 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Occupancy Grid Prediction Using Recurrent Neural Networks
Paper and Code
Sep 11, 2018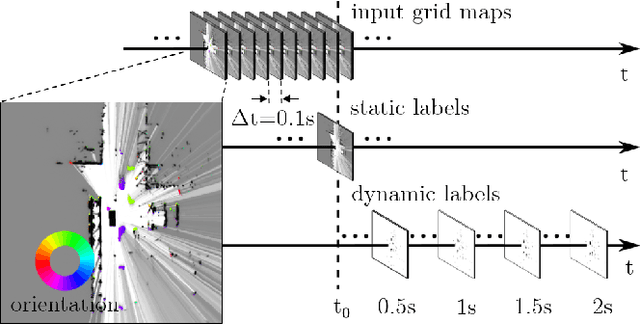
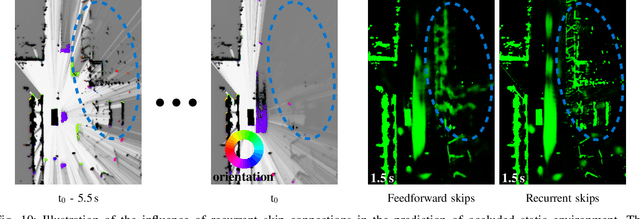
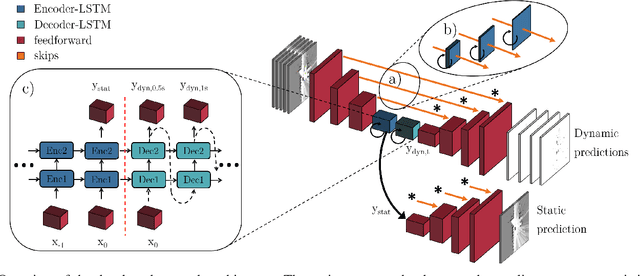
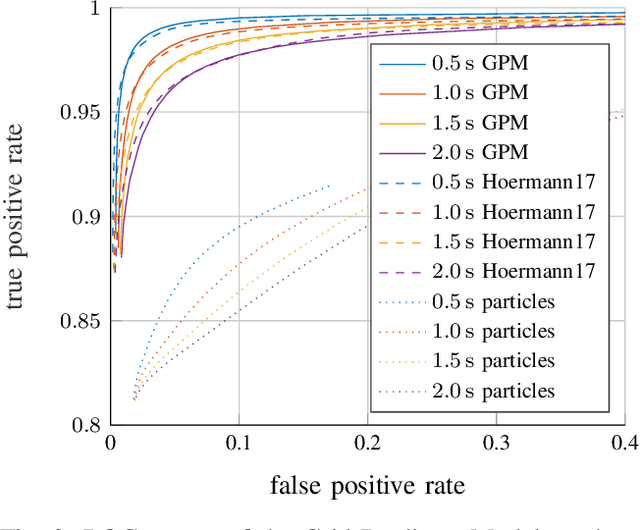
We tackle the long-term prediction of scene evolution in a complex downtown scenario for automated driving based on Lidar grid fusion and recurrent neural networks (RNNs). A bird's eye view of the scene, including occupancy and velocity, is fed as a sequence to a RNN which is trained to predict future occupancy. The nature of prediction allows generation of multiple hours of training data without the need of manual labeling. Thus, the training strategy and loss function is designed for long sequences of real-world data (unbalanced, continuously changing situations, false labels, etc.). The deep CNN architecture comprises convolutional long short-term memories (ConvLSTMs) to separate static from dynamic regions and to predict dynamic objects in future frames. Novel recurrent skip connections show the ability to predict small occluded objects, i.e. pedestrians, and occluded static regions. Spatio-temporal correlations between grid cells are exploited to predict multimodal future paths and interactions between objects. Experiments also quantify improvements to our previous network, a Monte Carlo approach, and literature.