 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Vehicle Self-Localization with HD Feature Maps
Jul 16, 2021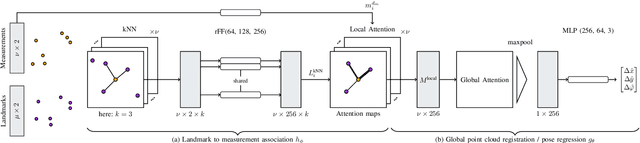
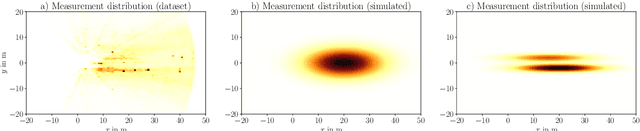
We present a vehicle self-localization method using point-based deep neural networks. Our approach processes measurements and point features, i.e. landmarks, from a high-definition digital map to infer the vehicle's pose. To learn the best association and incorporate local information between the point sets, we propose an attention mechanism that matches the measurements to the corresponding landmarks. Finally, we use this representation for the point-cloud registration and the subsequent pose regression task. Furthermore, we introduce a training simulation framework that artificially generates measurements and landmarks to facilitate the deployment process and reduce the cost of creating extensive datasets from real-world data. We evaluate our method on our dataset, as well as an adapted version of the Kitti odometry dataset, where we achieve superior performance compared to related approaches; and additionally show dominant generalization capabilities.
Point Transformer
Nov 02, 2020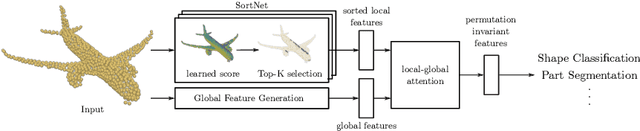


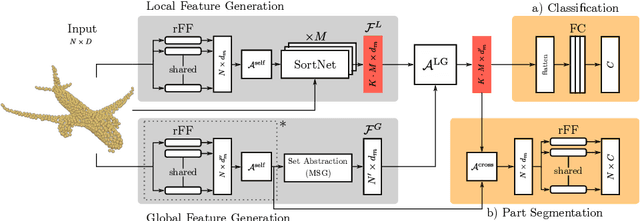
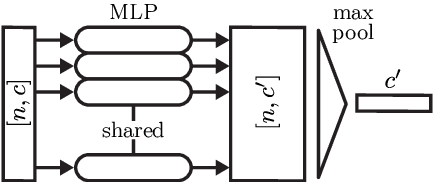
In this work, we present Point Transformer, a deep neural network that operates directly on unordered and unstructured point sets. We design Point Transformer to extract local and global features and relate both representations by introducing the local-global attention mechanism, which aims to capture spatial point relations and shape information. For that purpose, we propose SortNet, as part of the Point Transformer, which induces input permutation invariance by selecting points based on a learned score. The output of Point Transformer is a sorted and permutation invariant feature list that can directly be incorporated into common computer vision applications. We evaluate our approach on standard classification and part segmentation benchmarks to demonstrate competitive results compared to the prior work.
DeepCLR: Correspondence-Less Architecture for Deep End-to-End Point Cloud Registration
Jul 22, 2020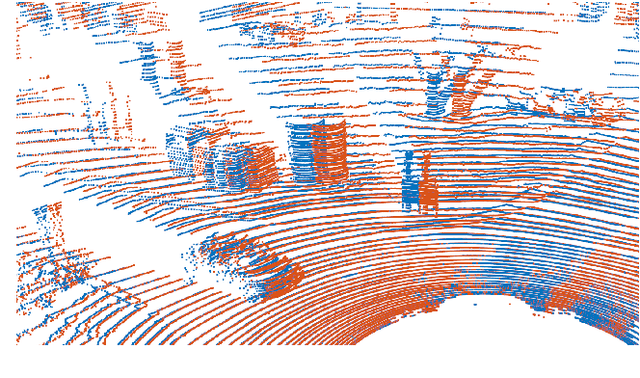

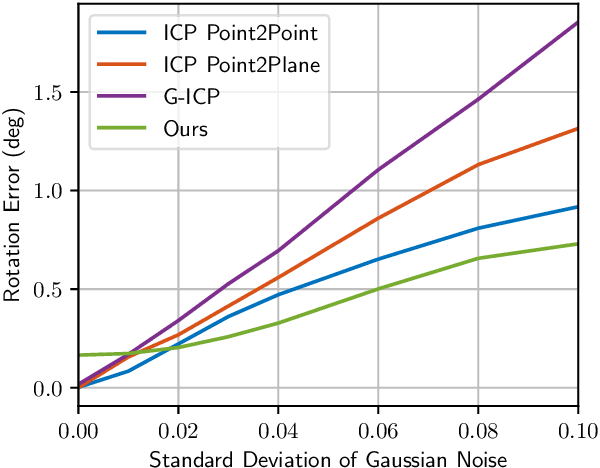
This work addresses the problem of point cloud registration using deep neural networks. We propose an approach to predict the alignment between two point clouds with overlapping data content, but displaced origins. Such point clouds originate, for example, from consecutive measurements of a LiDAR mounted on a moving platform. The main difficulty in deep registration of raw point clouds is the fusion of template and source point cloud. Our proposed architecture applies flow embedding to tackle this problem, which generates features that describe the motion of each template point. These features are then used to predict the alignment in an end-to-end fashion without extracting explicit point correspondences between both input clouds. We rely on the KITTI odometry and ModelNet40 datasets for evaluating our method on various point distributions. Our approach achieves state-of-the-art accuracy and the lowest run-time of the compared methods.
DeepLocalization: Landmark-based Self-Localization with Deep Neural Networks
Apr 18, 2019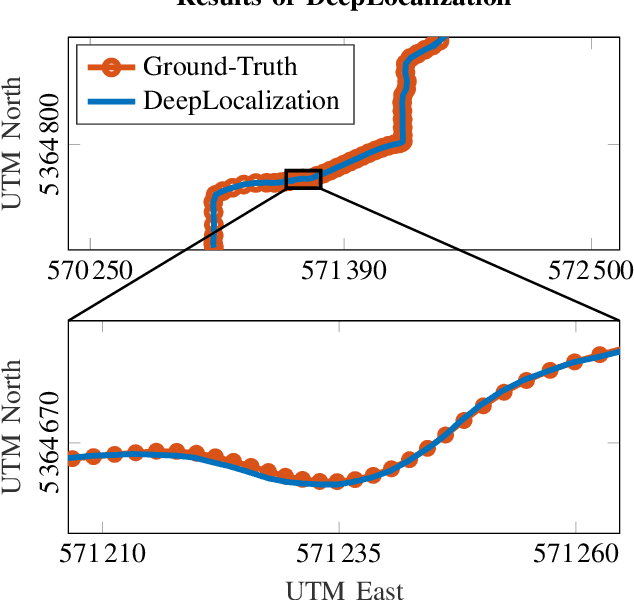
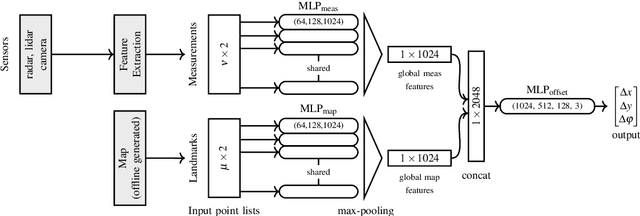
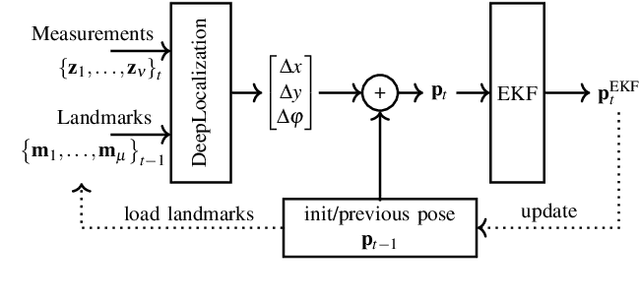
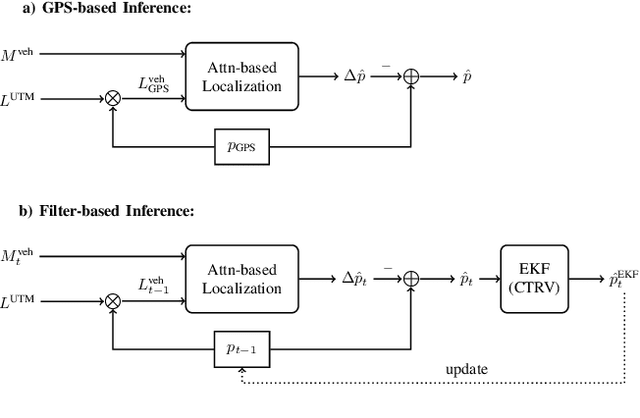
We address the problem of landmark-based vehicle self-localization by relying on multi-modal sensory information. Our goal is to determine the autonomous vehicle's pose based on landmark measurements and map landmarks. The map is built by extracting landmarks from the vehicle's field of view in an off-line way, while the measurements are collected in the same way during inference. To map the measurements and map landmarks to the vehicle's pose, we propose DeepLocalization, a deep neural network that copes with dynamic input. Our network is robust to missing landmarks that occur due to the dynamic environment and handles unordered and adaptive input. In real-world experiments, we evaluate two inference approaches to show that DeepLocalization can be combined with GPS-sensors and is complementary to filtering approaches such as an extended Kalman filter. We show that our approach achieves state-of-the-art accuracy and is about ten times faster than the related work.
Deep Object Tracking on Dynamic Occupancy Grid Maps Using RNNs
May 23, 2018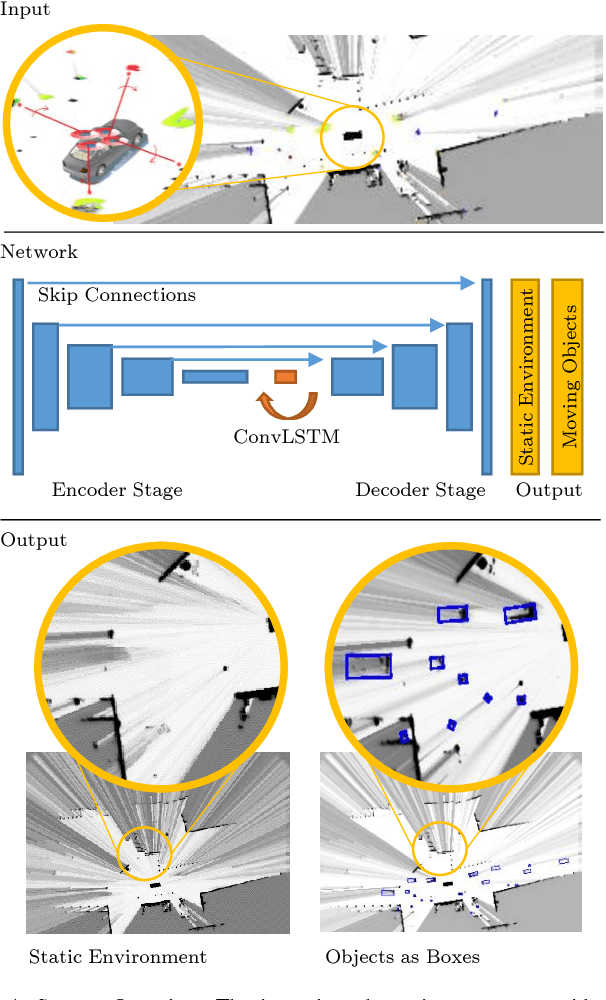
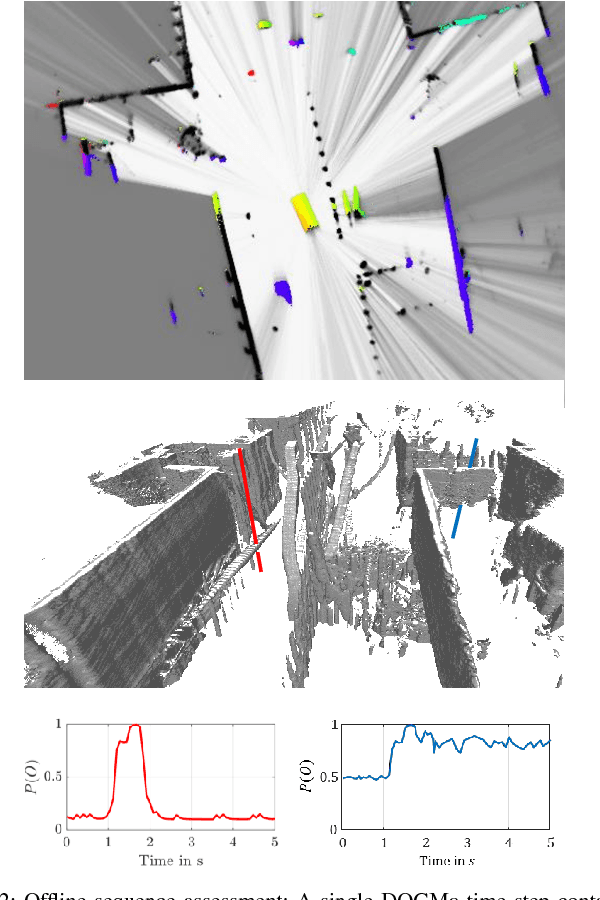

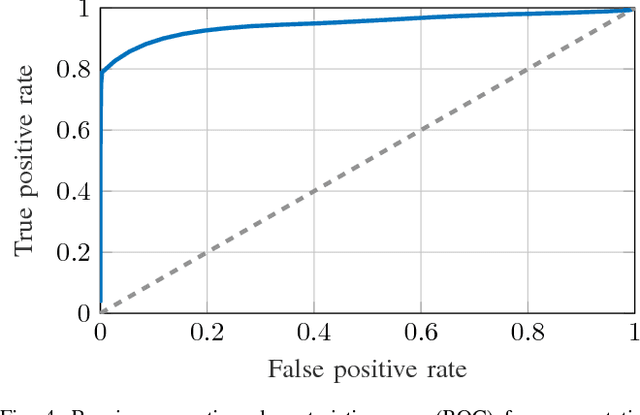
The comprehensive representation and understanding of the driving environment is crucial to improve the safety and reliability of autonomous vehicles. In this paper, we present a new approach to establish an environment model containing a segmentation between static and dynamic background and parametric modeled objects with shape, position and orientation. Multiple laser scanners are fused into a dynamic occupancy grid map resulting in a 360{\deg} perception of the environment. A single-stage deep convolutional neural network is combined with a recurrent neural network, which takes a time series of the occupancy grid map as input and tracks cell states and its corresponding object hypotheses. The labels for training are created unsupervised with an automatic label generation algorithm. The proposed methods are evaluated in real-world experiments in complex inner city scenarios using the aforementioned 360{\deg} laser perception. The results show a better object detection accuracy in comparison with our old approach as well as an AUC score of 0.946 for the dynamic and static segmentation. Furthermore, we gain an improved detection for occluded objects and a more consistent size estimation due to the usage of time series as input and the memory about previous states introduced by the recurrent neural network.