 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Regression for Query Based Object Detection and Tracking
Aug 28, 2023Group regression is commonly used in 3D object detection to predict box parameters of similar classes in a joint head, aiming to benefit from similarities while separating highly dissimilar classes. For query-based perception methods, this has, so far, not been feasible. We close this gap and present a method to incorporate multi-class group regression, especially designed for the 3D domain in the context of autonomous driving, into existing attention and query-based perception approaches. We enhance a transformer based joint object detection and tracking model with this approach, and thoroughly evaluate its behavior and performance. For group regression, the classes of the nuScenes dataset are divided into six groups of similar shape and prevalence, each being regressed by a dedicated head. We show that the proposed method is applicable to many existing transformer based perception approaches and can bring potential benefits. The behavior of query group regression is thoroughly analyzed in comparison to a unified regression head, e.g. in terms of class-switching behavior and distribution of the output parameters. The proposed method offers many possibilities for further research, such as in the direction of deep multi-hypotheses tracking.
Can Transformer Attention Spread Give Insights Into Uncertainty of Detected and Tracked Objects?
Oct 26, 2022



Transformers have recently been utilized to perform object detection and tracking in the context of autonomous driving. One unique characteristic of these models is that attention weights are computed in each forward pass, giving insights into the model's interior, in particular, which part of the input data it deemed interesting for the given task. Such an attention matrix with the input grid is available for each detected (or tracked) object in every transformer decoder layer. In this work, we investigate the distribution of these attention weights: How do they change through the decoder layers and through the lifetime of a track? Can they be used to infer additional information about an object, such as a detection uncertainty? Especially in unstructured environments, or environments that were not common during training, a reliable measure of detection uncertainty is crucial to decide whether the system can still be trusted or not.
Transformers for Object Detection in Large Point Clouds
Sep 30, 2022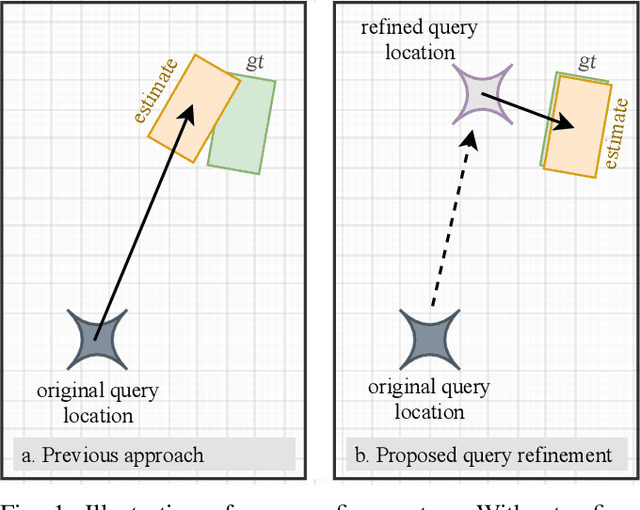
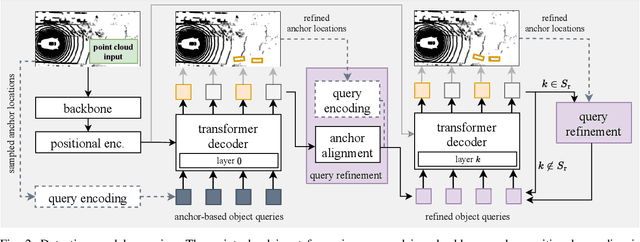
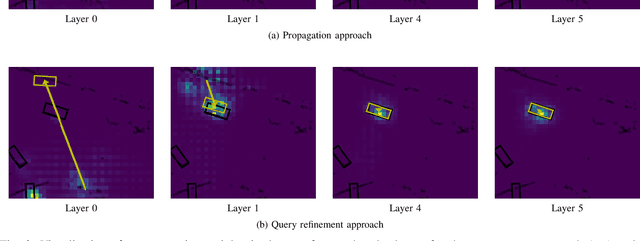
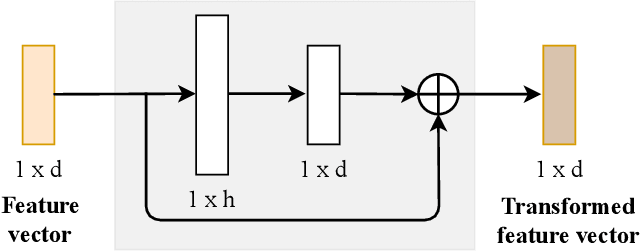
We present TransLPC, a novel detection model for large point clouds that is based on a transformer architecture. While object detection with transformers has been an active field of research, it has proved difficult to apply such models to point clouds that span a large area, e.g. those that are common in autonomous driving, with lidar or radar data. TransLPC is able to remedy these issues: The structure of the transformer model is modified to allow for larger input sequence lengths, which are sufficient for large point clouds. Besides this, we propose a novel query refinement technique to improve detection accuracy, while retaining a memory-friendly number of transformer decoder queries. The queries are repositioned between layers, moving them closer to the bounding box they are estimating, in an efficient manner. This simple technique has a significant effect on detection accuracy, which is evaluated on the challenging nuScenes dataset on real-world lidar data. Besides this, the proposed method is compatible with existing transformer-based solutions that require object detection, e.g. for joint multi-object tracking and detection, and enables them to be used in conjunction with large point clouds.
DeepFusion: A Robust and Modular 3D Object Detector for Lidars, Cameras and Radars
Sep 27, 2022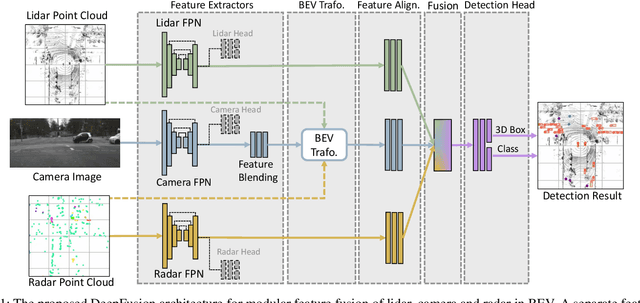
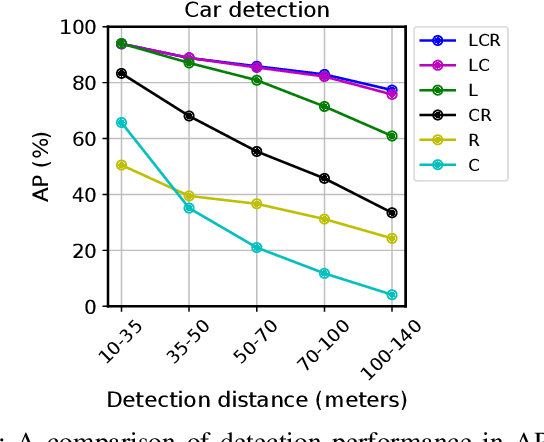
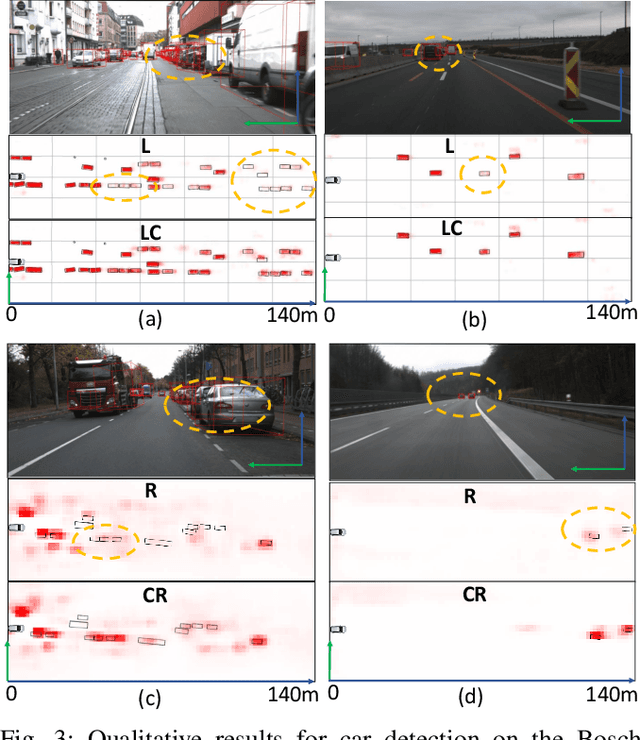
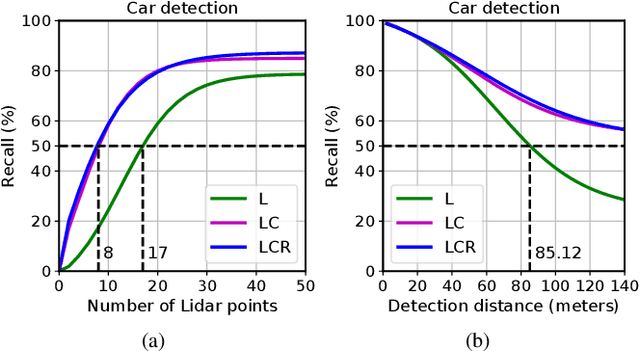
We propose DeepFusion, a modular multi-modal architecture to fuse lidars, cameras and radars in different combinations for 3D object detection. Specialized feature extractors take advantage of each modality and can be exchanged easily, making the approach simple and flexible. Extracted features are transformed into bird's-eye-view as a common representation for fusion. Spatial and semantic alignment is performed prior to fusing modalities in the feature space. Finally, a detection head exploits rich multi-modal features for improved 3D detection performance. Experimental results for lidar-camera, lidar-camera-radar and camera-radar fusion show the flexibility and effectiveness of our fusion approach. In the process, we study the largely unexplored task of faraway car detection up to 225 meters, showing the benefits of our lidar-camera fusion. Furthermore, we investigate the required density of lidar points for 3D object detection and illustrate implications at the example of robustness against adverse weather conditions. Moreover, ablation studies on our camera-radar fusion highlight the importance of accurate depth estimation.
Self-Supervised Velocity Estimation for Automotive Radar Object Detection Networks
Jul 07, 2022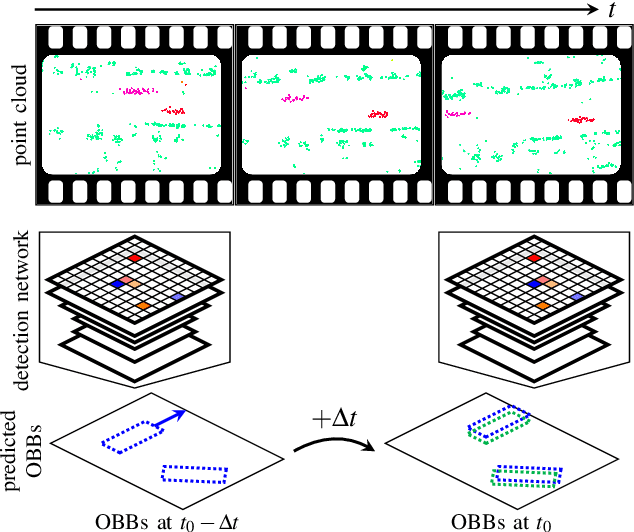
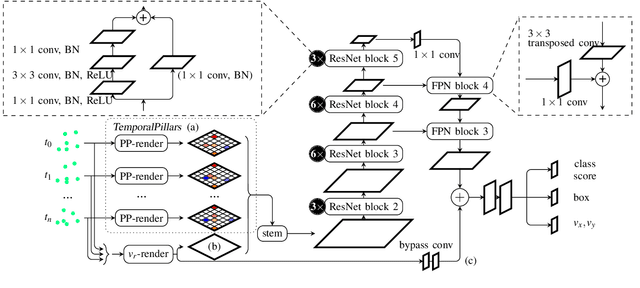
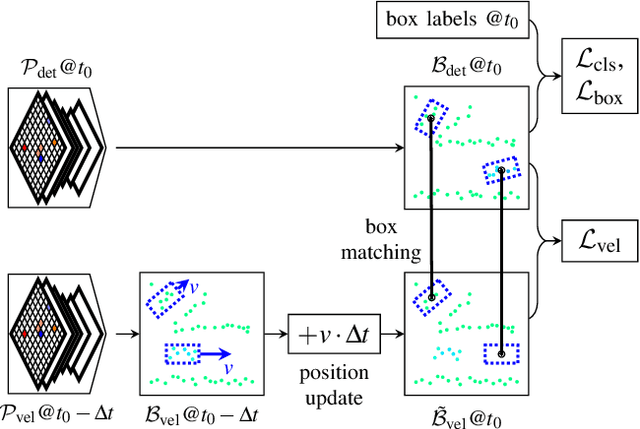
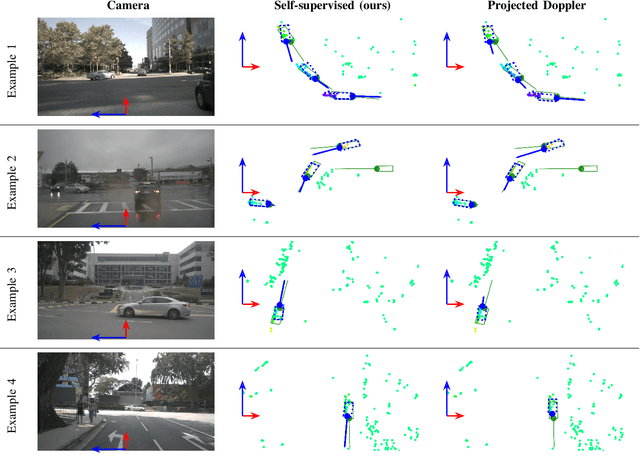
This paper presents a method to learn the Cartesian velocity of objects using an object detection network on automotive radar data. The proposed method is self-supervised in terms of generating its own training signal for the velocities. Labels are only required for single-frame, oriented bounding boxes (OBBs). Labels for the Cartesian velocities or contiguous sequences, which are expensive to obtain, are not required. The general idea is to pre-train an object detection network without velocities using single-frame OBB labels, and then exploit the network's OBB predictions on unlabelled data for velocity training. In detail, the network's OBB predictions of the unlabelled frames are updated to the timestamp of a labelled frame using the predicted velocities and the distances between the updated OBBs of the unlabelled frame and the OBB predictions of the labelled frame are used to generate a self-supervised training signal for the velocities. The detection network architecture is extended by a module to account for the temporal relation of multiple scans and a module to represent the radars' radial velocity measurements explicitly. A two-step approach of first training only OBB detection, followed by training OBB detection and velocities is used. Further, a pre-training with pseudo-labels generated from radar radial velocity measurements bootstraps the self-supervised method of this paper. Experiments on the publicly available nuScenes dataset show that the proposed method almost reaches the velocity estimation performance of a fully supervised training, but does not require expensive velocity labels. Furthermore, we outperform a baseline method which uses only radial velocity measurements as labels.
Transformers for Multi-Object Tracking on Point Clouds
May 31, 2022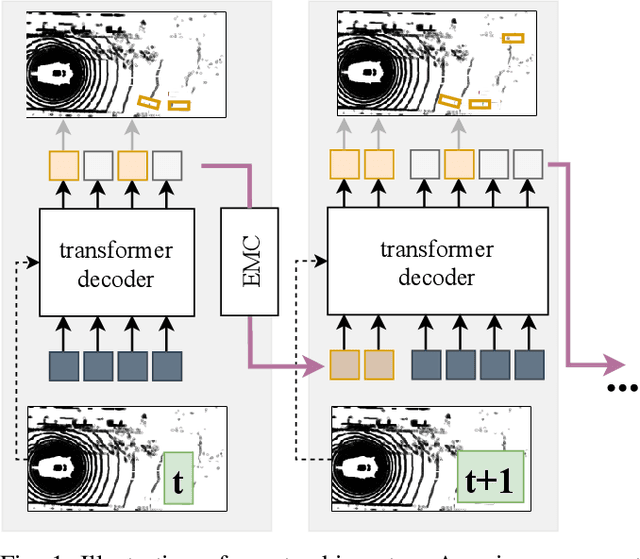
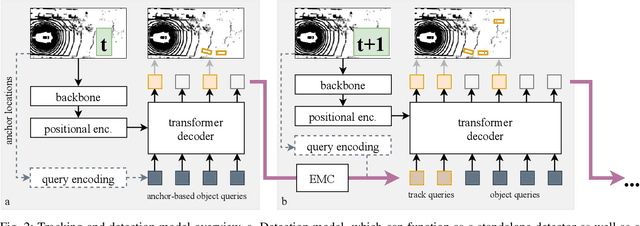
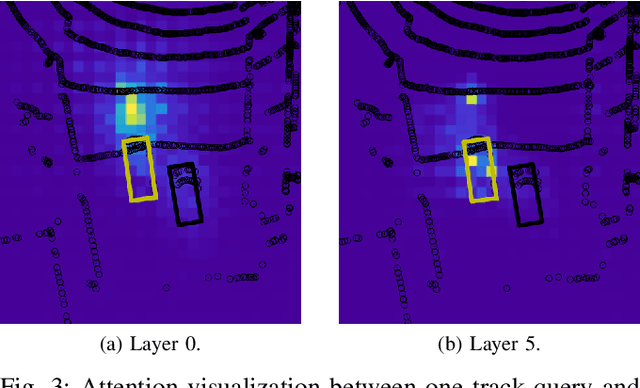
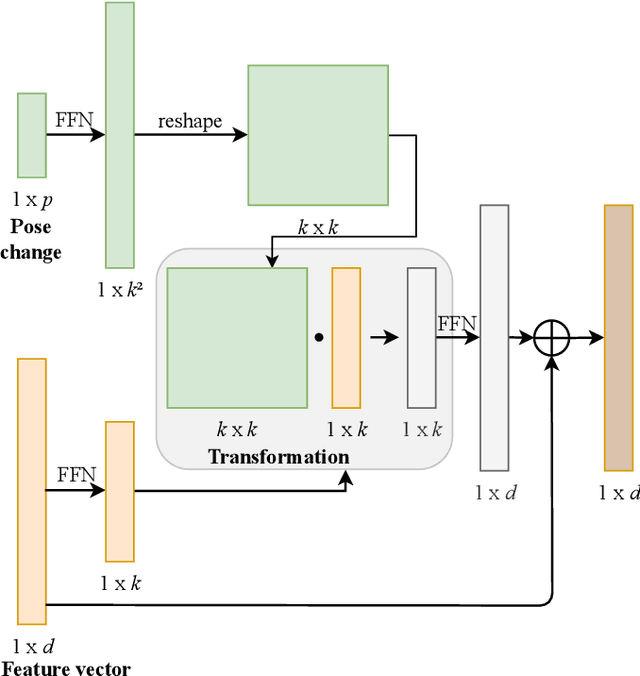
We present TransMOT, a novel transformer-based end-to-end trainable online tracker and detector for point cloud data. The model utilizes a cross- and a self-attention mechanism and is applicable to lidar data in an automotive context, as well as other data types, such as radar. Both track management and the detection of new tracks are performed by the same transformer decoder module and the tracker state is encoded in feature space. With this approach, we make use of the rich latent space of the detector for tracking rather than relying on low-dimensional bounding boxes. Still, we are able to retain some of the desirable properties of traditional Kalman-filter based approaches, such as an ability to handle sensor input at arbitrary timesteps or to compensate frame skips. This is possible due to a novel module that transforms the track information from one frame to the next on feature-level and thereby fulfills a similar task as the prediction step of a Kalman filter. Results are presented on the challenging real-world dataset nuScenes, where the proposed model outperforms its Kalman filter-based tracking baseline.
Improved Orientation Estimation and Detection with Hybrid Object Detection Networks for Automotive Radar
May 03, 2022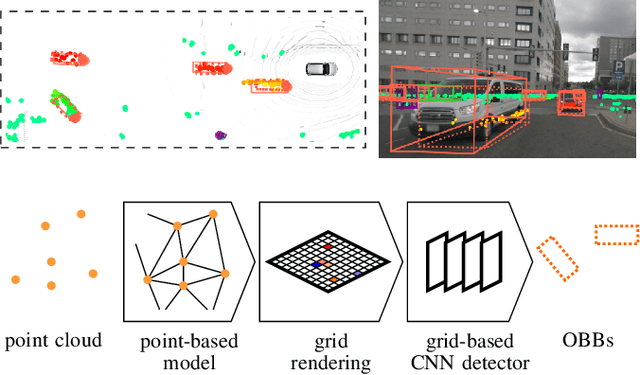
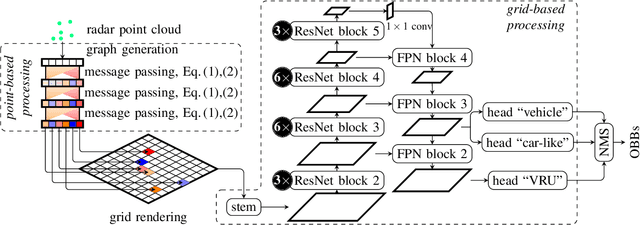

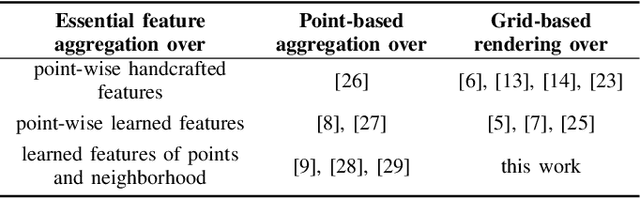
This paper presents novel hybrid architectures that combine grid- and point-based processing to improve the detection performance and orientation estimation of radar-based object detection networks. Purely grid-based detection models operate on a bird's-eye-view (BEV) projection of the input point cloud. These approaches suffer from a loss of detailed information through the discrete grid resolution. This applies in particular to radar object detection, where relatively coarse grid resolutions are commonly used to account for the sparsity of radar point clouds. In contrast, point-based models are not affected by this problem as they continuously process point clouds. However, they generally exhibit worse detection performances than grid-based methods. We show that a point-based model can extract neighborhood features, leveraging the exact relative positions of points, before grid rendering. This has significant benefits for a following convolutional detection backbone. In experiments on the public nuScenes dataset our hybrid architecture achieves improvements in terms of detection performance and orientation estimates over networks from previous literature.
Understanding the Domain Gap in LiDAR Object Detection Networks
Apr 21, 2022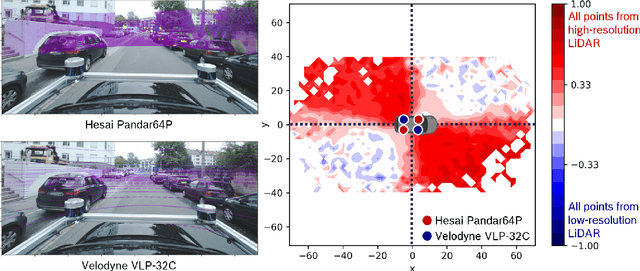
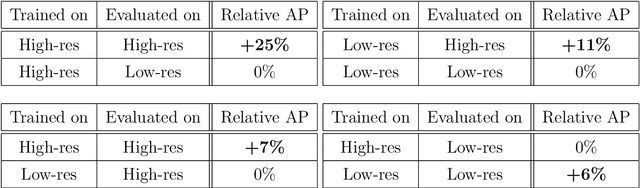
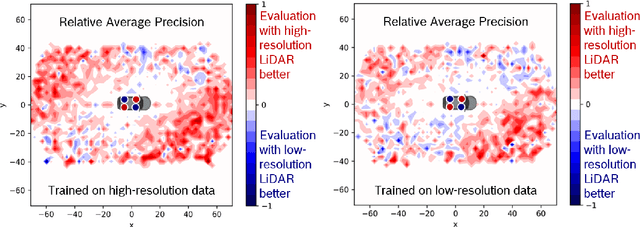
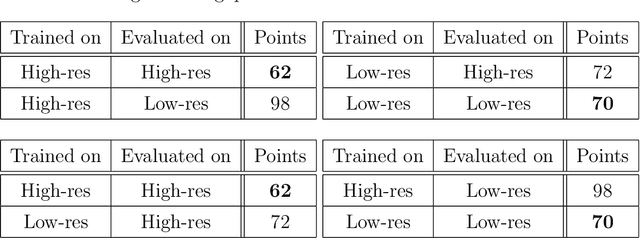
In order to make autonomous driving a reality, artificial neural networks have to work reliably in the open-world. However, the open-world is vast and continuously changing, so it is not technically feasible to collect and annotate training datasets which accurately represent this domain. Therefore, there are always domain gaps between training datasets and the open-world which must be understood. In this work, we investigate the domain gaps between high-resolution and low-resolution LiDAR sensors in object detection networks. Using a unique dataset, which enables us to study sensor resolution domain gaps independent of other effects, we show two distinct domain gaps - an inference domain gap and a training domain gap. The inference domain gap is characterised by a strong dependence on the number of LiDAR points per object, while the training gap shows no such dependence. These fndings show that different approaches are required to close these inference and training domain gaps.
Three-dimensional Simultaneous Shape and Pose Estimation for Extended Objects Using Spherical Harmonics
Dec 25, 2020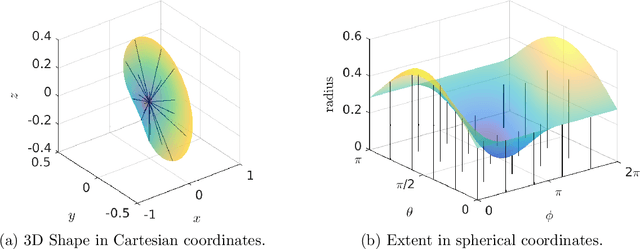
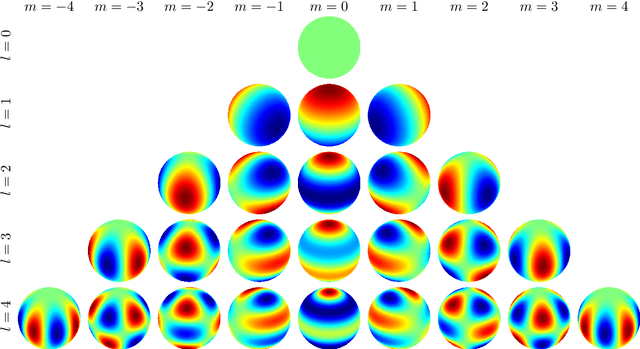
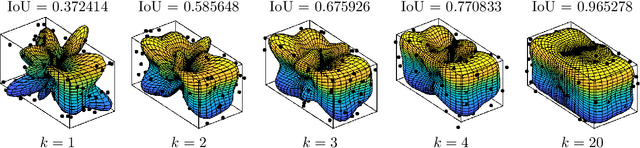
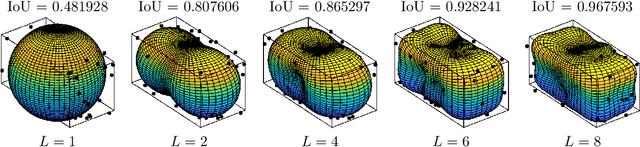
We propose a new recursive method for simultaneous estimation of both the pose and the shape of a three-dimensional extended object. The key idea of the presented method is to represent the shape of the object using spherical harmonics, similar to the way Fourier series can be used in the two-dimensional case. This allows us to derive a measurement equation that can be used within the framework of nonlinear filters such as the UKF. We provide both simulative and experimental evaluations of the novel techniques.