 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecastOcc: Vision-based Semantic Occupancy Forecasting
Feb 08, 2026Autonomous driving requires forecasting both geometry and semantics over time to effectively reason about future environment states. Existing vision-based occupancy forecasting methods focus on motion-related categories such as static and dynamic objects, while semantic information remains largely absent. Recent semantic occupancy forecasting approaches address this gap but rely on past occupancy predictions obtained from separate networks. This makes current methods sensitive to error accumulation and prevents learning spatio-temporal features directly from images. In this work, we present ForecastOcc, the first framework for vision-based semantic occupancy forecasting that jointly predicts future occupancy states and semantic categories. Our framework yields semantic occupancy forecasts for multiple horizons directly from past camera images, without relying on externally estimated maps. We evaluate ForecastOcc in two complementary settings: multi-view forecasting on the Occ3D-nuScenes dataset and monocular forecasting on SemanticKITTI, where we establish the first benchmark for this task. We introduce the first baselines by adapting two 2D forecasting modules within our framework. Importantly, we propose a novel architecture that incorporates a temporal cross-attention forecasting module, a 2D-to-3D view transformer, a 3D encoder for occupancy prediction, and a semantic occupancy head for voxel-level forecasts across multiple horizons. Extensive experiments on both datasets show that ForecastOcc consistently outperforms baselines, yielding semantically rich, future-aware predictions that capture scene dynamics and semantics critical for autonomous driving.
Learning Appearance and Motion Cues for Panoptic Tracking
Mar 12, 2025Panoptic tracking enables pixel-level scene interpretation of videos by integrating instance tracking in panoptic segmentation. This provides robots with a spatio-temporal understanding of the environment, an essential attribute for their operation in dynamic environments. In this paper, we propose a novel approach for panoptic tracking that simultaneously captures general semantic information and instance-specific appearance and motion features. Unlike existing methods that overlook dynamic scene attributes, our approach leverages both appearance and motion cues through dedicated network heads. These interconnected heads employ multi-scale deformable convolutions that reason about scene motion offsets with semantic context and motion-enhanced appearance features to learn tracking embeddings. Furthermore, we introduce a novel two-step fusion module that integrates the outputs from both heads by first matching instances from the current time step with propagated instances from previous time steps and subsequently refines associations using motion-enhanced appearance embeddings, improving robustness in challenging scenarios. Extensive evaluations of our proposed \netname model on two benchmark datasets demonstrate that it achieves state-of-the-art performance in panoptic tracking accuracy, surpassing prior methods in maintaining object identities over time. To facilitate future research, we make the code available at http://panoptictracking.cs.uni-freiburg.de
Panoptic-Depth Forecasting
Sep 18, 2024
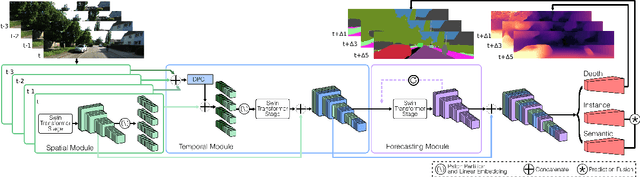

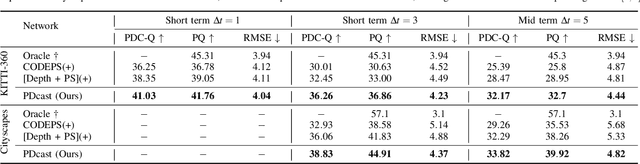
Forecasting the semantics and 3D structure of scenes is essential for robots to navigate and plan actions safely. Recent methods have explored semantic and panoptic scene forecasting; however, they do not consider the geometry of the scene. In this work, we propose the panoptic-depth forecasting task for jointly predicting the panoptic segmentation and depth maps of unobserved future frames, from monocular camera images. To facilitate this work, we extend the popular KITTI-360 and Cityscapes benchmarks by computing depth maps from LiDAR point clouds and leveraging sequential labeled data. We also introduce a suitable evaluation metric that quantifies both the panoptic quality and depth estimation accuracy of forecasts in a coherent manner. Furthermore, we present two baselines and propose the novel PDcast architecture that learns rich spatio-temporal representations by incorporating a transformer-based encoder, a forecasting module, and task-specific decoders to predict future panoptic-depth outputs. Extensive evaluations demonstrate the effectiveness of PDcast across two datasets and three forecasting tasks, consistently addressing the primary challenges. We make the code publicly available at https://pdcast.cs.uni-freiburg.de.
Semantic Scene Segmentation for Robotics
Jan 15, 2024Comprehensive scene understanding is a critical enabler of robot autonomy. Semantic segmentation is one of the key scene understanding tasks which is pivotal for several robotics applications including autonomous driving, domestic service robotics, last mile delivery, amongst many others. Semantic segmentation is a dense prediction task that aims to provide a scene representation in which each pixel of an image is assigned a semantic class label. Therefore, semantic segmentation considers the full scene context, incorporating the object category, location, and shape of all the scene elements, including the background. Numerous algorithms have been proposed for semantic segmentation over the years. However, the recent advances in deep learning combined with the boost in the computational capacity and the availability of large-scale labeled datasets have led to significant advances in semantic segmentation. In this chapter, we introduce the task of semantic segmentation and present the deep learning techniques that have been proposed to address this task over the years. We first define the task of semantic segmentation and contrast it with other closely related scene understanding problems. We detail different algorithms and architectures for semantic segmentation and the commonly employed loss functions. Furthermore, we present an overview of datasets, benchmarks, and metrics that are used in semantic segmentation. We conclude the chapter with a discussion of challenges and opportunities for further research in this area.
Panoptic Out-of-Distribution Segmentation
Oct 18, 2023



Deep learning has led to remarkable strides in scene understanding with panoptic segmentation emerging as a key holistic scene interpretation task. However, the performance of panoptic segmentation is severely impacted in the presence of out-of-distribution (OOD) objects i.e. categories of objects that deviate from the training distribution. To overcome this limitation, we propose Panoptic Out-of Distribution Segmentation for joint pixel-level semantic in-distribution and out-of-distribution classification with instance prediction. We extend two established panoptic segmentation benchmarks, Cityscapes and BDD100K, with out-of-distribution instance segmentation annotations, propose suitable evaluation metrics, and present multiple strong baselines. Importantly, we propose the novel PoDS architecture with a shared backbone, an OOD contextual module for learning global and local OOD object cues, and dual symmetrical decoders with task-specific heads that employ our alignment-mismatch strategy for better OOD generalization. Combined with our data augmentation strategy, this approach facilitates progressive learning of out-of-distribution objects while maintaining in-distribution performance. We perform extensive evaluations that demonstrate that our proposed PoDS network effectively addresses the main challenges and substantially outperforms the baselines. We make the dataset, code, and trained models publicly available at http://pods.cs.uni-freiburg.de.
Fairness and Bias in Robot Learning
Jul 07, 2022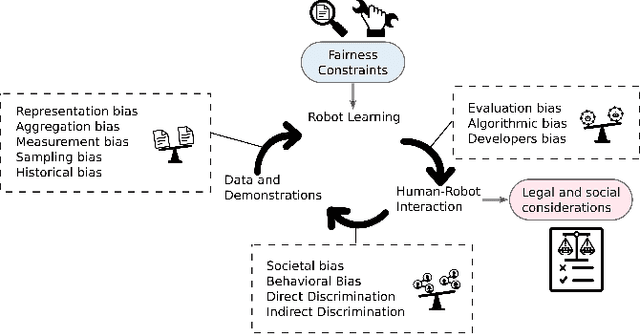
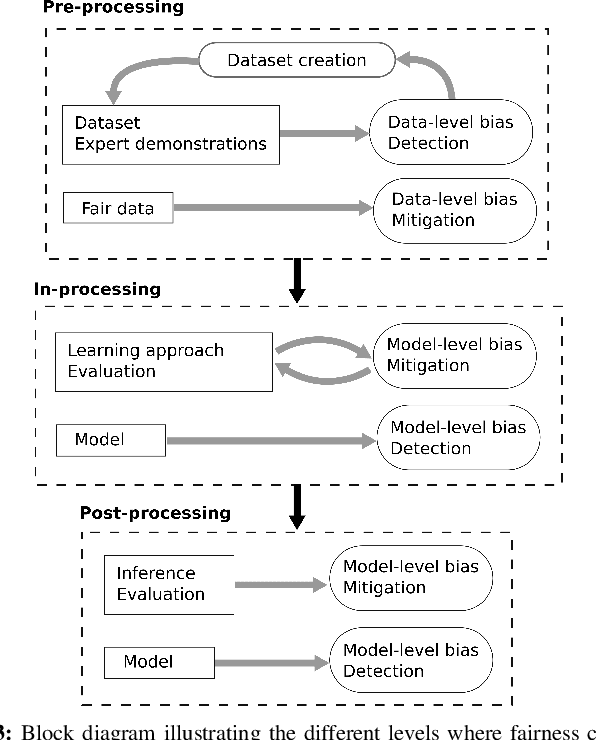
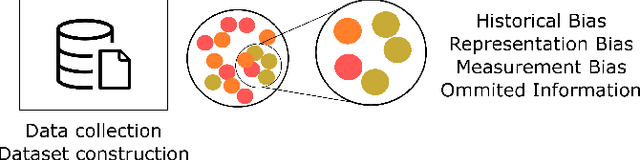
Machine learning has significantly enhanced the abilities of robots, enabling them to perform a wide range of tasks in human environments and adapt to our uncertain real world. Recent works in various domains of machine learning have highlighted the importance of accounting for fairness to ensure that these algorithms do not reproduce human biases and consequently lead to discriminatory outcomes. With robot learning systems increasingly performing more and more tasks in our everyday lives, it is crucial to understand the influence of such biases to prevent unintended behavior toward certain groups of people. In this work, we present the first survey on fairness in robot learning from an interdisciplinary perspective spanning technical, ethical, and legal challenges. We propose a taxonomy for sources of bias and the resulting types of discrimination due to them. Using examples from different robot learning domains, we examine scenarios of unfair outcomes and strategies to mitigate them. We present early advances in the field by covering different fairness definitions, ethical and legal considerations, and methods for fair robot learning. With this work, we aim at paving the road for groundbreaking developments in fair robot learning.
Feminist Perspective on Robot Learning Processes
Jan 26, 2022As different research works report and daily life experiences confirm, learning models can result in biased outcomes. The biased learned models usually replicate historical discrimination in society and typically negatively affect the less represented identities. Robots are equipped with these models that allow them to operate, performing tasks more complex every day. The learning process consists of different stages depending on human judgments. Moreover, the resulting learned models for robot decisions rely on recorded labeled data or demonstrations. Therefore, the robot learning process is susceptible to bias linked to human behavior in society. This imposes a potential danger, especially when robots operate around humans and the learning process can reflect the social unfairness present today. Different feminist proposals study social inequality and provide essential perspectives towards removing bias in various fields. What is more, feminism allowed and still allows to reconfigure numerous social dynamics and stereotypes advocating for equality across people through their diversity. Consequently, we provide a feminist perspective on the robot learning process in this work. We base our discussion on intersectional feminism, community feminism, decolonial feminism, and pedagogy perspectives, and we frame our work in a feminist robotics approach. In this paper, we present an initial discussion to emphasize the relevance of feminist perspectives to explore, foresee, en eventually correct the biased robot decisions.
Panoptic nuScenes: A Large-Scale Benchmark for LiDAR Panoptic Segmentation and Tracking
Sep 10, 2021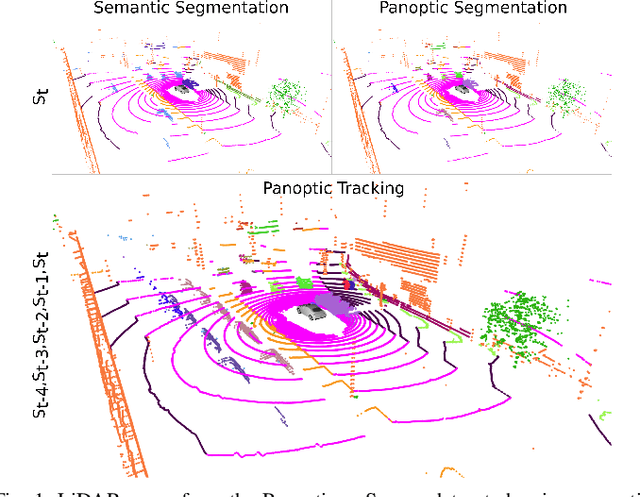
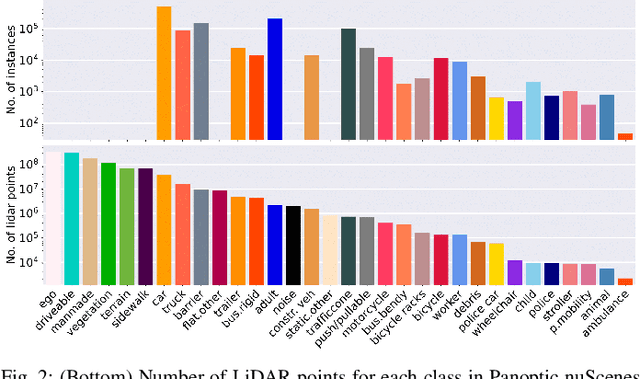
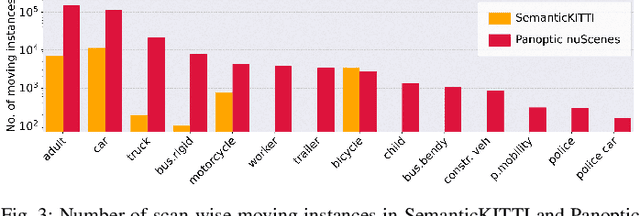
Panoptic scene understanding and tracking of dynamic agents are essential for robots and automated vehicles to navigate in urban environments. As LiDARs provide accurate illumination-independent geometric depictions of the scene, performing these tasks using LiDAR point clouds provides reliable predictions. However, existing datasets lack diversity in the type of urban scenes and have a limited number of dynamic object instances which hinders both learning of these tasks as well as credible benchmarking of the developed methods. In this paper, we introduce the large-scale Panoptic nuScenes benchmark dataset that extends our popular nuScenes dataset with point-wise groundtruth annotations for semantic segmentation, panoptic segmentation, and panoptic tracking tasks. To facilitate comparison, we provide several strong baselines for each of these tasks on our proposed dataset. Moreover, we analyze the drawbacks of the existing metrics for panoptic tracking and propose the novel instance-centric PAT metric that addresses the concerns. We present exhaustive experiments that demonstrate the utility of Panoptic nuScenes compared to existing datasets and make the online evaluation server available at nuScenes.org. We believe that this extension will accelerate the research of novel methods for scene understanding of dynamic urban environments.
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge
Mar 01, 2021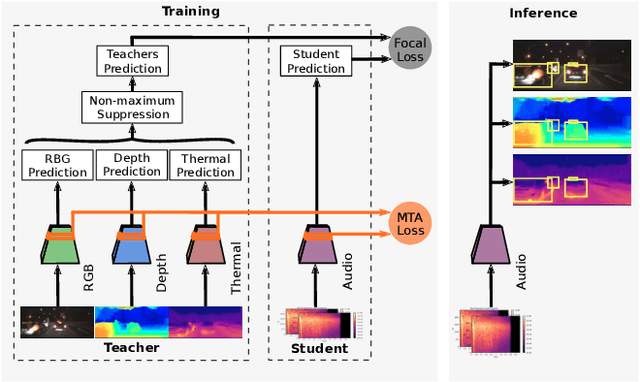
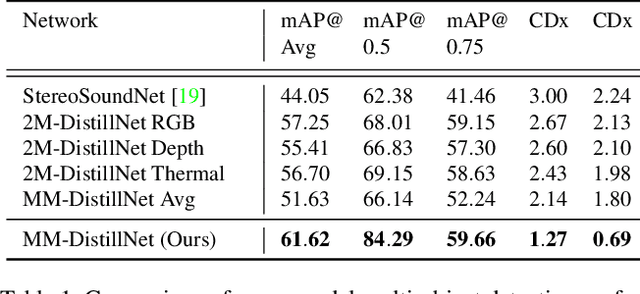

Attributes of sound inherent to objects can provide valuable cues to learn rich representations for object detection and tracking. Furthermore, the co-occurrence of audiovisual events in videos can be exploited to localize objects over the image field by solely monitoring the sound in the environment. Thus far, this has only been feasible in scenarios where the camera is static and for single object detection. Moreover, the robustness of these methods has been limited as they primarily rely on RGB images which are highly susceptible to illumination and weather changes. In this work, we present the novel self-supervised MM-DistillNet framework consisting of multiple teachers that leverage diverse modalities including RGB, depth and thermal images, to simultaneously exploit complementary cues and distill knowledge into a single audio student network. We propose the new MTA loss function that facilitates the distillation of information from multimodal teachers in a self-supervised manner. Additionally, we propose a novel self-supervised pretext task for the audio student that enables us to not rely on labor-intensive manual annotations. We introduce a large-scale multimodal dataset with over 113,000 time-synchronized frames of RGB, depth, thermal, and audio modalities. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods while being able to detect multiple objects using only sound during inference and even while moving.
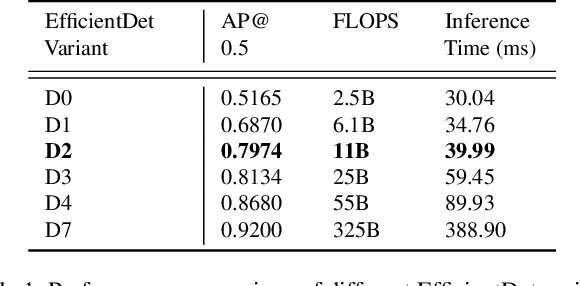
From Learning to Relearning: A Framework for Diminishing Bias in Social Robot Navigation
Jan 07, 2021
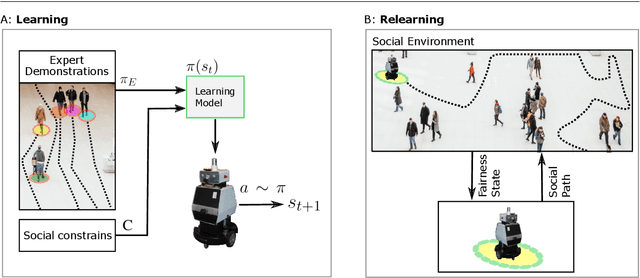
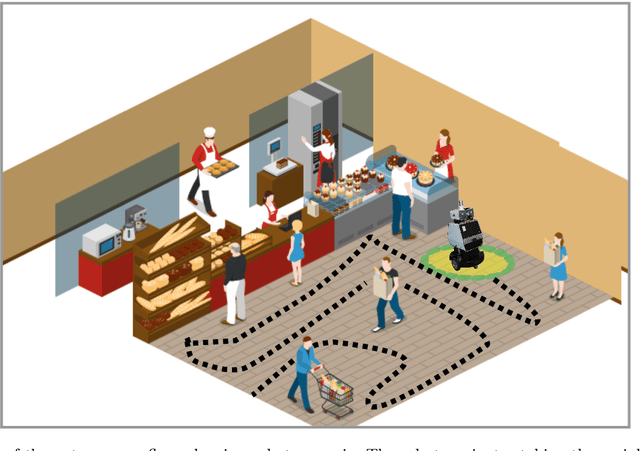
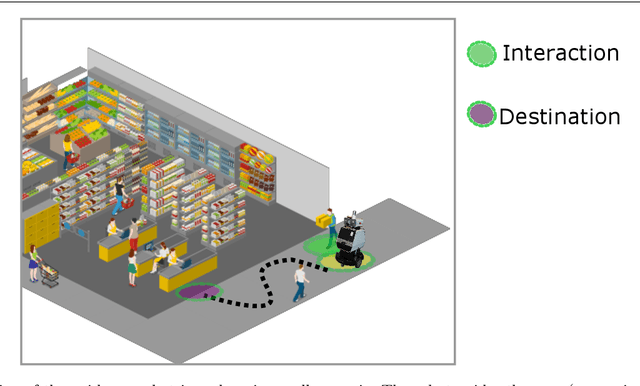
The exponentially increasing advances in robotics and machine learning are facilitating the transition of robots from being confined to controlled industrial spaces to performing novel everyday tasks in domestic and urban environments. In order to make the presence of robots safe as well as comfortable for humans, and to facilitate their acceptance in public environments, they are often equipped with social abilities for navigation and interaction. Socially compliant robot navigation is increasingly being learned from human observations or demonstrations. We argue that these techniques that typically aim to mimic human behavior do not guarantee fair behavior. As a consequence, social navigation models can replicate, promote, and amplify societal unfairness such as discrimination and segregation. In this work, we investigate a framework for diminishing bias in social robot navigation models so that robots are equipped with the capability to plan as well as adapt their paths based on both physical and social demands. Our proposed framework consists of two components: learning which incorporates social context into the learning process to account for safety and comfort, and relearning to detect and correct potentially harmful outcomes before the onset. We provide both technological and sociological analysis using three diverse case studies in different social scenarios of interaction. Moreover, we present ethical implications of deploying robots in social environments and propose potential solutions. Through this study, we highlight the importance and advocate for fairness in human-robot interactions in order to promote more equitable social relationships, roles, and dynamics and consequently positively influence our society.