed for SSL in existing 3D architectures. We perform extensive evaluations on the nuScenes and Waymo Open datasets for the downstream perception tasks of semantic segmentation and 3D object detection, comparing with both discriminative and generative SSL methods. The results demonstrate that NOMAE sets the new state-of-the-art on multiple benchmarks for multiple point cloud perception tasks.
Revisiting Out-of-Distribution Detection in LiDAR-based 3D Object Detection
Apr 24, 2024LiDAR-based 3D object detection has become an essential part of automated driving due to its ability to localize and classify objects precisely in 3D. However, object detectors face a critical challenge when dealing with unknown foreground objects, particularly those that were not present in their original training data. These out-of-distribution (OOD) objects can lead to misclassifications, posing a significant risk to the safety and reliability of automated vehicles. Currently, LiDAR-based OOD object detection has not been well studied. We address this problem by generating synthetic training data for OOD objects by perturbing known object categories. Our idea is that these synthetic OOD objects produce different responses in the feature map of an object detector compared to in-distribution (ID) objects. We then extract features using a pre-trained and fixed object detector and train a simple multilayer perceptron (MLP) to classify each detection as either ID or OOD. In addition, we propose a new evaluation protocol that allows the use of existing datasets without modifying the point cloud, ensuring a more authentic evaluation of real-world scenarios. The effectiveness of our method is validated through experiments on the newly proposed nuScenes OOD benchmark. The source code is available at https://github.com/uulm-mrm/mmood3d.
Group Regression for Query Based Object Detection and Tracking
Aug 28, 2023



Group regression is commonly used in 3D object detection to predict box parameters of similar classes in a joint head, aiming to benefit from similarities while separating highly dissimilar classes. For query-based perception methods, this has, so far, not been feasible. We close this gap and present a method to incorporate multi-class group regression, especially designed for the 3D domain in the context of autonomous driving, into existing attention and query-based perception approaches. We enhance a transformer based joint object detection and tracking model with this approach, and thoroughly evaluate its behavior and performance. For group regression, the classes of the nuScenes dataset are divided into six groups of similar shape and prevalence, each being regressed by a dedicated head. We show that the proposed method is applicable to many existing transformer based perception approaches and can bring potential benefits. The behavior of query group regression is thoroughly analyzed in comparison to a unified regression head, e.g. in terms of class-switching behavior and distribution of the output parameters. The proposed method offers many possibilities for further research, such as in the direction of deep multi-hypotheses tracking.
Sensor Visibility Estimation: Metrics and Methods for Systematic Performance Evaluation and Improvement
Nov 11, 2022



Sensor visibility is crucial for safety-critical applications in automotive, robotics, smart infrastructure and others: In addition to object detection and occupancy mapping, visibility describes where a sensor can potentially measure or is blind. This knowledge can enhance functional safety and perception algorithms or optimize sensor topologies. Despite its significance, to the best of our knowledge, neither a common definition of visibility nor performance metrics exist yet. We close this gap and provide a definition of visibility, derived from a use case review. We introduce metrics and a framework to assess the performance of visibility estimators. Our metrics are verified with labeled real-world and simulation data from infrastructure radars and cameras: The framework easily identifies false visible or false invisible estimations which are safety-critical. Applying our metrics, we enhance the radar and camera visibility estimators by modeling the 3D elevation of sensor and objects. This refinement outperforms the conventional planar 2D approach in trustfulness and thus safety.
Can Transformer Attention Spread Give Insights Into Uncertainty of Detected and Tracked Objects?
Oct 26, 2022



Transformers have recently been utilized to perform object detection and tracking in the context of autonomous driving. One unique characteristic of these models is that attention weights are computed in each forward pass, giving insights into the model's interior, in particular, which part of the input data it deemed interesting for the given task. Such an attention matrix with the input grid is available for each detected (or tracked) object in every transformer decoder layer. In this work, we investigate the distribution of these attention weights: How do they change through the decoder layers and through the lifetime of a track? Can they be used to infer additional information about an object, such as a detection uncertainty? Especially in unstructured environments, or environments that were not common during training, a reliable measure of detection uncertainty is crucial to decide whether the system can still be trusted or not.
Transformers for Object Detection in Large Point Clouds
Sep 30, 2022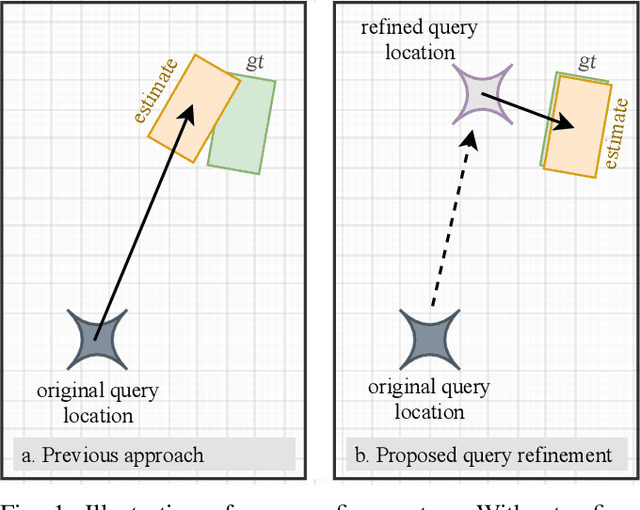
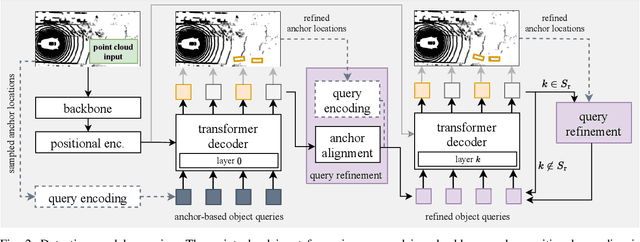
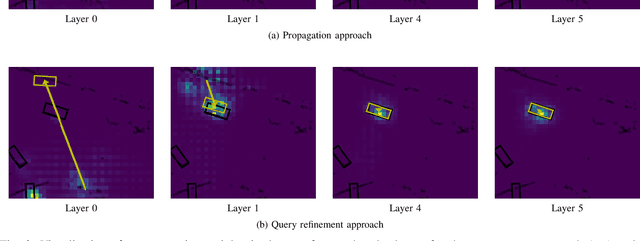
We present TransLPC, a novel detection model for large point clouds that is based on a transformer architecture. While object detection with transformers has been an active field of research, it has proved difficult to apply such models to point clouds that span a large area, e.g. those that are common in autonomous driving, with lidar or radar data. TransLPC is able to remedy these issues: The structure of the transformer model is modified to allow for larger input sequence lengths, which are sufficient for large point clouds. Besides this, we propose a novel query refinement technique to improve detection accuracy, while retaining a memory-friendly number of transformer decoder queries. The queries are repositioned between layers, moving them closer to the bounding box they are estimating, in an efficient manner. This simple technique has a significant effect on detection accuracy, which is evaluated on the challenging nuScenes dataset on real-world lidar data. Besides this, the proposed method is compatible with existing transformer-based solutions that require object detection, e.g. for joint multi-object tracking and detection, and enables them to be used in conjunction with large point clouds.
DeepFusion: A Robust and Modular 3D Object Detector for Lidars, Cameras and Radars
Sep 27, 2022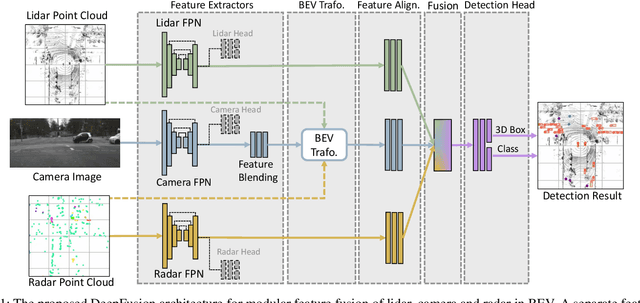
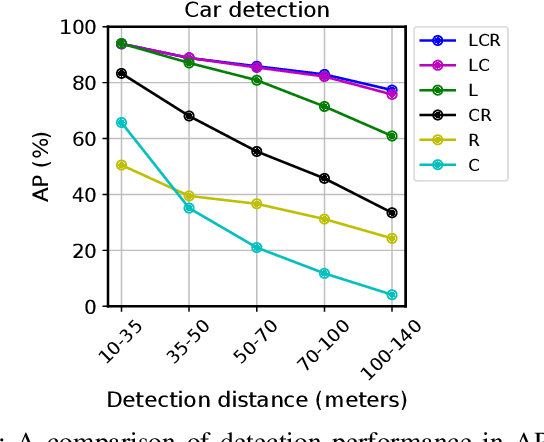
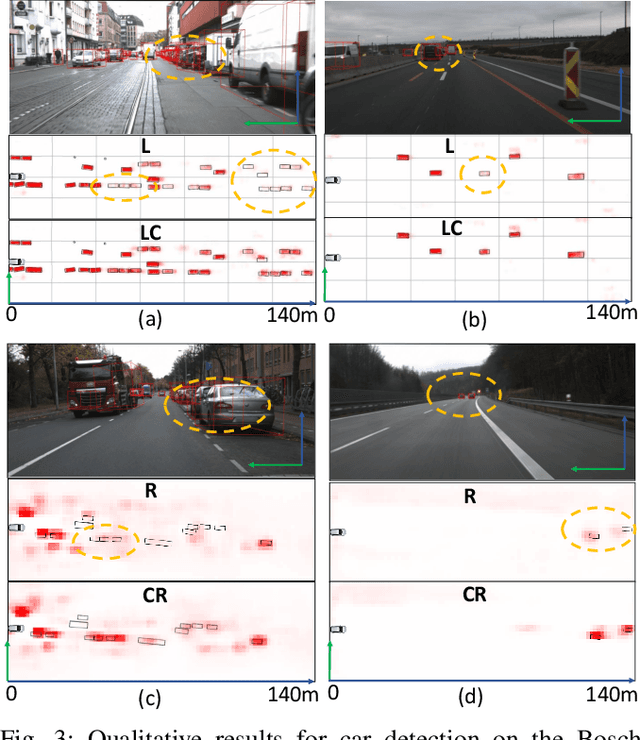
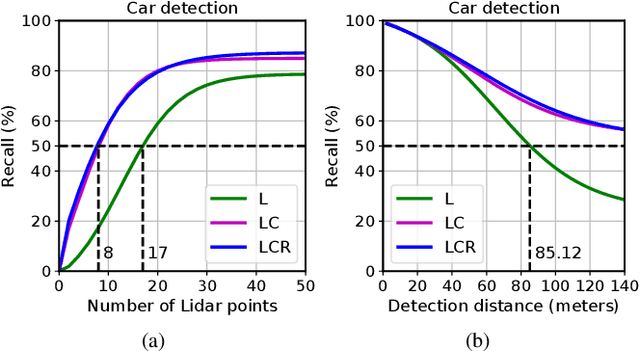
We propose DeepFusion, a modular multi-modal architecture to fuse lidars, cameras and radars in different combinations for 3D object detection. Specialized feature extractors take advantage of each modality and can be exchanged easily, making the approach simple and flexible. Extracted features are transformed into bird's-eye-view as a common representation for fusion. Spatial and semantic alignment is performed prior to fusing modalities in the feature space. Finally, a detection head exploits rich multi-modal features for improved 3D detection performance. Experimental results for lidar-camera, lidar-camera-radar and camera-radar fusion show the flexibility and effectiveness of our fusion approach. In the process, we study the largely unexplored task of faraway car detection up to 225 meters, showing the benefits of our lidar-camera fusion. Furthermore, we investigate the required density of lidar points for 3D object detection and illustrate implications at the example of robustness against adverse weather conditions. Moreover, ablation studies on our camera-radar fusion highlight the importance of accurate depth estimation.
Self-Supervised Velocity Estimation for Automotive Radar Object Detection Networks
Jul 07, 2022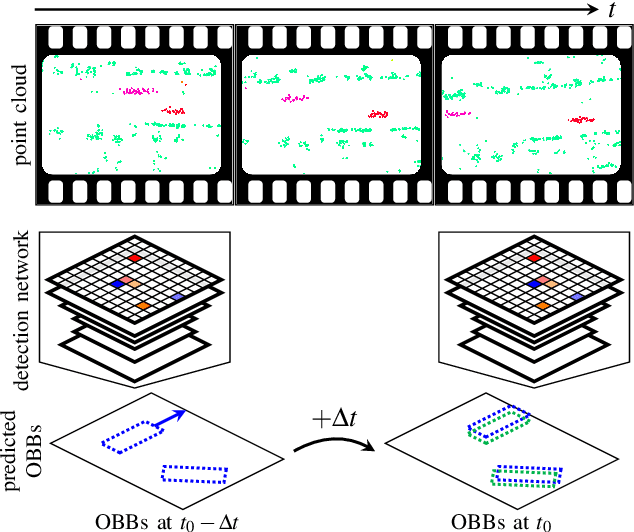
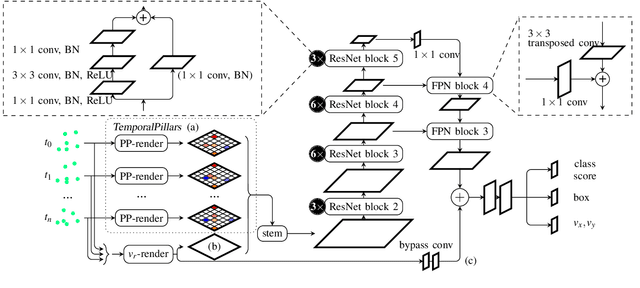
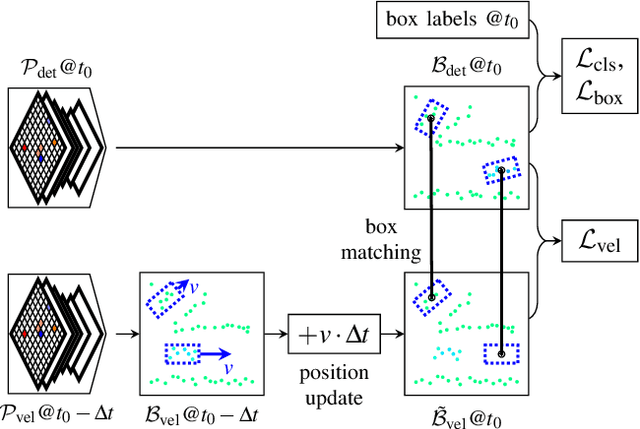
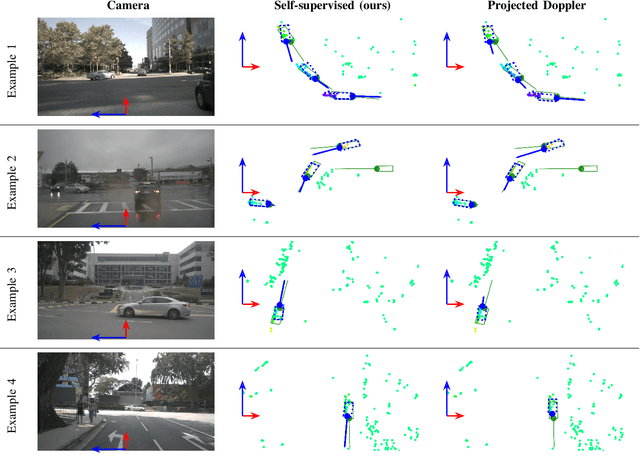
This paper presents a method to learn the Cartesian velocity of objects using an object detection network on automotive radar data. The proposed method is self-supervised in terms of generating its own training signal for the velocities. Labels are only required for single-frame, oriented bounding boxes (OBBs). Labels for the Cartesian velocities or contiguous sequences, which are expensive to obtain, are not required. The general idea is to pre-train an object detection network without velocities using single-frame OBB labels, and then exploit the network's OBB predictions on unlabelled data for velocity training. In detail, the network's OBB predictions of the unlabelled frames are updated to the timestamp of a labelled frame using the predicted velocities and the distances between the updated OBBs of the unlabelled frame and the OBB predictions of the labelled frame are used to generate a self-supervised training signal for the velocities. The detection network architecture is extended by a module to account for the temporal relation of multiple scans and a module to represent the radars' radial velocity measurements explicitly. A two-step approach of first training only OBB detection, followed by training OBB detection and velocities is used. Further, a pre-training with pseudo-labels generated from radar radial velocity measurements bootstraps the self-supervised method of this paper. Experiments on the publicly available nuScenes dataset show that the proposed method almost reaches the velocity estimation performance of a fully supervised training, but does not require expensive velocity labels. Furthermore, we outperform a baseline method which uses only radial velocity measurements as labels.