 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOOD: Exploiting Language Representations for LiDAR-based Out-of-Distribution Object Detection
Mar 09, 2026LiDAR-based 3D object detection plays a critical role for reliable and safe autonomous driving systems. However, existing detectors often produce overly confident predictions for objects not belonging to known categories, posing significant safety risks. This is caused by so-called out-of-distribution (OOD) objects, which were not part of the training data, resulting in incorrect predictions. To address this challenge, we propose ALOOD (Aligned LiDAR representations for Out-Of-Distribution Detection), a novel approach that incorporates language representations from a vision-language model (VLM). By aligning the object features from the object detector to the feature space of the VLM, we can treat the detection of OOD objects as a zero-shot classification task. We demonstrate competitive performance on the nuScenes OOD benchmark, establishing a novel approach to OOD object detection in LiDAR using language representations. The source code is available at https://github.com/uulm-mrm/mmood3d.
Revisiting Out-of-Distribution Detection in LiDAR-based 3D Object Detection
Apr 24, 2024LiDAR-based 3D object detection has become an essential part of automated driving due to its ability to localize and classify objects precisely in 3D. However, object detectors face a critical challenge when dealing with unknown foreground objects, particularly those that were not present in their original training data. These out-of-distribution (OOD) objects can lead to misclassifications, posing a significant risk to the safety and reliability of automated vehicles. Currently, LiDAR-based OOD object detection has not been well studied. We address this problem by generating synthetic training data for OOD objects by perturbing known object categories. Our idea is that these synthetic OOD objects produce different responses in the feature map of an object detector compared to in-distribution (ID) objects. We then extract features using a pre-trained and fixed object detector and train a simple multilayer perceptron (MLP) to classify each detection as either ID or OOD. In addition, we propose a new evaluation protocol that allows the use of existing datasets without modifying the point cloud, ensuring a more authentic evaluation of real-world scenarios. The effectiveness of our method is validated through experiments on the newly proposed nuScenes OOD benchmark. The source code is available at https://github.com/uulm-mrm/mmood3d.
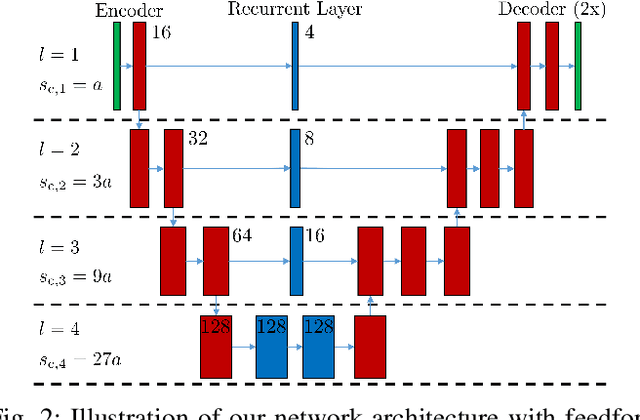
A Multi-Task Recurrent Neural Network for End-to-End Dynamic Occupancy Grid Mapping
Feb 09, 2022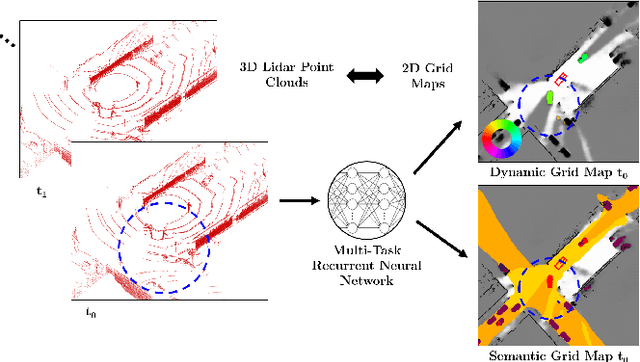

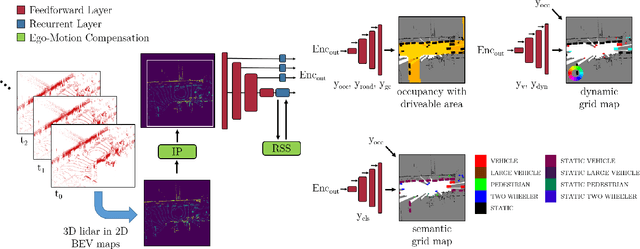

A common approach for modeling the environment of an autonomous vehicle are dynamic occupancy grid maps, in which the surrounding is divided into cells, each containing the occupancy and velocity state of its location. Despite the advantage of modeling arbitrary shaped objects, the used algorithms rely on hand-designed inverse sensor models and semantic information is missing. Therefore, we introduce a multi-task recurrent neural network to predict grid maps providing occupancies, velocity estimates, semantic information and the driveable area. During training, our network architecture, which is a combination of convolutional and recurrent layers, processes sequences of raw lidar data, that is represented as bird's eye view images with several height channels. The multi-task network is trained in an end-to-end fashion to predict occupancy grid maps without the usual preprocessing steps consisting of removing ground points and applying an inverse sensor model. In our evaluations, we show that our learned inverse sensor model is able to overcome some limitations of a geometric inverse sensor model in terms of representing object shapes and modeling freespace. Moreover, we report a better runtime performance and more accurate semantic predictions for our end-to-end approach, compared to our network relying on measurement grid maps as input data.
Dynamic Occupancy Grid Mapping with Recurrent Neural Networks
Nov 17, 2020
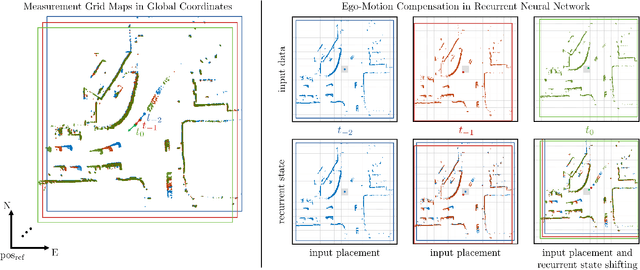

Modeling and understanding the environment is an essential task for autonomous driving. In addition to the detection of objects, in complex traffic scenarios the motion of other road participants is of special interest. Therefore, we propose to use a recurrent neural network to predict a dynamic occupancy grid map, which divides the vehicle surrounding in cells, each containing the occupancy probability and a velocity estimate. During training, our network is fed with sequences of measurement grid maps, which encode the lidar measurements of a single time step. Due to the combination of convolutional and recurrent layers, our approach is capable to use spatial and temporal information for the robust detection of static and dynamic environment. In order to apply our approach with measurements from a moving ego-vehicle, we propose a method for ego-motion compensation that is applicable in neural network architectures with recurrent layers working on different resolutions. In our evaluations, we compare our approach with a state-of-the-art particle-based algorithm on a large publicly available dataset to demonstrate the improved accuracy of velocity estimates and the more robust separation of the environment in static and dynamic area. Additionally, we show that our proposed method for ego-motion compensation leads to comparable results in scenarios with stationary and with moving ego-vehicle.
Motion Estimation in Occupancy Grid Maps in Stationary Settings Using Recurrent Neural Networks
Sep 25, 2019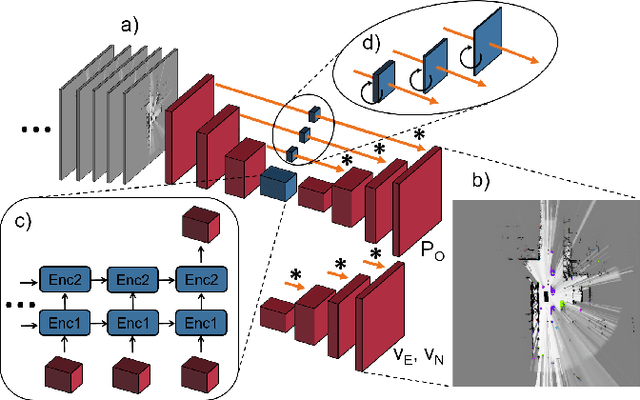

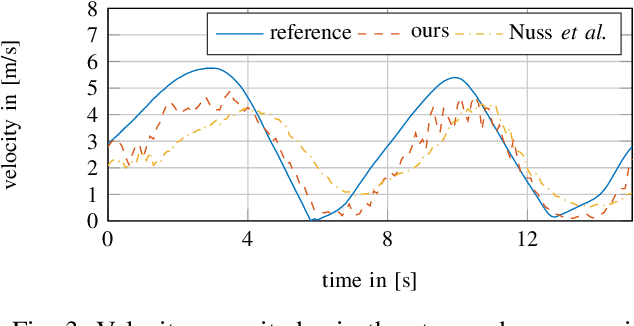
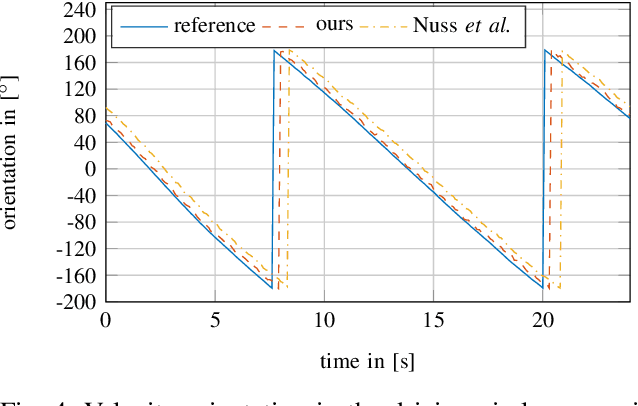
In this work, we tackle the problem of modeling the vehicle environment as dynamic occupancy grid map in complex urban scenarios using recurrent neural networks. Dynamic occupancy grid maps represent the scene in a bird's eye view, where each grid cell contains the occupancy probability and the two dimensional velocity. As input data, our approach relies on measurement grid maps, which contain occupancy probabilities, generated with lidar measurements. Given this configuration, we propose a recurrent neural network architecture to predict a dynamic occupancy grid map, i.e. filtered occupancy and velocity of each cell, by using a sequence of measurement grid maps. Our network architecture contains convolutional long-short term memories in order to sequentially process the input, makes use of spatial context, and captures motion. In the evaluation, we quantify improvements in estimating the velocity of braking and turning vehicles compared to the state-of-the-art. Additionally, we demonstrate that our approach provides more consistent velocity estimates for dynamic objects, as well as, less erroneous velocity estimates in static area.
Long-Term Occupancy Grid Prediction Using Recurrent Neural Networks
Sep 11, 2018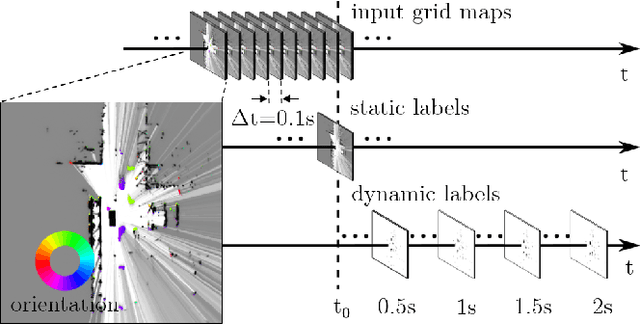
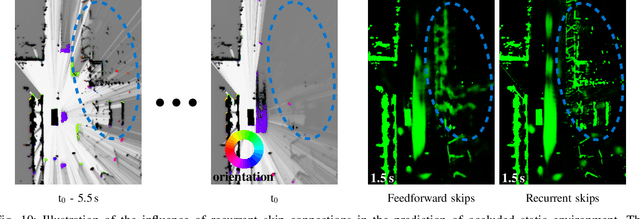
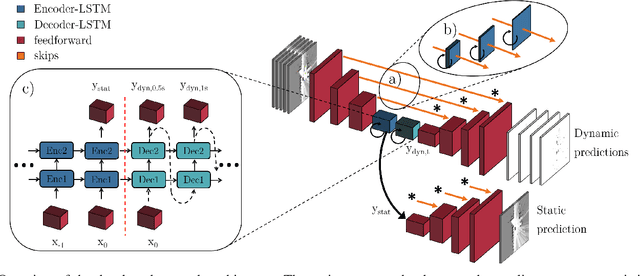
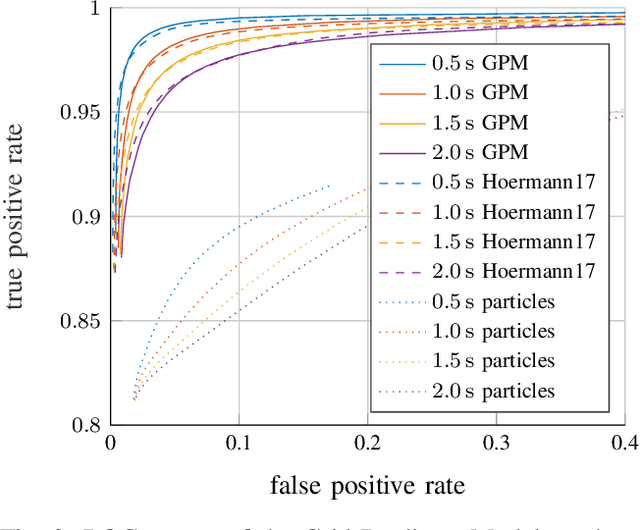
We tackle the long-term prediction of scene evolution in a complex downtown scenario for automated driving based on Lidar grid fusion and recurrent neural networks (RNNs). A bird's eye view of the scene, including occupancy and velocity, is fed as a sequence to a RNN which is trained to predict future occupancy. The nature of prediction allows generation of multiple hours of training data without the need of manual labeling. Thus, the training strategy and loss function is designed for long sequences of real-world data (unbalanced, continuously changing situations, false labels, etc.). The deep CNN architecture comprises convolutional long short-term memories (ConvLSTMs) to separate static from dynamic regions and to predict dynamic objects in future frames. Novel recurrent skip connections show the ability to predict small occluded objects, i.e. pedestrians, and occluded static regions. Spatio-temporal correlations between grid cells are exploited to predict multimodal future paths and interactions between objects. Experiments also quantify improvements to our previous network, a Monte Carlo approach, and literature.