 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Velocity Estimation for Automotive Radar Object Detection Networks
Jul 07, 2022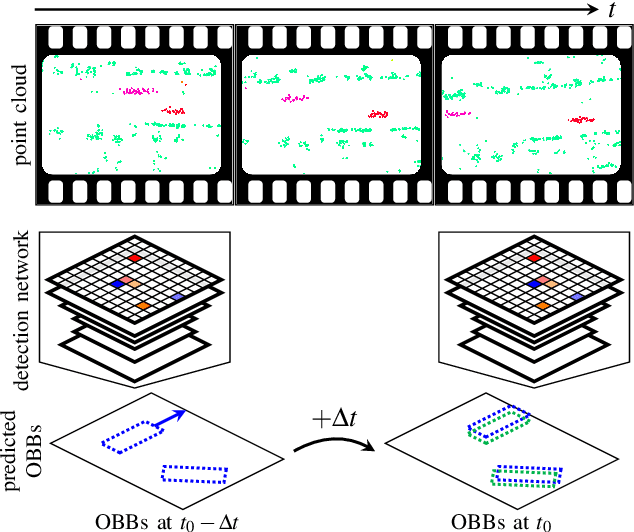
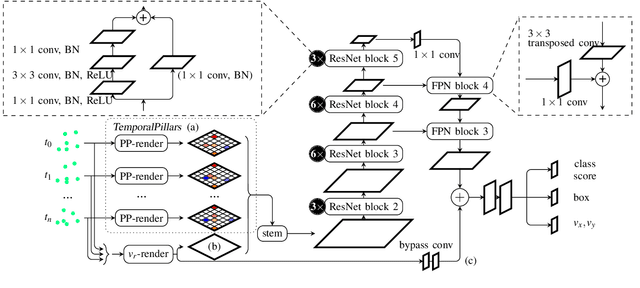
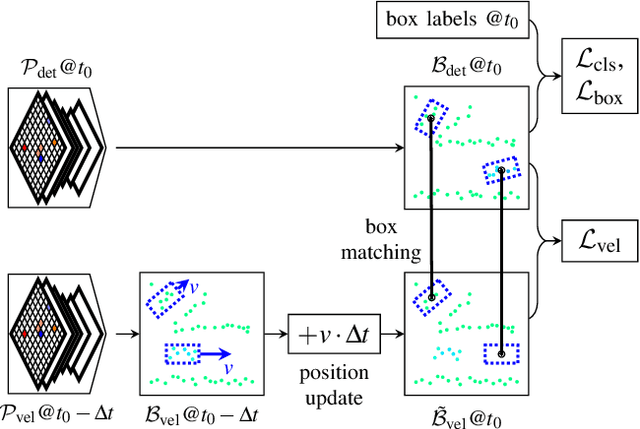
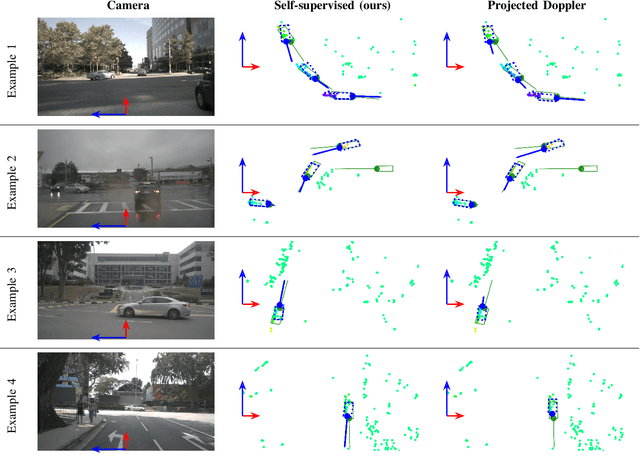
This paper presents a method to learn the Cartesian velocity of objects using an object detection network on automotive radar data. The proposed method is self-supervised in terms of generating its own training signal for the velocities. Labels are only required for single-frame, oriented bounding boxes (OBBs). Labels for the Cartesian velocities or contiguous sequences, which are expensive to obtain, are not required. The general idea is to pre-train an object detection network without velocities using single-frame OBB labels, and then exploit the network's OBB predictions on unlabelled data for velocity training. In detail, the network's OBB predictions of the unlabelled frames are updated to the timestamp of a labelled frame using the predicted velocities and the distances between the updated OBBs of the unlabelled frame and the OBB predictions of the labelled frame are used to generate a self-supervised training signal for the velocities. The detection network architecture is extended by a module to account for the temporal relation of multiple scans and a module to represent the radars' radial velocity measurements explicitly. A two-step approach of first training only OBB detection, followed by training OBB detection and velocities is used. Further, a pre-training with pseudo-labels generated from radar radial velocity measurements bootstraps the self-supervised method of this paper. Experiments on the publicly available nuScenes dataset show that the proposed method almost reaches the velocity estimation performance of a fully supervised training, but does not require expensive velocity labels. Furthermore, we outperform a baseline method which uses only radial velocity measurements as labels.
Improved Orientation Estimation and Detection with Hybrid Object Detection Networks for Automotive Radar
May 03, 2022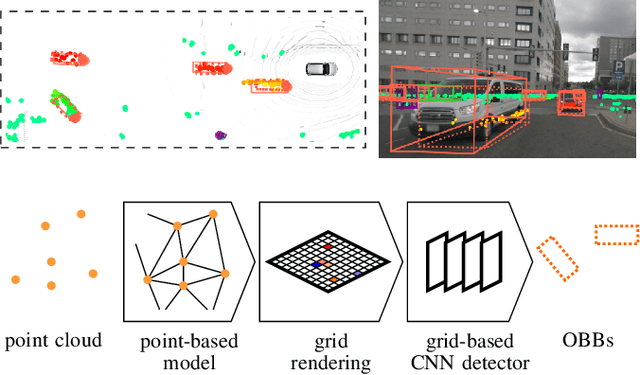
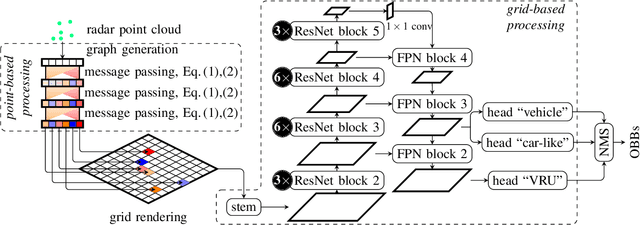

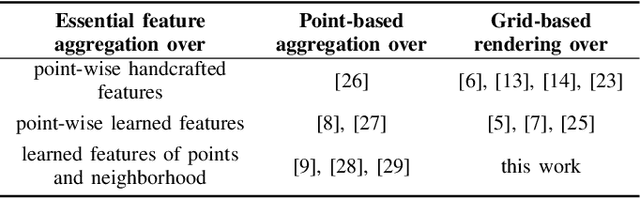
This paper presents novel hybrid architectures that combine grid- and point-based processing to improve the detection performance and orientation estimation of radar-based object detection networks. Purely grid-based detection models operate on a bird's-eye-view (BEV) projection of the input point cloud. These approaches suffer from a loss of detailed information through the discrete grid resolution. This applies in particular to radar object detection, where relatively coarse grid resolutions are commonly used to account for the sparsity of radar point clouds. In contrast, point-based models are not affected by this problem as they continuously process point clouds. However, they generally exhibit worse detection performances than grid-based methods. We show that a point-based model can extract neighborhood features, leveraging the exact relative positions of points, before grid rendering. This has significant benefits for a following convolutional detection backbone. In experiments on the public nuScenes dataset our hybrid architecture achieves improvements in terms of detection performance and orientation estimates over networks from previous literature.