 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepLocalization: Landmark-based Self-Localization with Deep Neural Networks
Apr 18, 2019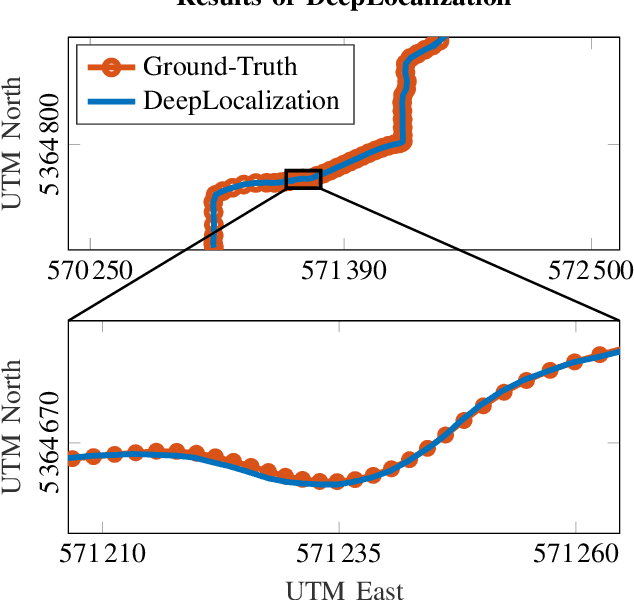
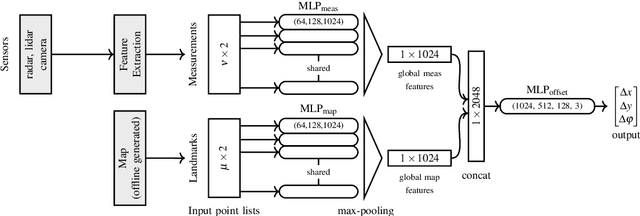
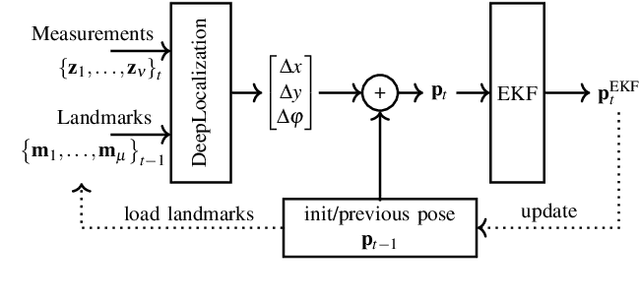
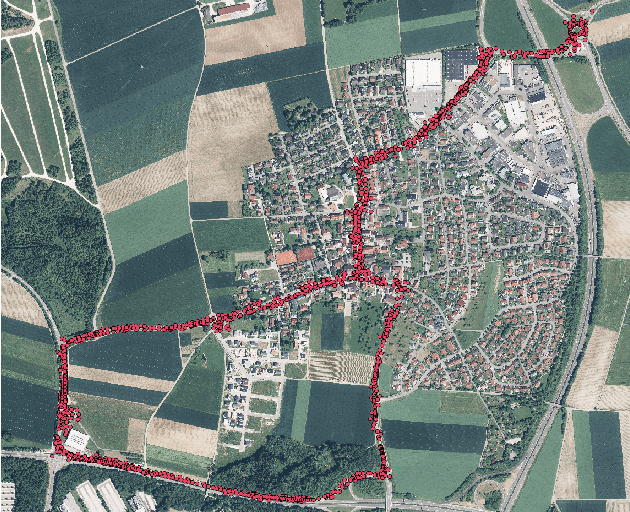
We address the problem of landmark-based vehicle self-localization by relying on multi-modal sensory information. Our goal is to determine the autonomous vehicle's pose based on landmark measurements and map landmarks. The map is built by extracting landmarks from the vehicle's field of view in an off-line way, while the measurements are collected in the same way during inference. To map the measurements and map landmarks to the vehicle's pose, we propose DeepLocalization, a deep neural network that copes with dynamic input. Our network is robust to missing landmarks that occur due to the dynamic environment and handles unordered and adaptive input. In real-world experiments, we evaluate two inference approaches to show that DeepLocalization can be combined with GPS-sensors and is complementary to filtering approaches such as an extended Kalman filter. We show that our approach achieves state-of-the-art accuracy and is about ten times faster than the related work.
Long-Term Occupancy Grid Prediction Using Recurrent Neural Networks
Sep 11, 2018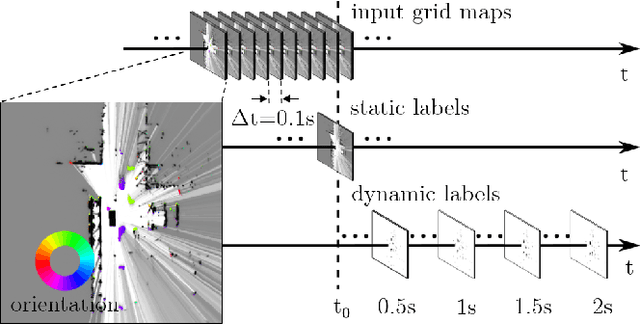
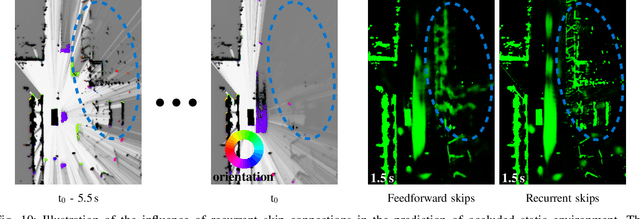
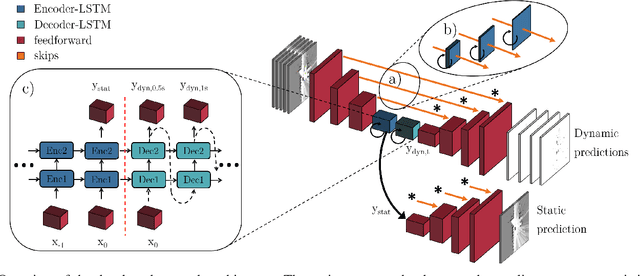
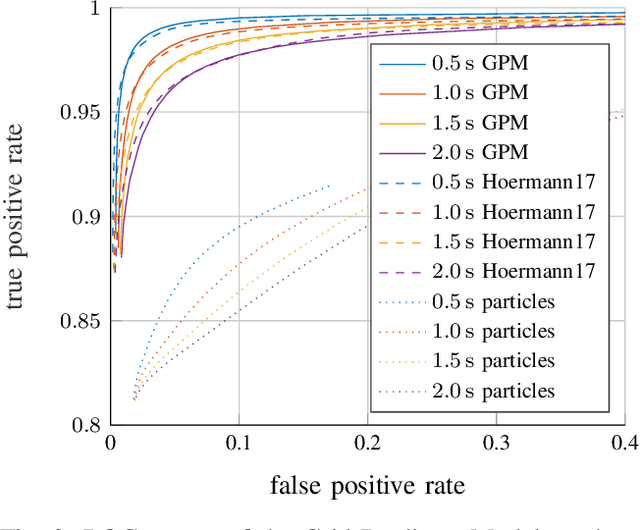
We tackle the long-term prediction of scene evolution in a complex downtown scenario for automated driving based on Lidar grid fusion and recurrent neural networks (RNNs). A bird's eye view of the scene, including occupancy and velocity, is fed as a sequence to a RNN which is trained to predict future occupancy. The nature of prediction allows generation of multiple hours of training data without the need of manual labeling. Thus, the training strategy and loss function is designed for long sequences of real-world data (unbalanced, continuously changing situations, false labels, etc.). The deep CNN architecture comprises convolutional long short-term memories (ConvLSTMs) to separate static from dynamic regions and to predict dynamic objects in future frames. Novel recurrent skip connections show the ability to predict small occluded objects, i.e. pedestrians, and occluded static regions. Spatio-temporal correlations between grid cells are exploited to predict multimodal future paths and interactions between objects. Experiments also quantify improvements to our previous network, a Monte Carlo approach, and literature.
Deep Object Tracking on Dynamic Occupancy Grid Maps Using RNNs
May 23, 2018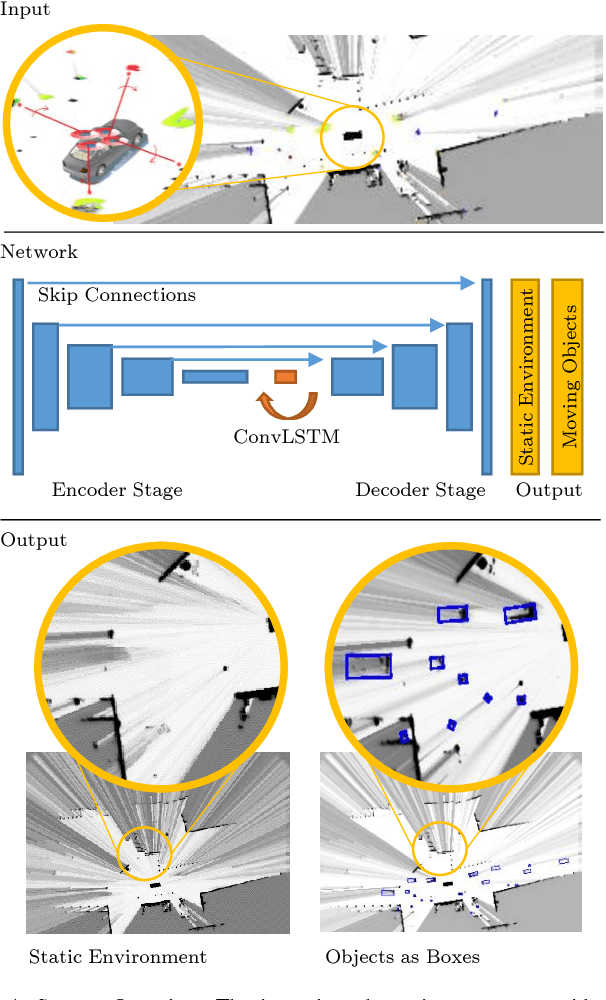

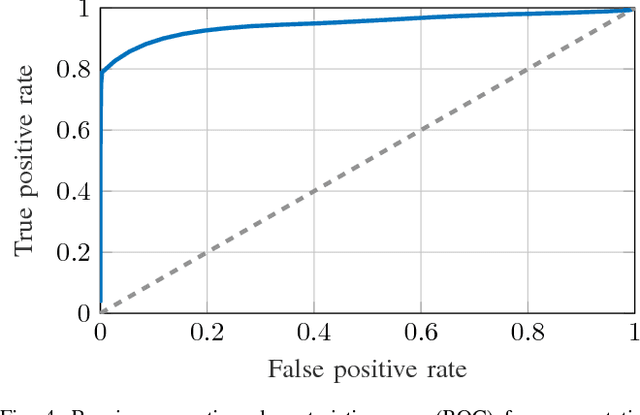
The comprehensive representation and understanding of the driving environment is crucial to improve the safety and reliability of autonomous vehicles. In this paper, we present a new approach to establish an environment model containing a segmentation between static and dynamic background and parametric modeled objects with shape, position and orientation. Multiple laser scanners are fused into a dynamic occupancy grid map resulting in a 360{\deg} perception of the environment. A single-stage deep convolutional neural network is combined with a recurrent neural network, which takes a time series of the occupancy grid map as input and tracks cell states and its corresponding object hypotheses. The labels for training are created unsupervised with an automatic label generation algorithm. The proposed methods are evaluated in real-world experiments in complex inner city scenarios using the aforementioned 360{\deg} laser perception. The results show a better object detection accuracy in comparison with our old approach as well as an AUC score of 0.946 for the dynamic and static segmentation. Furthermore, we gain an improved detection for occluded objects and a more consistent size estimation due to the usage of time series as input and the memory about previous states introduced by the recurrent neural network.
Offline Object Extraction from Dynamic Occupancy Grid Map Sequences
Apr 11, 2018
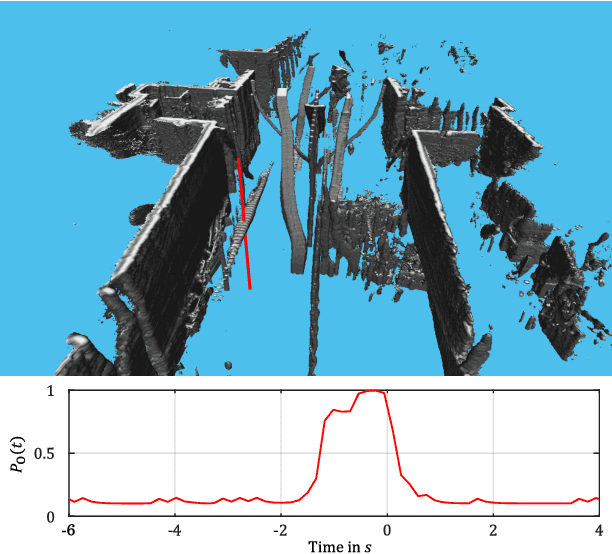

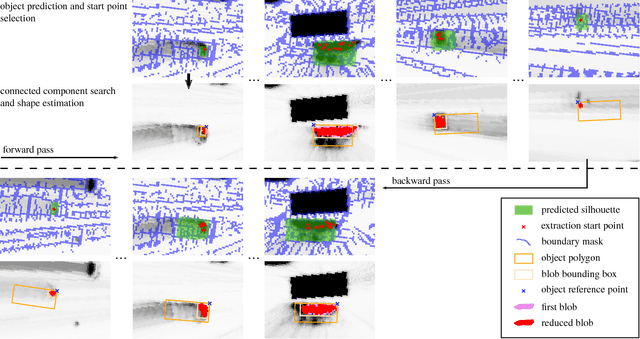
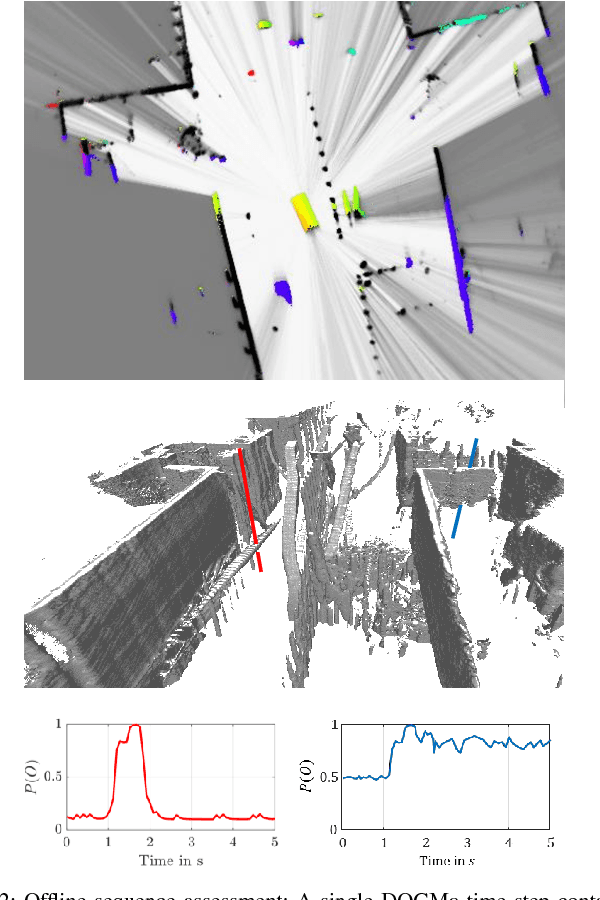
A dynamic occupancy grid map (DOGMa) allows a fast, robust, and complete environment representation for automated vehicles. Dynamic objects in a DOGMa, however, are commonly represented as independent cells while modeled objects with shape and pose are favorable. The evaluation of algorithms for object extraction or the training and validation of learning algorithms rely on labeled ground truth data. Manually annotating objects in a DOGMa to obtain ground truth data is a time consuming and expensive process. Additionally the quality of labeled data depend strongly on the variation of filtered input data. The presented work introduces an automatic labeling process, where a full sequence is used to extract the best possible object pose and shape in terms of temporal consistency. A two direction temporal search is executed to trace single objects over a sequence, where the best estimate of its extent and pose is refined in every time step. Furthermore, the presented algorithm only uses statistical constraints of the cell clusters for the object extraction instead of fixed heuristic parameters. Experimental results show a well-performing automatic labeling algorithm with real sensor data even at challenging scenarios.
Object Detection on Dynamic Occupancy Grid Maps Using Deep Learning and Automatic Label Generation
Jan 30, 2018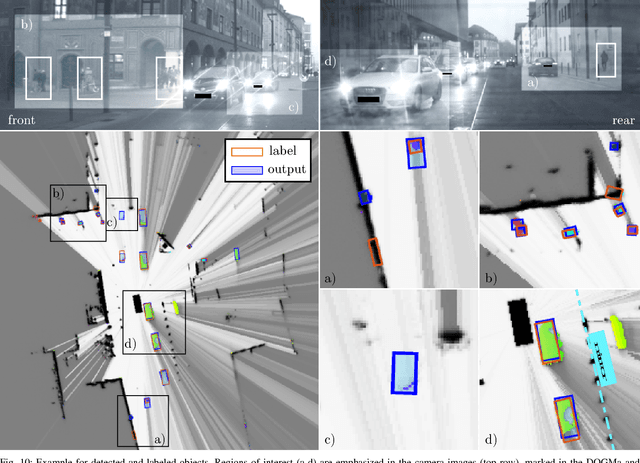

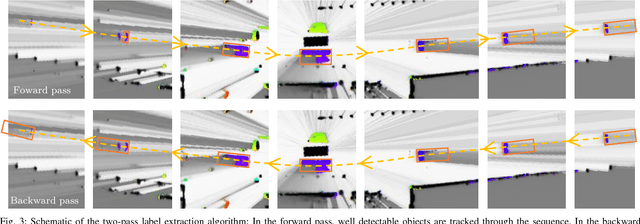
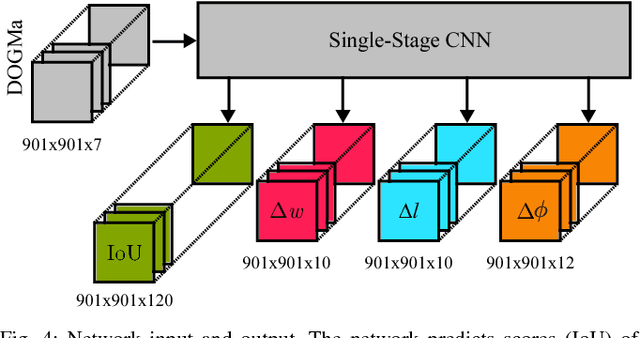
We tackle the problem of object detection and pose estimation in a shared space downtown environment. For perception multiple laser scanners with 360{\deg} coverage were fused in a dynamic occupancy grid map (DOGMa). A single-stage deep convolutional neural network is trained to provide object hypotheses comprising of shape, position, orientation and an existence score from a single input DOGMa. Furthermore, an algorithm for offline object extraction was developed to automatically label several hours of training data. The algorithm is based on a two-pass trajectory extraction, forward and backward in time. Typical for engineered algorithms, the automatic label generation suffers from misdetections, which makes hard negative mining impractical. Therefore, we propose a loss function counteracting the high imbalance between mostly static background and extremely rare dynamic grid cells. Experiments indicate, that the trained network has good generalization capabilities since it detects objects occasionally lost by the label algorithm. Evaluation reaches an average precision (AP) of 75.9%
Dynamic Occupancy Grid Prediction for Urban Autonomous Driving: A Deep Learning Approach with Fully Automatic Labeling
Nov 07, 2017
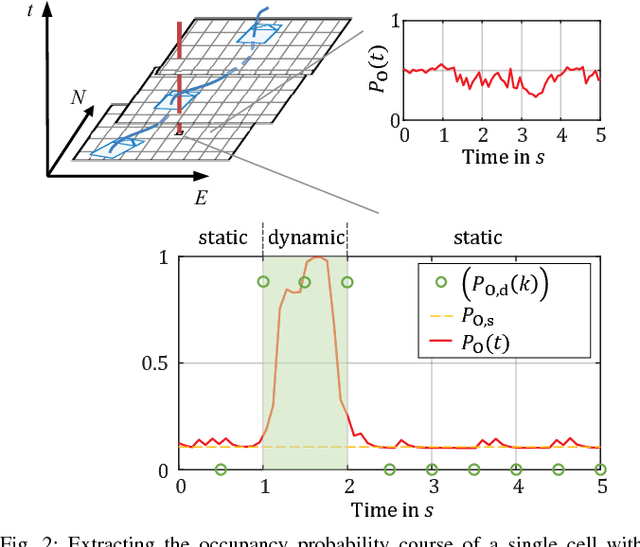

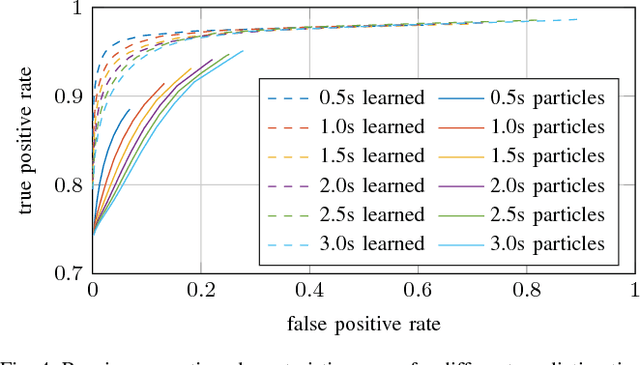
Long-term situation prediction plays a crucial role in the development of intelligent vehicles. A major challenge still to overcome is the prediction of complex downtown scenarios with multiple road users, e.g., pedestrians, bikes, and motor vehicles, interacting with each other. This contribution tackles this challenge by combining a Bayesian filtering technique for environment representation, and machine learning as long-term predictor. More specifically, a dynamic occupancy grid map is utilized as input to a deep convolutional neural network. This yields the advantage of using spatially distributed velocity estimates from a single time step for prediction, rather than a raw data sequence, alleviating common problems dealing with input time series of multiple sensors. Furthermore, convolutional neural networks have the inherent characteristic of using context information, enabling the implicit modeling of road user interaction. Pixel-wise balancing is applied in the loss function counteracting the extreme imbalance between static and dynamic cells. One of the major advantages is the unsupervised learning character due to fully automatic label generation. The presented algorithm is trained and evaluated on multiple hours of recorded sensor data and compared to Monte-Carlo simulation.