 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic-Depth Forecasting
Sep 18, 2024
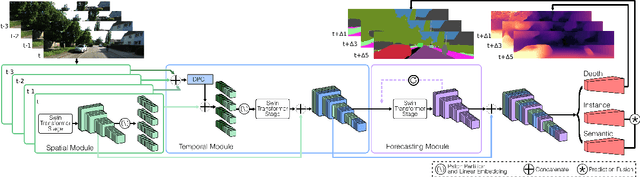

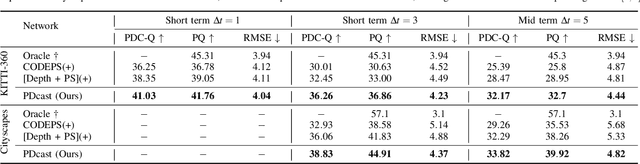
Forecasting the semantics and 3D structure of scenes is essential for robots to navigate and plan actions safely. Recent methods have explored semantic and panoptic scene forecasting; however, they do not consider the geometry of the scene. In this work, we propose the panoptic-depth forecasting task for jointly predicting the panoptic segmentation and depth maps of unobserved future frames, from monocular camera images. To facilitate this work, we extend the popular KITTI-360 and Cityscapes benchmarks by computing depth maps from LiDAR point clouds and leveraging sequential labeled data. We also introduce a suitable evaluation metric that quantifies both the panoptic quality and depth estimation accuracy of forecasts in a coherent manner. Furthermore, we present two baselines and propose the novel PDcast architecture that learns rich spatio-temporal representations by incorporating a transformer-based encoder, a forecasting module, and task-specific decoders to predict future panoptic-depth outputs. Extensive evaluations demonstrate the effectiveness of PDcast across two datasets and three forecasting tasks, consistently addressing the primary challenges. We make the code publicly available at https://pdcast.cs.uni-freiburg.de.