 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Multimodal Chronic Wound Embeddings with Expert Triplet Agreement
Apr 02, 2026Recessive dystrophic epidermolysis bullosa (RDEB) is a rare genetic skin disorder for which clinicians greatly benefit from finding similar cases using images and clinical text. However, off-the-shelf foundation models do not reliably capture clinically meaningful features for this heterogeneous, long-tail disease, and structured measurement of agreement with experts is challenging. To address these gaps, we propose evaluating embedding spaces with expert ordinal comparisons (triplet judgments), which are fast to collect and encode implicit clinical similarity knowledge. We further introduce TriDerm, a multimodal framework that learns interpretable wound representations from small cohorts by integrating wound imagery, boundary masks, and expert reports. On the vision side, TriDerm adapts visual foundation models to RDEB using wound-level attention pooling and non-contrastive representation learning. For text, we prompt large language models with comparison queries and recover medically meaningful representations via soft ordinal embeddings (SOE). We show that visual and textual modalities capture complementary aspects of wound phenotype, and that fusing both modalities yields 73.5% agreement with experts, outperforming the best off-the-shelf single-modality foundation model by over 5.6 percentage points. We make the expert annotation tool, model code and representative dataset samples publicly available.
Embedding interpretable $\ell_1$-regression into neural networks for uncovering temporal structure in cell imaging
Mar 03, 2026While artificial neural networks excel in unsupervised learning of non-sparse structure, classical statistical regression techniques offer better interpretability, in particular when sparseness is enforced by $\ell_1$ regularization, enabling identification of which factors drive observed dynamics. We investigate how these two types of approaches can be optimally combined, exemplarily considering two-photon calcium imaging data where sparse autoregressive dynamics are to be extracted. We propose embedding a vector autoregressive (VAR) model as an interpretable regression technique into a convolutional autoencoder, which provides dimension reduction for tractable temporal modeling. A skip connection separately addresses non-sparse static spatial information, selectively channeling sparse structure into the $\ell_1$-regularized VAR. $\ell_1$-estimation of regression parameters is enabled by differentiating through the piecewise linear solution path. This is contrasted with approaches where the autoencoder does not adapt to the VAR model. Having an embedded statistical model also enables a testing approach for comparing temporal sequences from the same observational unit. Additionally, contribution maps visualize which spatial regions drive the learned dynamics.
Open-Set LiDAR Panoptic Segmentation Guided by Uncertainty-Aware Learning
Jun 16, 2025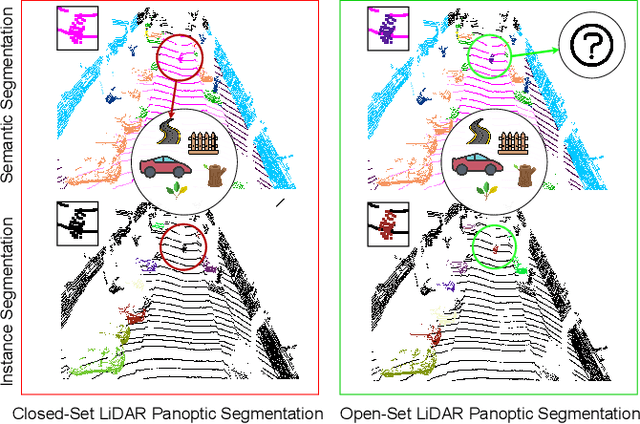
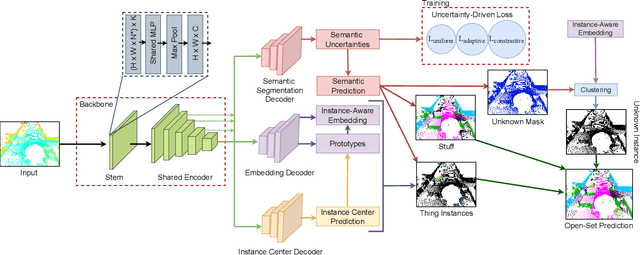
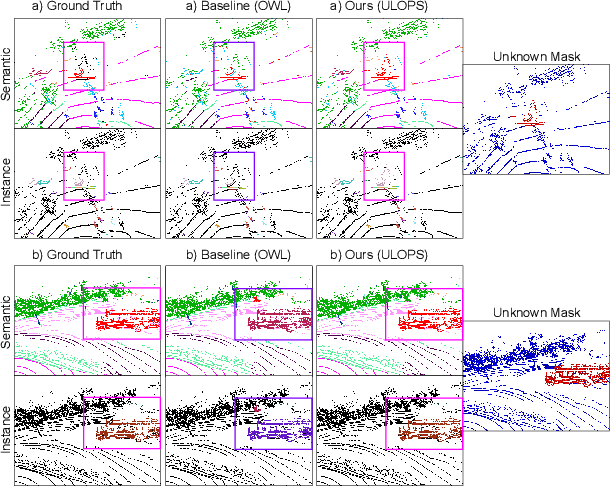
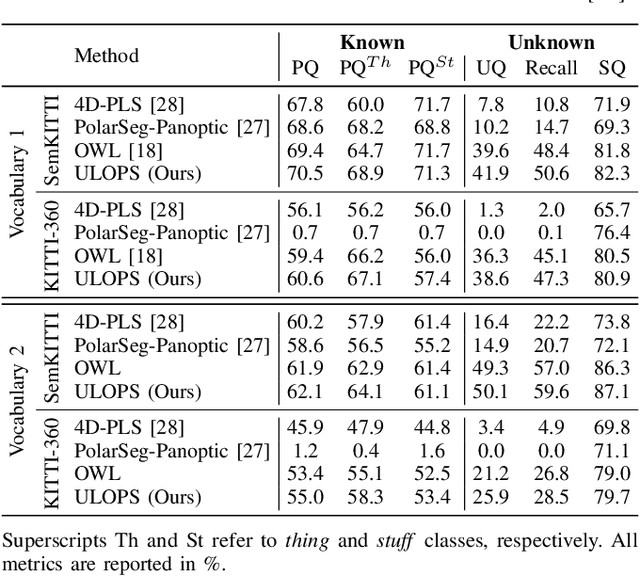
Autonomous vehicles that navigate in open-world environments may encounter previously unseen object classes. However, most existing LiDAR panoptic segmentation models rely on closed-set assumptions, failing to detect unknown object instances. In this work, we propose ULOPS, an uncertainty-guided open-set panoptic segmentation framework that leverages Dirichlet-based evidential learning to model predictive uncertainty. Our architecture incorporates separate decoders for semantic segmentation with uncertainty estimation, embedding with prototype association, and instance center prediction. During inference, we leverage uncertainty estimates to identify and segment unknown instances. To strengthen the model's ability to differentiate between known and unknown objects, we introduce three uncertainty-driven loss functions. Uniform Evidence Loss to encourage high uncertainty in unknown regions. Adaptive Uncertainty Separation Loss ensures a consistent difference in uncertainty estimates between known and unknown objects at a global scale. Contrastive Uncertainty Loss refines this separation at the fine-grained level. To evaluate open-set performance, we extend benchmark settings on KITTI-360 and introduce a new open-set evaluation for nuScenes. Extensive experiments demonstrate that ULOPS consistently outperforms existing open-set LiDAR panoptic segmentation methods.
Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters
Mar 05, 2025LiDAR semantic segmentation models are typically trained from random initialization as universal pre-training is hindered by the lack of large, diverse datasets. Moreover, most point cloud segmentation architectures incorporate custom network layers, limiting the transferability of advances from vision-based architectures. Inspired by recent advances in universal foundation models, we propose BALViT, a novel approach that leverages frozen vision models as amodal feature encoders for learning strong LiDAR encoders. Specifically, BALViT incorporates both range-view and bird's-eye-view LiDAR encoding mechanisms, which we combine through a novel 2D-3D adapter. While the range-view features are processed through a frozen image backbone, our bird's-eye-view branch enhances them through multiple cross-attention interactions. Thereby, we continuously improve the vision network with domain-dependent knowledge, resulting in a strong label-efficient LiDAR encoding mechanism. Extensive evaluations of BALViT on the SemanticKITTI and nuScenes benchmarks demonstrate that it outperforms state-of-the-art methods on small data regimes. We make the code and models publicly available at: http://balvit.cs.uni-freiburg.de.
Taxonomy-Aware Continual Semantic Segmentation in Hyperbolic Spaces for Open-World Perception
Jul 25, 2024



Semantic segmentation models are typically trained on a fixed set of classes, limiting their applicability in open-world scenarios. Class-incremental semantic segmentation aims to update models with emerging new classes while preventing catastrophic forgetting of previously learned ones. However, existing methods impose strict rigidity on old classes, reducing their effectiveness in learning new incremental classes. In this work, we propose Taxonomy-Oriented Poincar\'e-regularized Incremental-Class Segmentation (TOPICS) that learns feature embeddings in hyperbolic space following explicit taxonomy-tree structures. This supervision provides plasticity for old classes, updating ancestors based on new classes while integrating new classes at fitting positions. Additionally, we maintain implicit class relational constraints on the geometric basis of the Poincar\'e ball. This ensures that the latent space can continuously adapt to new constraints while maintaining a robust structure to combat catastrophic forgetting. We also establish eight realistic incremental learning protocols for autonomous driving scenarios, where novel classes can originate from known classes or the background. Extensive evaluations of TOPICS on the Cityscapes and Mapillary Vistas 2.0 benchmarks demonstrate that it achieves state-of-the-art performance. We make the code and trained models publicly available at http://topics.cs.uni-freiburg.de.
INoD: Injected Noise Discriminator for Self-Supervised Representation Learning in Agricultural Fields
Mar 31, 2023Perception datasets for agriculture are limited both in quantity and diversity which hinders effective training of supervised learning approaches. Self-supervised learning techniques alleviate this problem, however, existing methods are not optimized for dense prediction tasks in agriculture domains which results in degraded performance. In this work, we address this limitation with our proposed Injected Noise Discriminator (INoD) which exploits principles of feature replacement and dataset discrimination for self-supervised representation learning. INoD interleaves feature maps from two disjoint datasets during their convolutional encoding and predicts the dataset affiliation of the resultant feature map as a pretext task. Our approach enables the network to learn unequivocal representations of objects seen in one dataset while observing them in conjunction with similar features from the disjoint dataset. This allows the network to reason about higher-level semantics of the entailed objects, thus improving its performance on various downstream tasks. Additionally, we introduce the novel Fraunhofer Potato 2022 dataset consisting of over 16,800 images for object detection in potato fields. Extensive evaluations of our proposed INoD pretraining strategy for the tasks of object detection, semantic segmentation, and instance segmentation on the Sugar Beets 2016 and our potato dataset demonstrate that it achieves state-of-the-art performance.