 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionTrack: End-to-End Transformer-based Multi-Object Tracing with LiDAR-Camera Fusion
Jun 29, 2023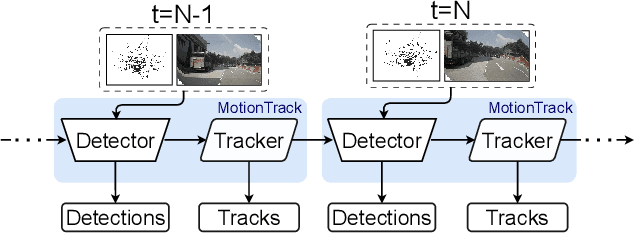

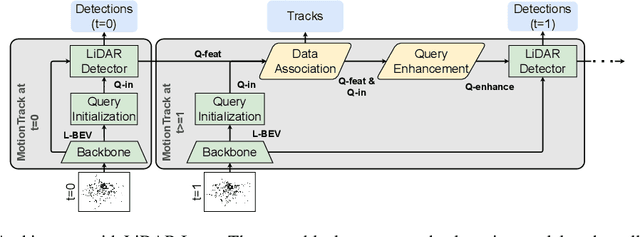
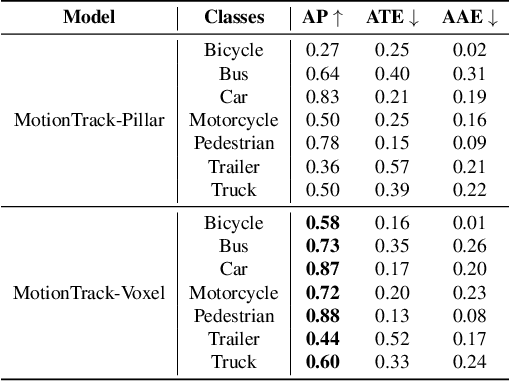
Multiple Object Tracking (MOT) is crucial to autonomous vehicle perception. End-to-end transformer-based algorithms, which detect and track objects simultaneously, show great potential for the MOT task. However, most existing methods focus on image-based tracking with a single object category. In this paper, we propose an end-to-end transformer-based MOT algorithm (MotionTrack) with multi-modality sensor inputs to track objects with multiple classes. Our objective is to establish a transformer baseline for the MOT in an autonomous driving environment. The proposed algorithm consists of a transformer-based data association (DA) module and a transformer-based query enhancement module to achieve MOT and Multiple Object Detection (MOD) simultaneously. The MotionTrack and its variations achieve better results (AMOTA score at 0.55) on the nuScenes dataset compared with other classical baseline models, such as the AB3DMOT, the CenterTrack, and the probabilistic 3D Kalman filter. In addition, we prove that a modified attention mechanism can be utilized for DA to accomplish the MOT, and aggregate history features to enhance the MOD performance.
ADCNet: End-to-end perception with raw radar ADC data
Mar 28, 2023There is a renewed interest in radar sensors in the autonomous driving industry. As a relatively mature technology, radars have seen steady improvement over the last few years, making them an appealing alternative or complement to the commonly used LiDARs. An emerging trend is to leverage rich, low-level radar data for perception. In this work we push this trend to the extreme -- we propose a method to perform end-to-end learning on the raw radar analog-to-digital (ADC) data. Specifically, we design a learnable signal processing module inside the neural network, and a pre-training method guided by traditional signal processing algorithms. Experiment results corroborate the overall efficacy of the end-to-end learning method, while an ablation study validates the effectiveness of our individual innovations.
Joint Pose and Shape Estimation of Vehicles from LiDAR Data
Sep 08, 2020

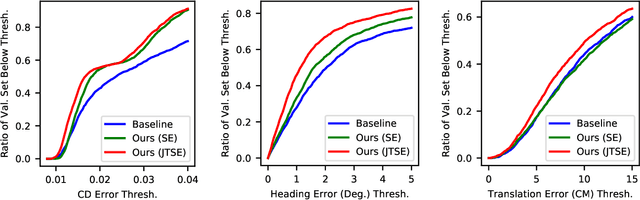
We address the problem of estimating the pose and shape of vehicles from LiDAR scans, a common problem faced by the autonomous vehicle community. Recent work has tended to address pose and shape estimation separately in isolation, despite the inherent connection between the two. We investigate a method of jointly estimating shape and pose where a single encoding is learned from which shape and pose may be decoded in an efficient yet effective manner. We additionally introduce a novel joint pose and shape loss, and show that this joint training method produces better results than independently-trained pose and shape estimators. We evaluate our method on both synthetic data and real-world data, and show superior performance against a state-of-the-art baseline.
Geometry-Aware Instance Segmentation with Disparity Maps
Jun 14, 2020
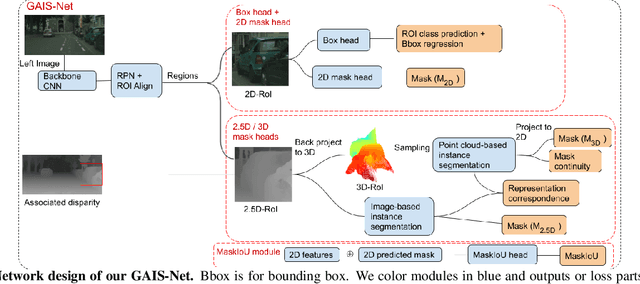
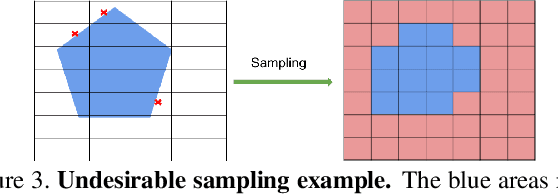

Most previous works of outdoor instance segmentation for images only use color information. We explore a novel direction of sensor fusion to exploit stereo cameras. Geometric information from disparities helps separate overlapping objects of the same or different classes. Moreover, geometric information penalizes region proposals with unlikely 3D shapes thus suppressing false positive detections. Mask regression is based on 2D, 2.5D, and 3D ROI using the pseudo-lidar and image-based representations. These mask predictions are fused by a mask scoring process. However, public datasets only adopt stereo systems with shorter baseline and focal legnth, which limit measuring ranges of stereo cameras. We collect and utilize High-Quality Driving Stereo (HQDS) dataset, using much longer baseline and focal length with higher resolution. Our performance attains state of the art. Please refer to our project page. The full paper is available here.
Hierarchical Deep Stereo Matching on High-resolution Images
Dec 13, 2019


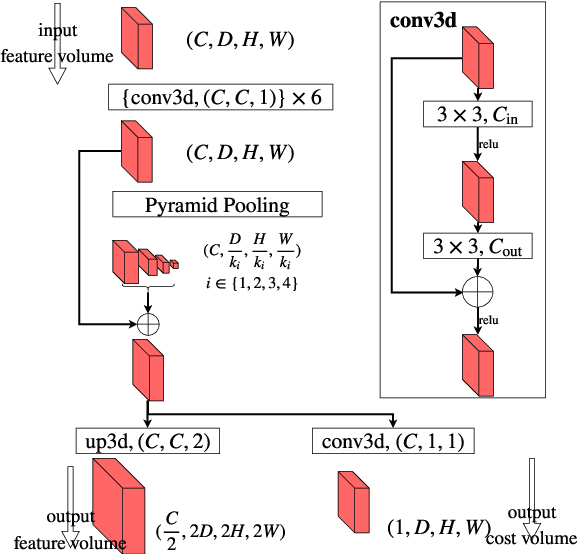
We explore the problem of real-time stereo matching on high-res imagery. Many state-of-the-art (SOTA) methods struggle to process high-res imagery because of memory constraints or speed limitations. To address this issue, we propose an end-to-end framework that searches for correspondences incrementally over a coarse-to-fine hierarchy. Because high-res stereo datasets are relatively rare, we introduce a dataset with high-res stereo pairs for both training and evaluation. Our approach achieved SOTA performance on Middlebury-v3 and KITTI-15 while running significantly faster than its competitors. The hierarchical design also naturally allows for anytime on-demand reports of disparity by capping intermediate coarse results, allowing us to accurately predict disparity for near-range structures with low latency (30ms). We demonstrate that the performance-vs-speed trade-off afforded by on-demand hierarchies may address sensing needs for time-critical applications such as autonomous driving.