 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOTT: Box Only Transformer Tracker for 3D Object Tracking
Aug 17, 2023Tracking 3D objects is an important task in autonomous driving. Classical Kalman Filtering based methods are still the most popular solutions. However, these methods require handcrafted designs in motion modeling and can not benefit from the growing data amounts. In this paper, Box Only Transformer Tracker (BOTT) is proposed to learn to link 3D boxes of the same object from the different frames, by taking all the 3D boxes in a time window as input. Specifically, transformer self-attention is applied to exchange information between all the boxes to learn global-informative box embeddings. The similarity between these learned embeddings can be used to link the boxes of the same object. BOTT can be used for both online and offline tracking modes seamlessly. Its simplicity enables us to significantly reduce engineering efforts required by traditional Kalman Filtering based methods. Experiments show BOTT achieves competitive performance on two largest 3D MOT benchmarks: 69.9 and 66.7 AMOTA on nuScenes validation and test splits, respectively, 56.45 and 59.57 MOTA L2 on Waymo Open Dataset validation and test splits, respectively. This work suggests that tracking 3D objects by learning features directly from 3D boxes using transformers is a simple yet effective way.
Panoptic nuScenes: A Large-Scale Benchmark for LiDAR Panoptic Segmentation and Tracking
Sep 10, 2021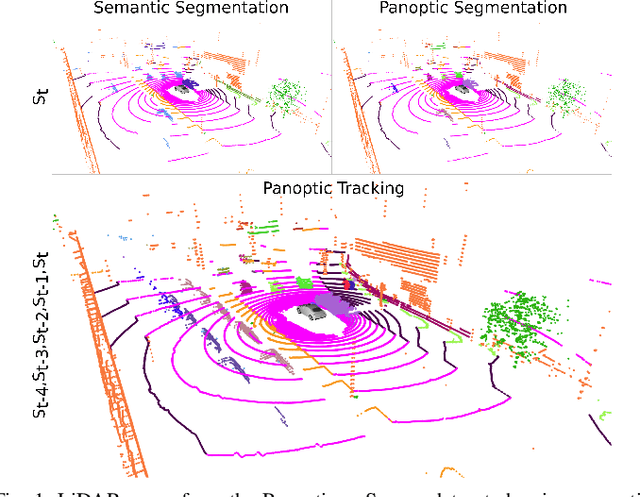
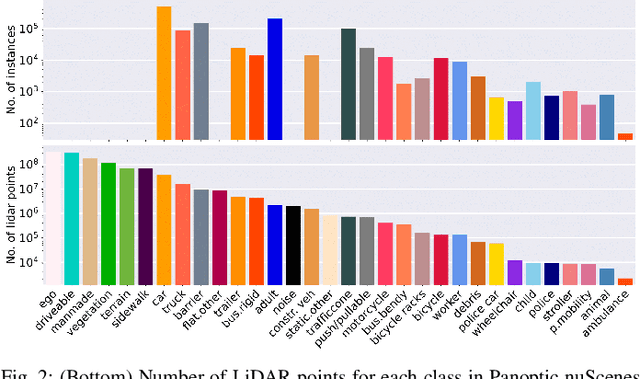
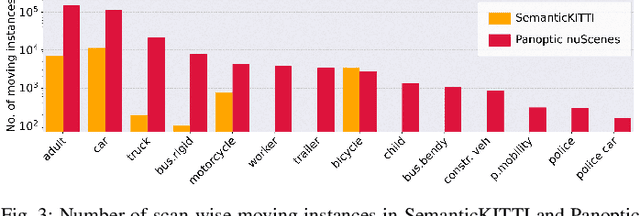
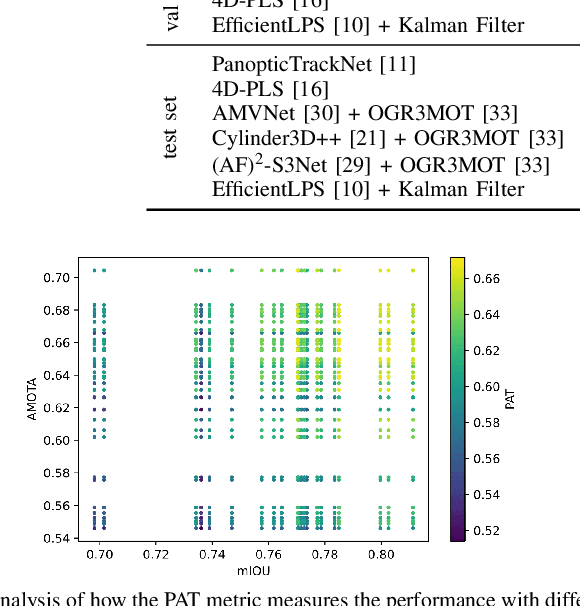
Panoptic scene understanding and tracking of dynamic agents are essential for robots and automated vehicles to navigate in urban environments. As LiDARs provide accurate illumination-independent geometric depictions of the scene, performing these tasks using LiDAR point clouds provides reliable predictions. However, existing datasets lack diversity in the type of urban scenes and have a limited number of dynamic object instances which hinders both learning of these tasks as well as credible benchmarking of the developed methods. In this paper, we introduce the large-scale Panoptic nuScenes benchmark dataset that extends our popular nuScenes dataset with point-wise groundtruth annotations for semantic segmentation, panoptic segmentation, and panoptic tracking tasks. To facilitate comparison, we provide several strong baselines for each of these tasks on our proposed dataset. Moreover, we analyze the drawbacks of the existing metrics for panoptic tracking and propose the novel instance-centric PAT metric that addresses the concerns. We present exhaustive experiments that demonstrate the utility of Panoptic nuScenes compared to existing datasets and make the online evaluation server available at nuScenes.org. We believe that this extension will accelerate the research of novel methods for scene understanding of dynamic urban environments.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Dec 14, 2018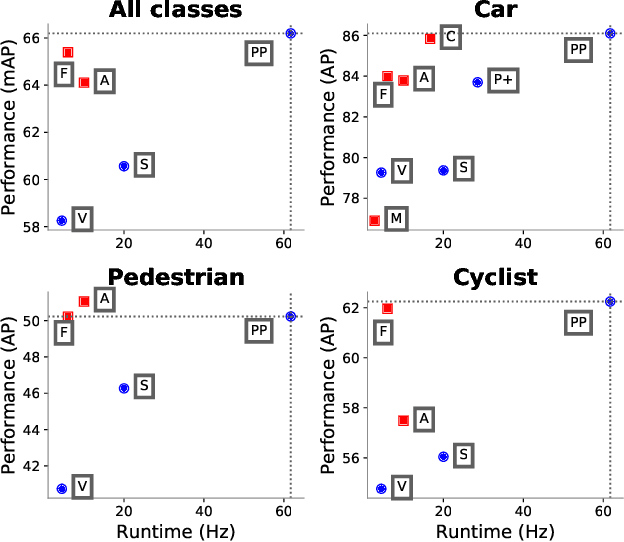

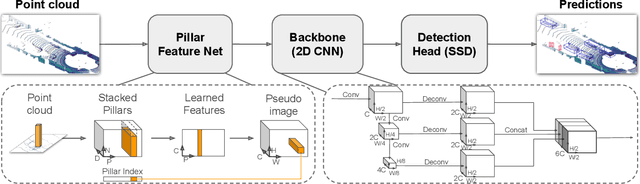

Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.