 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards learning-based planning:The nuPlan benchmark for real-world autonomous driving
Mar 07, 2024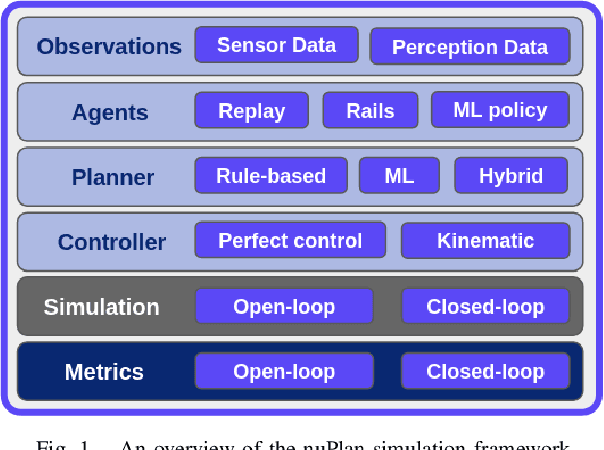
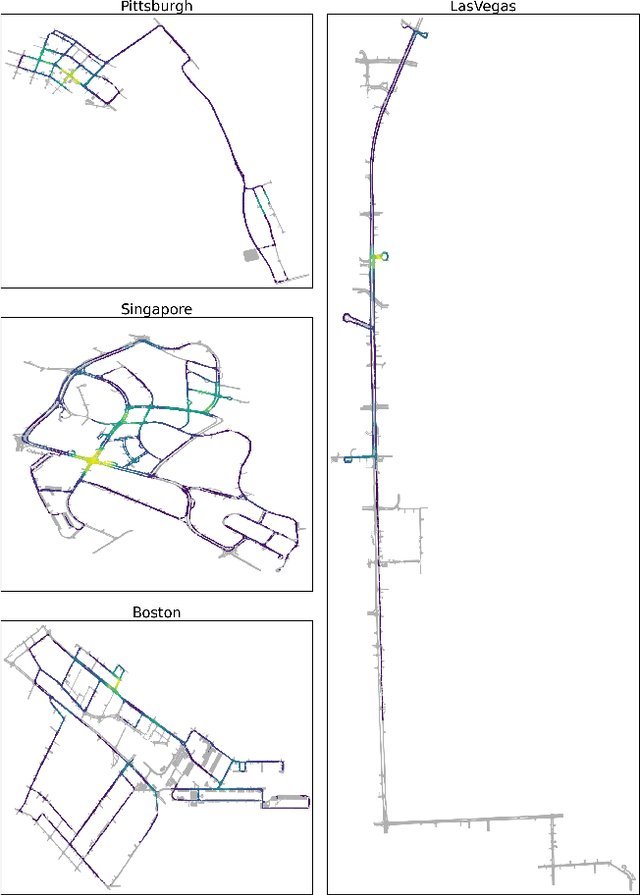
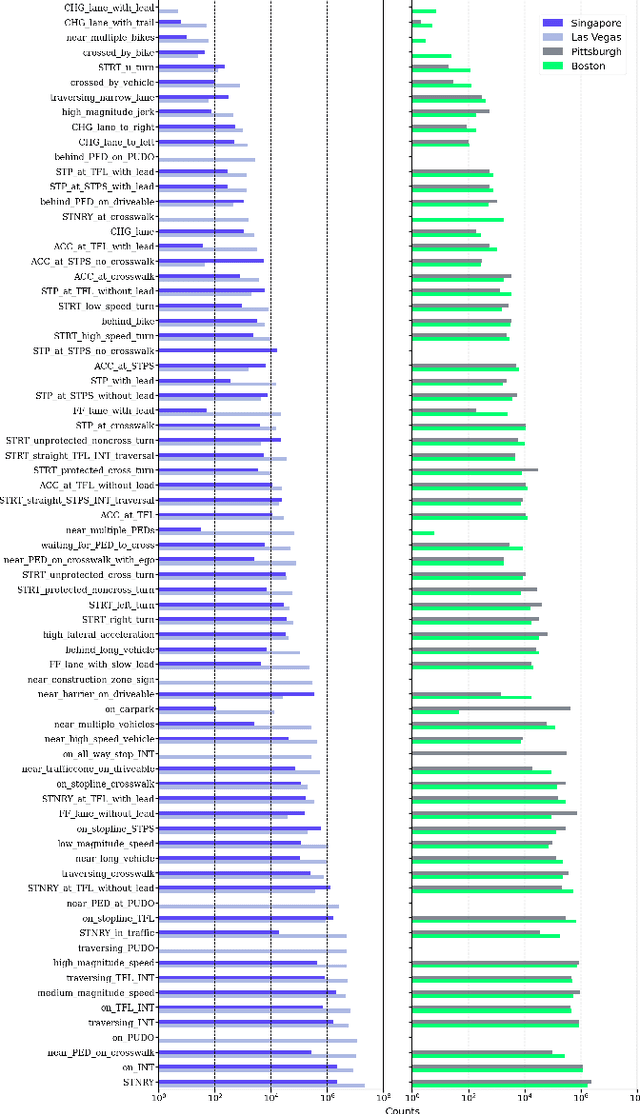
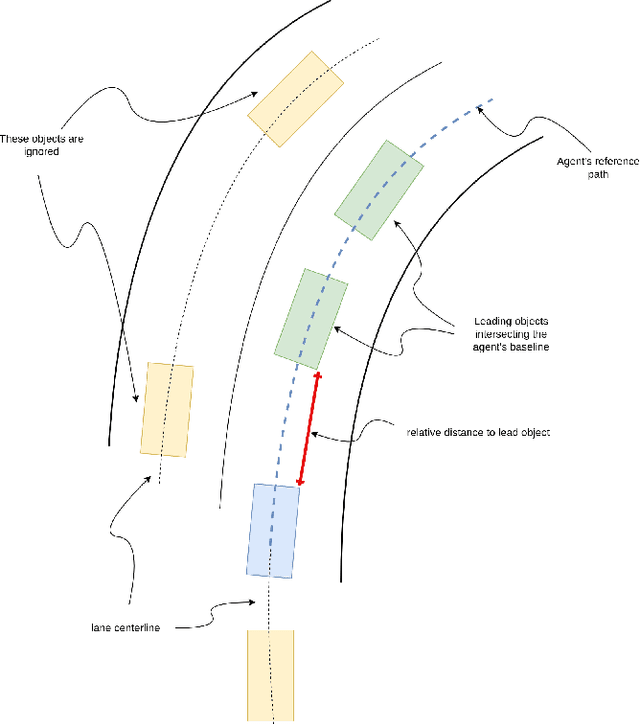
Machine Learning (ML) has replaced traditional handcrafted methods for perception and prediction in autonomous vehicles. Yet for the equally important planning task, the adoption of ML-based techniques is slow. We present nuPlan, the world's first real-world autonomous driving dataset, and benchmark. The benchmark is designed to test the ability of ML-based planners to handle diverse driving situations and to make safe and efficient decisions. To that end, we introduce a new large-scale dataset that consists of 1282 hours of diverse driving scenarios from 4 cities (Las Vegas, Boston, Pittsburgh, and Singapore) and includes high-quality auto-labeled object tracks and traffic light data. We exhaustively mine and taxonomize common and rare driving scenarios which are used during evaluation to get fine-grained insights into the performance and characteristics of a planner. Beyond the dataset, we provide a simulation and evaluation framework that enables a planner's actions to be simulated in closed-loop to account for interactions with other traffic participants. We present a detailed analysis of numerous baselines and investigate gaps between ML-based and traditional methods. Find the nuPlan dataset and code at nuplan.org.
BOTT: Box Only Transformer Tracker for 3D Object Tracking
Aug 17, 2023Tracking 3D objects is an important task in autonomous driving. Classical Kalman Filtering based methods are still the most popular solutions. However, these methods require handcrafted designs in motion modeling and can not benefit from the growing data amounts. In this paper, Box Only Transformer Tracker (BOTT) is proposed to learn to link 3D boxes of the same object from the different frames, by taking all the 3D boxes in a time window as input. Specifically, transformer self-attention is applied to exchange information between all the boxes to learn global-informative box embeddings. The similarity between these learned embeddings can be used to link the boxes of the same object. BOTT can be used for both online and offline tracking modes seamlessly. Its simplicity enables us to significantly reduce engineering efforts required by traditional Kalman Filtering based methods. Experiments show BOTT achieves competitive performance on two largest 3D MOT benchmarks: 69.9 and 66.7 AMOTA on nuScenes validation and test splits, respectively, 56.45 and 59.57 MOTA L2 on Waymo Open Dataset validation and test splits, respectively. This work suggests that tracking 3D objects by learning features directly from 3D boxes using transformers is a simple yet effective way.
MotionTrack: End-to-End Transformer-based Multi-Object Tracing with LiDAR-Camera Fusion
Jun 29, 2023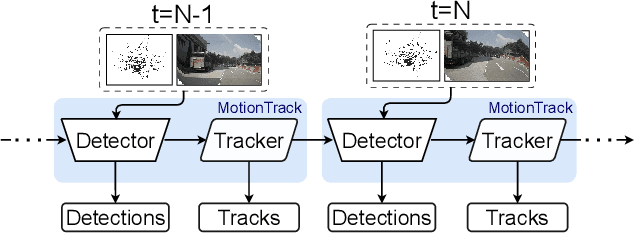

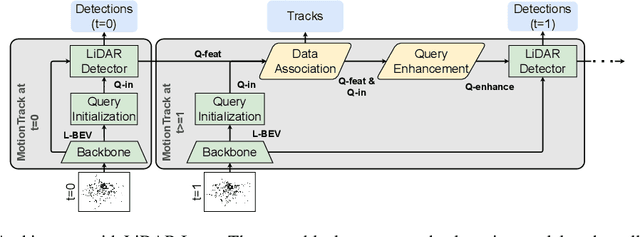
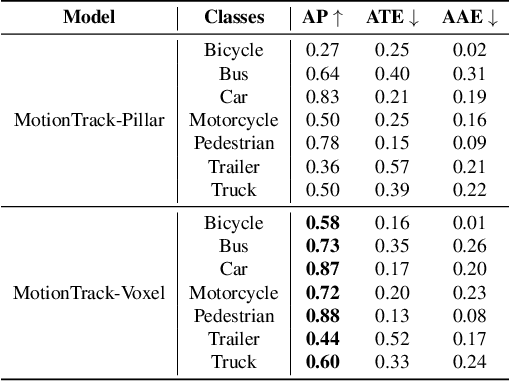
Multiple Object Tracking (MOT) is crucial to autonomous vehicle perception. End-to-end transformer-based algorithms, which detect and track objects simultaneously, show great potential for the MOT task. However, most existing methods focus on image-based tracking with a single object category. In this paper, we propose an end-to-end transformer-based MOT algorithm (MotionTrack) with multi-modality sensor inputs to track objects with multiple classes. Our objective is to establish a transformer baseline for the MOT in an autonomous driving environment. The proposed algorithm consists of a transformer-based data association (DA) module and a transformer-based query enhancement module to achieve MOT and Multiple Object Detection (MOD) simultaneously. The MotionTrack and its variations achieve better results (AMOTA score at 0.55) on the nuScenes dataset compared with other classical baseline models, such as the AB3DMOT, the CenterTrack, and the probabilistic 3D Kalman filter. In addition, we prove that a modified attention mechanism can be utilized for DA to accomplish the MOT, and aggregate history features to enhance the MOD performance.
The efficacy of Neural Planning Metrics: A meta-analysis of PKL on nuScenes
Oct 24, 2020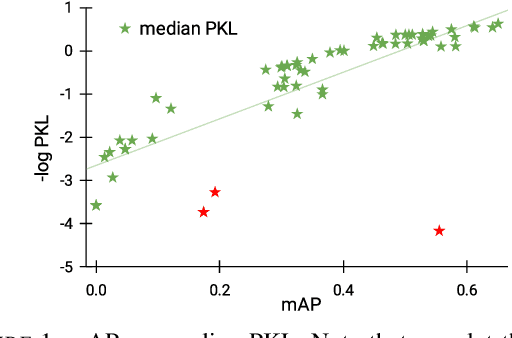
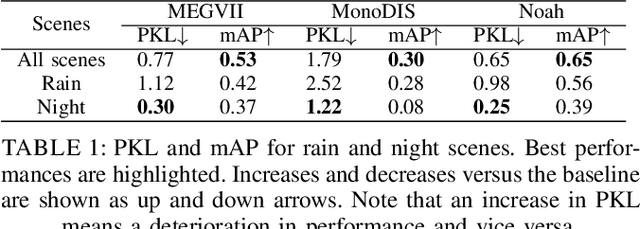
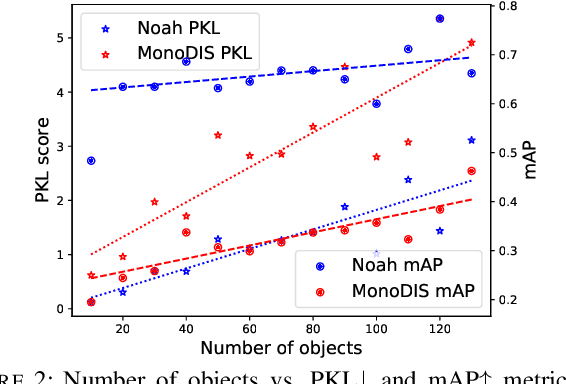
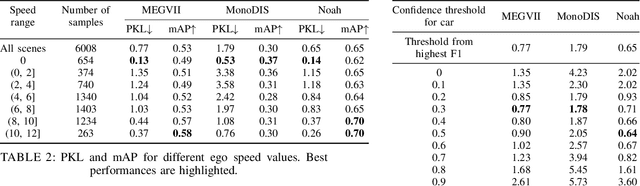
A high-performing object detection system plays a crucial role in autonomous driving (AD). The performance, typically evaluated in terms of mean Average Precision, does not take into account orientation and distance of the actors in the scene, which are important for the safe AD. It also ignores environmental context. Recently, Philion et al. proposed a neural planning metric (PKL), based on the KL divergence of a planner's trajectory and the groundtruth route, to accommodate these requirements. In this paper, we use this neural planning metric to score all submissions of the nuScenes detection challenge and analyze the results. We find that while somewhat correlated with mAP, the PKL metric shows different behavior to increased traffic density, ego velocity, road curvature and intersections. Finally, we propose ideas to extend the neural planning metric.
Efficient and Deep Person Re-Identification using Multi-Level Similarity
Apr 02, 2018



Person Re-Identification (ReID) requires comparing two images of person captured under different conditions. Existing work based on neural networks often computes the similarity of feature maps from one single convolutional layer. In this work, we propose an efficient, end-to-end fully convolutional Siamese network that computes the similarities at multiple levels. We demonstrate that multi-level similarity can improve the accuracy considerably using low-complexity network structures in ReID problem. Specifically, first, we use several convolutional layers to extract the features of two input images. Then, we propose Convolution Similarity Network to compute the similarity score maps for the inputs. We use spatial transformer networks (STNs) to determine spatial attention. We propose to apply efficient depth-wise convolution to compute the similarity. The proposed Convolution Similarity Networks can be inserted into different convolutional layers to extract visual similarities at different levels. Furthermore, we use an improved ranking loss to further improve the performance. Our work is the first to propose to compute visual similarities at low, middle and high levels for ReID. With extensive experiments and analysis, we demonstrate that our system, compact yet effective, can achieve competitive results with much smaller model size and computational complexity.
Deep neural networks on graph signals for brain imaging analysis
May 13, 2017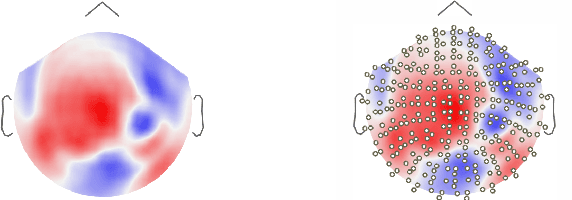
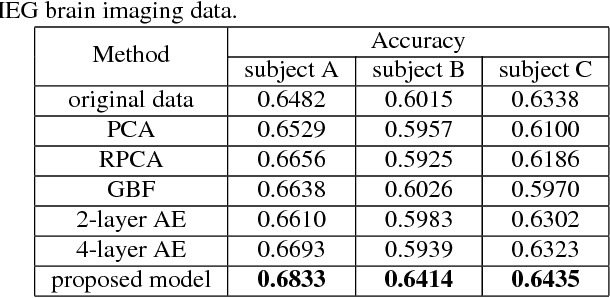
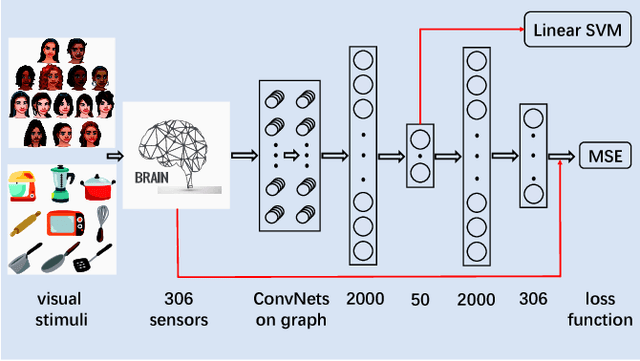
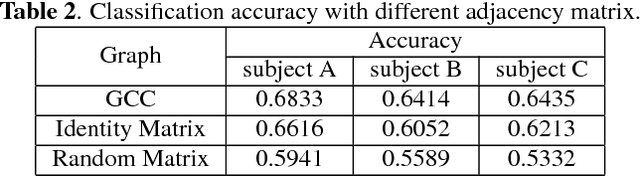
Brain imaging data such as EEG or MEG are high-dimensional spatiotemporal data often degraded by complex, non-Gaussian noise. For reliable analysis of brain imaging data, it is important to extract discriminative, low-dimensional intrinsic representation of the recorded data. This work proposes a new method to learn the low-dimensional representations from the noise-degraded measurements. In particular, our work proposes a new deep neural network design that integrates graph information such as brain connectivity with fully-connected layers. Our work leverages efficient graph filter design using Chebyshev polynomial and recent work on convolutional nets on graph-structured data. Our approach exploits graph structure as the prior side information, localized graph filter for feature extraction and neural networks for high capacity learning. Experiments on real MEG datasets show that our approach can extract more discriminative representations, leading to improved accuracy in a supervised classification task.