 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyp2Former: Hierarchy-Aware Hyperbolic Embeddings for Open-Set Panoptic Segmentation
May 04, 2026Recognizing unknown objects is crucial for safety-critical applications such as autonomous driving and robotics. Open-Set Panoptic Segmentation (OPS) aims to segment known thing and stuff classes while identifying valid unknown objects as separate instances. Prior OPS approaches largely treat known categories as a flat label set, ignoring the semantic hierarchy that provides valuable structural priors for distinguishing unknown objects from in-distribution classes. In this work, we propose Hyp2Former, an end-to-end framework for OPS that does not require explicit modeling of unknowns during training, and instead learns hierarchical semantic similarities continuously in hyperbolic space. By explicitly encoding hierarchical relationships among known categories, the model learns a structured embedding space that captures multiple levels of semantic abstraction. As a result, unknown objects that cannot be confidently classified as known categories still remain in close proximity to higher-level concepts (e.g., an unknown animal remains closer to "animal" or "object" than to unrelated concepts such as "electronics" or "stuff") and can therefore be reliably detected, even if their fine-grained category was not represented during training. Empirical evaluations across multiple public datasets such as MS COCO, Cityscapes, and Lost&Found demonstrate that Hyp2Former outperforms existing methods on OPS, achieving the best balance between unknown object discovery and in-distribution robustness.
Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking
Feb 26, 2026Capturing 4D spatiotemporal surroundings is crucial for the safe and reliable operation of robots in dynamic environments. However, most existing methods address only one side of the problem: they either provide coarse geometric tracking via bounding boxes, or detailed 3D structures like voxel-based occupancy that lack explicit temporal association. In this work, we present Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking (LaGS) that advances spatiotemporal scene understanding in a holistic direction. Our approach incorporates camera-based end-to-end tracking with mask-based multi-view panoptic occupancy prediction, and addresses the key challenge of efficiently aggregating multi-view information into 3D voxel grids via a novel latent Gaussian splatting approach. Specifically, we first fuse observations into 3D Gaussians that serve as a sparse point-centric latent representation of the 3D scene, and then splat the aggregated features onto a 3D voxel grid that is decoded by a mask-based segmentation head. We evaluate LaGS on the Occ3D nuScenes and Waymo datasets, achieving state-of-the-art performance for 4D panoptic occupancy tracking. We make our code available at https://lags.cs.uni-freiburg.de/.
UP-Fuse: Uncertainty-guided LiDAR-Camera Fusion for 3D Panoptic Segmentation
Feb 22, 2026LiDAR-camera fusion enhances 3D panoptic segmentation by leveraging camera images to complement sparse LiDAR scans, but it also introduces a critical failure mode. Under adverse conditions, degradation or failure of the camera sensor can significantly compromise the reliability of the perception system. To address this problem, we introduce UP-Fuse, a novel uncertainty-aware fusion framework in the 2D range-view that remains robust under camera sensor degradation, calibration drift, and sensor failure. Raw LiDAR data is first projected into the range-view and encoded by a LiDAR encoder, while camera features are simultaneously extracted and projected into the same shared space. At its core, UP-Fuse employs an uncertainty-guided fusion module that dynamically modulates cross-modal interaction using predicted uncertainty maps. These maps are learned by quantifying representational divergence under diverse visual degradations, ensuring that only reliable visual cues influence the fused representation. The fused range-view features are decoded by a novel hybrid 2D-3D transformer that mitigates spatial ambiguities inherent to the 2D projection and directly predicts 3D panoptic segmentation masks. Extensive experiments on Panoptic nuScenes, SemanticKITTI, and our introduced Panoptic Waymo benchmark demonstrate the efficacy and robustness of UP-Fuse, which maintains strong performance even under severe visual corruption or misalignment, making it well suited for robotic perception in safety-critical settings.
ForecastOcc: Vision-based Semantic Occupancy Forecasting
Feb 08, 2026Autonomous driving requires forecasting both geometry and semantics over time to effectively reason about future environment states. Existing vision-based occupancy forecasting methods focus on motion-related categories such as static and dynamic objects, while semantic information remains largely absent. Recent semantic occupancy forecasting approaches address this gap but rely on past occupancy predictions obtained from separate networks. This makes current methods sensitive to error accumulation and prevents learning spatio-temporal features directly from images. In this work, we present ForecastOcc, the first framework for vision-based semantic occupancy forecasting that jointly predicts future occupancy states and semantic categories. Our framework yields semantic occupancy forecasts for multiple horizons directly from past camera images, without relying on externally estimated maps. We evaluate ForecastOcc in two complementary settings: multi-view forecasting on the Occ3D-nuScenes dataset and monocular forecasting on SemanticKITTI, where we establish the first benchmark for this task. We introduce the first baselines by adapting two 2D forecasting modules within our framework. Importantly, we propose a novel architecture that incorporates a temporal cross-attention forecasting module, a 2D-to-3D view transformer, a 3D encoder for occupancy prediction, and a semantic occupancy head for voxel-level forecasts across multiple horizons. Extensive experiments on both datasets show that ForecastOcc consistently outperforms baselines, yielding semantically rich, future-aware predictions that capture scene dynamics and semantics critical for autonomous driving.
Open-Set LiDAR Panoptic Segmentation Guided by Uncertainty-Aware Learning
Jun 16, 2025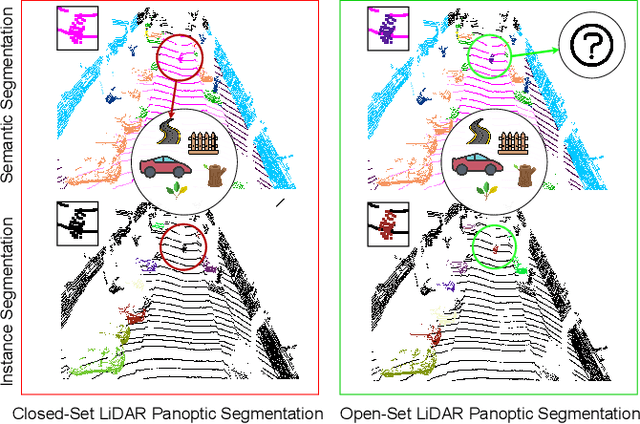
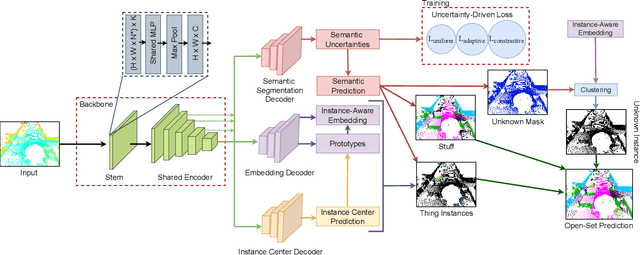
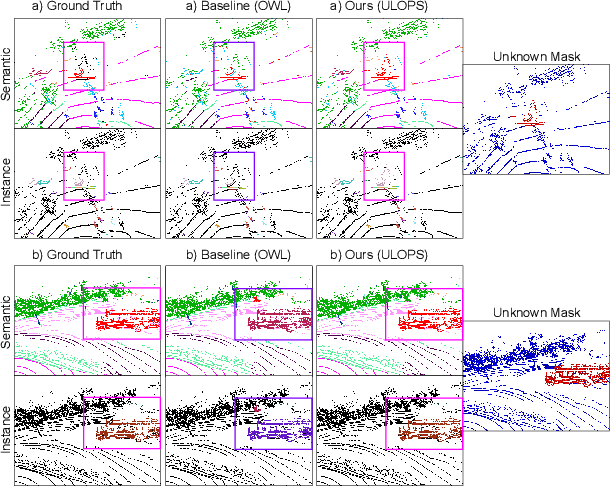
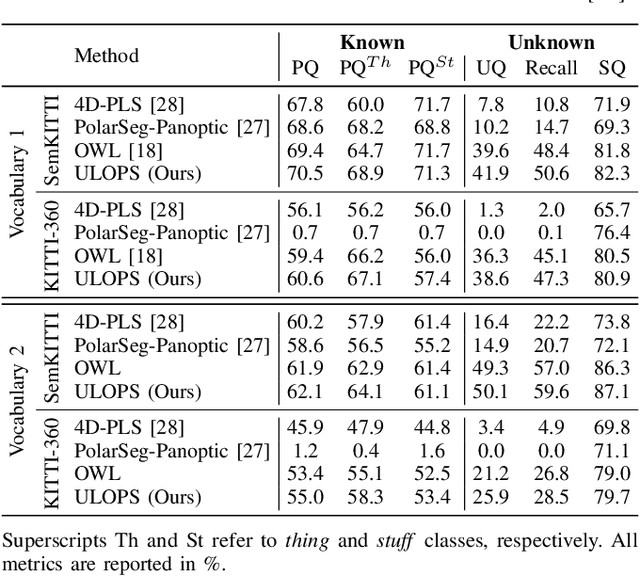
Autonomous vehicles that navigate in open-world environments may encounter previously unseen object classes. However, most existing LiDAR panoptic segmentation models rely on closed-set assumptions, failing to detect unknown object instances. In this work, we propose ULOPS, an uncertainty-guided open-set panoptic segmentation framework that leverages Dirichlet-based evidential learning to model predictive uncertainty. Our architecture incorporates separate decoders for semantic segmentation with uncertainty estimation, embedding with prototype association, and instance center prediction. During inference, we leverage uncertainty estimates to identify and segment unknown instances. To strengthen the model's ability to differentiate between known and unknown objects, we introduce three uncertainty-driven loss functions. Uniform Evidence Loss to encourage high uncertainty in unknown regions. Adaptive Uncertainty Separation Loss ensures a consistent difference in uncertainty estimates between known and unknown objects at a global scale. Contrastive Uncertainty Loss refines this separation at the fine-grained level. To evaluate open-set performance, we extend benchmark settings on KITTI-360 and introduce a new open-set evaluation for nuScenes. Extensive experiments demonstrate that ULOPS consistently outperforms existing open-set LiDAR panoptic segmentation methods.
Learning Appearance and Motion Cues for Panoptic Tracking
Mar 12, 2025Panoptic tracking enables pixel-level scene interpretation of videos by integrating instance tracking in panoptic segmentation. This provides robots with a spatio-temporal understanding of the environment, an essential attribute for their operation in dynamic environments. In this paper, we propose a novel approach for panoptic tracking that simultaneously captures general semantic information and instance-specific appearance and motion features. Unlike existing methods that overlook dynamic scene attributes, our approach leverages both appearance and motion cues through dedicated network heads. These interconnected heads employ multi-scale deformable convolutions that reason about scene motion offsets with semantic context and motion-enhanced appearance features to learn tracking embeddings. Furthermore, we introduce a novel two-step fusion module that integrates the outputs from both heads by first matching instances from the current time step with propagated instances from previous time steps and subsequently refines associations using motion-enhanced appearance embeddings, improving robustness in challenging scenarios. Extensive evaluations of our proposed \netname model on two benchmark datasets demonstrate that it achieves state-of-the-art performance in panoptic tracking accuracy, surpassing prior methods in maintaining object identities over time. To facilitate future research, we make the code available at http://panoptictracking.cs.uni-freiburg.de
Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters
Mar 05, 2025LiDAR semantic segmentation models are typically trained from random initialization as universal pre-training is hindered by the lack of large, diverse datasets. Moreover, most point cloud segmentation architectures incorporate custom network layers, limiting the transferability of advances from vision-based architectures. Inspired by recent advances in universal foundation models, we propose BALViT, a novel approach that leverages frozen vision models as amodal feature encoders for learning strong LiDAR encoders. Specifically, BALViT incorporates both range-view and bird's-eye-view LiDAR encoding mechanisms, which we combine through a novel 2D-3D adapter. While the range-view features are processed through a frozen image backbone, our bird's-eye-view branch enhances them through multiple cross-attention interactions. Thereby, we continuously improve the vision network with domain-dependent knowledge, resulting in a strong label-efficient LiDAR encoding mechanism. Extensive evaluations of BALViT on the SemanticKITTI and nuScenes benchmarks demonstrate that it outperforms state-of-the-art methods on small data regimes. We make the code and models publicly available at: http://balvit.cs.uni-freiburg.de.
Progressive Multi-Modal Fusion for Robust 3D Object Detection
Oct 09, 2024



Multi-sensor fusion is crucial for accurate 3D object detection in autonomous driving, with cameras and LiDAR being the most commonly used sensors. However, existing methods perform sensor fusion in a single view by projecting features from both modalities either in Bird's Eye View (BEV) or Perspective View (PV), thus sacrificing complementary information such as height or geometric proportions. To address this limitation, we propose ProFusion3D, a progressive fusion framework that combines features in both BEV and PV at both intermediate and object query levels. Our architecture hierarchically fuses local and global features, enhancing the robustness of 3D object detection. Additionally, we introduce a self-supervised mask modeling pre-training strategy to improve multi-modal representation learning and data efficiency through three novel objectives. Extensive experiments on nuScenes and Argoverse2 datasets conclusively demonstrate the efficacy of ProFusion3D. Moreover, ProFusion3D is robust to sensor failure, demonstrating strong performance when only one modality is available.
Amodal Optical Flow
Nov 13, 2023



Optical flow estimation is very challenging in situations with transparent or occluded objects. In this work, we address these challenges at the task level by introducing Amodal Optical Flow, which integrates optical flow with amodal perception. Instead of only representing the visible regions, we define amodal optical flow as a multi-layered pixel-level motion field that encompasses both visible and occluded regions of the scene. To facilitate research on this new task, we extend the AmodalSynthDrive dataset to include pixel-level labels for amodal optical flow estimation. We present several strong baselines, along with the Amodal Flow Quality metric to quantify the performance in an interpretable manner. Furthermore, we propose the novel AmodalFlowNet as an initial step toward addressing this task. AmodalFlowNet consists of a transformer-based cost-volume encoder paired with a recurrent transformer decoder which facilitates recurrent hierarchical feature propagation and amodal semantic grounding. We demonstrate the tractability of amodal optical flow in extensive experiments and show its utility for downstream tasks such as panoptic tracking. We make the dataset, code, and trained models publicly available at http://amodal-flow.cs.uni-freiburg.de.
Panoptic Out-of-Distribution Segmentation
Oct 18, 2023



Deep learning has led to remarkable strides in scene understanding with panoptic segmentation emerging as a key holistic scene interpretation task. However, the performance of panoptic segmentation is severely impacted in the presence of out-of-distribution (OOD) objects i.e. categories of objects that deviate from the training distribution. To overcome this limitation, we propose Panoptic Out-of Distribution Segmentation for joint pixel-level semantic in-distribution and out-of-distribution classification with instance prediction. We extend two established panoptic segmentation benchmarks, Cityscapes and BDD100K, with out-of-distribution instance segmentation annotations, propose suitable evaluation metrics, and present multiple strong baselines. Importantly, we propose the novel PoDS architecture with a shared backbone, an OOD contextual module for learning global and local OOD object cues, and dual symmetrical decoders with task-specific heads that employ our alignment-mismatch strategy for better OOD generalization. Combined with our data augmentation strategy, this approach facilitates progressive learning of out-of-distribution objects while maintaining in-distribution performance. We perform extensive evaluations that demonstrate that our proposed PoDS network effectively addresses the main challenges and substantially outperforms the baselines. We make the dataset, code, and trained models publicly available at http://pods.cs.uni-freiburg.de.