 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Recurrent Neural Network for End-to-End Dynamic Occupancy Grid Mapping
Paper and Code
Feb 09, 2022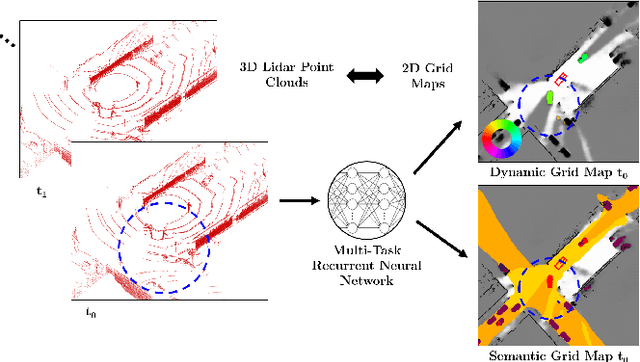

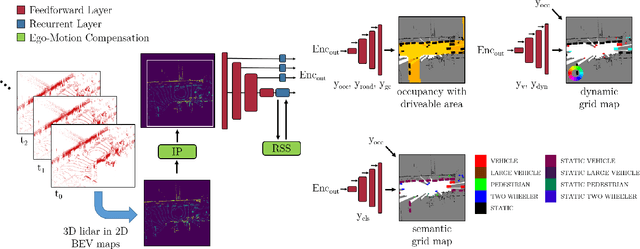

A common approach for modeling the environment of an autonomous vehicle are dynamic occupancy grid maps, in which the surrounding is divided into cells, each containing the occupancy and velocity state of its location. Despite the advantage of modeling arbitrary shaped objects, the used algorithms rely on hand-designed inverse sensor models and semantic information is missing. Therefore, we introduce a multi-task recurrent neural network to predict grid maps providing occupancies, velocity estimates, semantic information and the driveable area. During training, our network architecture, which is a combination of convolutional and recurrent layers, processes sequences of raw lidar data, that is represented as bird's eye view images with several height channels. The multi-task network is trained in an end-to-end fashion to predict occupancy grid maps without the usual preprocessing steps consisting of removing ground points and applying an inverse sensor model. In our evaluations, we show that our learned inverse sensor model is able to overcome some limitations of a geometric inverse sensor model in terms of representing object shapes and modeling freespace. Moreover, we report a better runtime performance and more accurate semantic predictions for our end-to-end approach, compared to our network relying on measurement grid maps as input data.