 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Object Query Initialization for 3D Object Detection
Oct 16, 2023



3D object detection models that exploit both LiDAR and camera sensor features are top performers in large-scale autonomous driving benchmarks. A transformer is a popular network architecture used for this task, in which so-called object queries act as candidate objects. Initializing these object queries based on current sensor inputs is a common practice. For this, existing methods strongly rely on LiDAR data however, and do not fully exploit image features. Besides, they introduce significant latency. To overcome these limitations we propose EfficientQ3M, an efficient, modular, and multimodal solution for object query initialization for transformer-based 3D object detection models. The proposed initialization method is combined with a "modality-balanced" transformer decoder where the queries can access all sensor modalities throughout the decoder. In experiments, we outperform the state of the art in transformer-based LiDAR object detection on the competitive nuScenes benchmark and showcase the benefits of input-dependent multimodal query initialization, while being more efficient than the available alternatives for LiDAR-camera initialization. The proposed method can be applied with any combination of sensor modalities as input, demonstrating its modularity.
Group Regression for Query Based Object Detection and Tracking
Aug 28, 2023



Group regression is commonly used in 3D object detection to predict box parameters of similar classes in a joint head, aiming to benefit from similarities while separating highly dissimilar classes. For query-based perception methods, this has, so far, not been feasible. We close this gap and present a method to incorporate multi-class group regression, especially designed for the 3D domain in the context of autonomous driving, into existing attention and query-based perception approaches. We enhance a transformer based joint object detection and tracking model with this approach, and thoroughly evaluate its behavior and performance. For group regression, the classes of the nuScenes dataset are divided into six groups of similar shape and prevalence, each being regressed by a dedicated head. We show that the proposed method is applicable to many existing transformer based perception approaches and can bring potential benefits. The behavior of query group regression is thoroughly analyzed in comparison to a unified regression head, e.g. in terms of class-switching behavior and distribution of the output parameters. The proposed method offers many possibilities for further research, such as in the direction of deep multi-hypotheses tracking.
Can Transformer Attention Spread Give Insights Into Uncertainty of Detected and Tracked Objects?
Oct 26, 2022



Transformers have recently been utilized to perform object detection and tracking in the context of autonomous driving. One unique characteristic of these models is that attention weights are computed in each forward pass, giving insights into the model's interior, in particular, which part of the input data it deemed interesting for the given task. Such an attention matrix with the input grid is available for each detected (or tracked) object in every transformer decoder layer. In this work, we investigate the distribution of these attention weights: How do they change through the decoder layers and through the lifetime of a track? Can they be used to infer additional information about an object, such as a detection uncertainty? Especially in unstructured environments, or environments that were not common during training, a reliable measure of detection uncertainty is crucial to decide whether the system can still be trusted or not.
Transformers for Object Detection in Large Point Clouds
Sep 30, 2022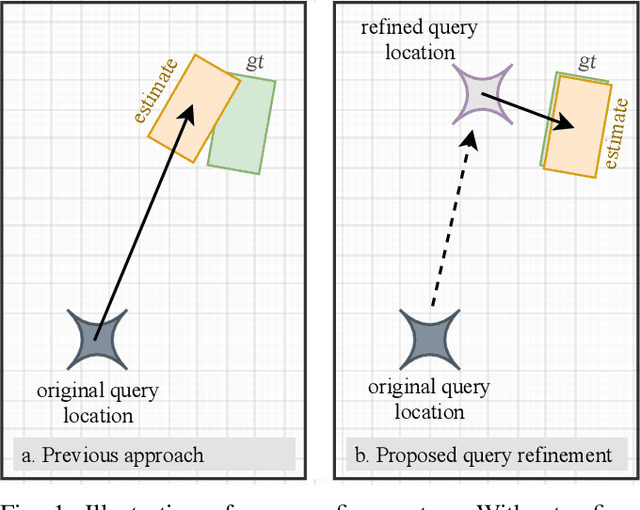
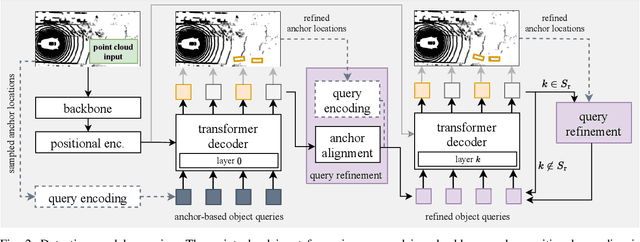
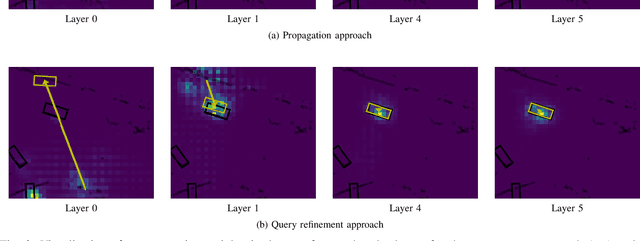
We present TransLPC, a novel detection model for large point clouds that is based on a transformer architecture. While object detection with transformers has been an active field of research, it has proved difficult to apply such models to point clouds that span a large area, e.g. those that are common in autonomous driving, with lidar or radar data. TransLPC is able to remedy these issues: The structure of the transformer model is modified to allow for larger input sequence lengths, which are sufficient for large point clouds. Besides this, we propose a novel query refinement technique to improve detection accuracy, while retaining a memory-friendly number of transformer decoder queries. The queries are repositioned between layers, moving them closer to the bounding box they are estimating, in an efficient manner. This simple technique has a significant effect on detection accuracy, which is evaluated on the challenging nuScenes dataset on real-world lidar data. Besides this, the proposed method is compatible with existing transformer-based solutions that require object detection, e.g. for joint multi-object tracking and detection, and enables them to be used in conjunction with large point clouds.
Transformers for Multi-Object Tracking on Point Clouds
May 31, 2022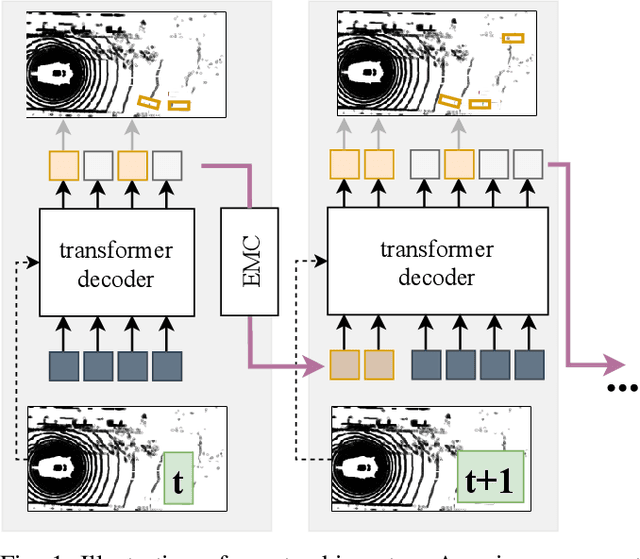
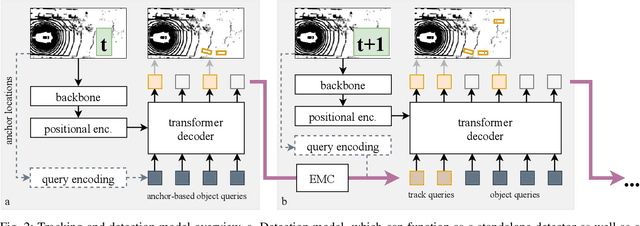
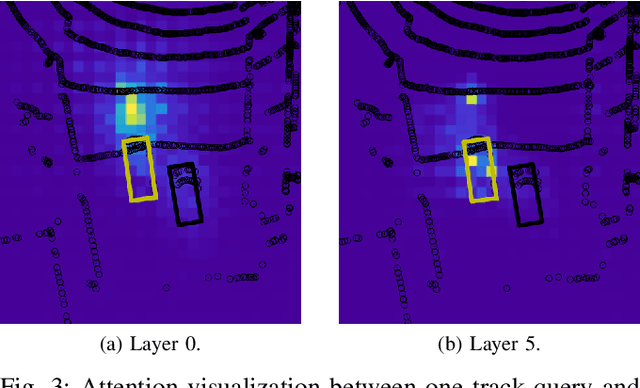
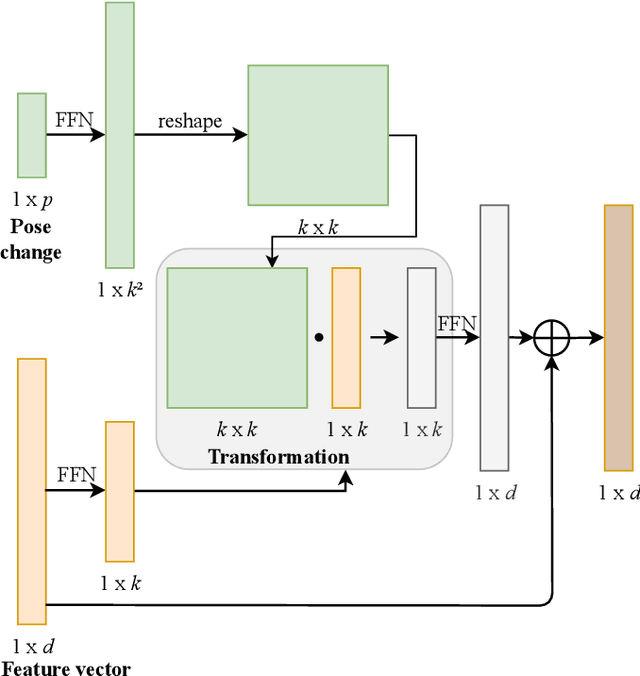
We present TransMOT, a novel transformer-based end-to-end trainable online tracker and detector for point cloud data. The model utilizes a cross- and a self-attention mechanism and is applicable to lidar data in an automotive context, as well as other data types, such as radar. Both track management and the detection of new tracks are performed by the same transformer decoder module and the tracker state is encoded in feature space. With this approach, we make use of the rich latent space of the detector for tracking rather than relying on low-dimensional bounding boxes. Still, we are able to retain some of the desirable properties of traditional Kalman-filter based approaches, such as an ability to handle sensor input at arbitrary timesteps or to compensate frame skips. This is possible due to a novel module that transforms the track information from one frame to the next on feature-level and thereby fulfills a similar task as the prediction step of a Kalman filter. Results are presented on the challenging real-world dataset nuScenes, where the proposed model outperforms its Kalman filter-based tracking baseline.