 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGEER: Exact and Efficient Volumetric Rendering with 3D Gaussians
May 29, 20253D Gaussian Splatting (3DGS) marks a significant milestone in balancing the quality and efficiency of differentiable rendering. However, its high efficiency stems from an approximation of projecting 3D Gaussians onto the image plane as 2D Gaussians, which inherently limits rendering quality--particularly under large Field-of-View (FoV) camera inputs. While several recent works have extended 3DGS to mitigate these approximation errors, none have successfully achieved both exactness and high efficiency simultaneously. In this work, we introduce 3DGEER, an Exact and Efficient Volumetric Gaussian Rendering method. Starting from first principles, we derive a closed-form expression for the density integral along a ray traversing a 3D Gaussian distribution. This formulation enables precise forward rendering with arbitrary camera models and supports gradient-based optimization of 3D Gaussian parameters. To ensure both exactness and real-time performance, we propose an efficient method for computing a tight Particle Bounding Frustum (PBF) for each 3D Gaussian, enabling accurate and efficient ray-Gaussian association. We also introduce a novel Bipolar Equiangular Projection (BEAP) representation to accelerate ray association under generic camera models. BEAP further provides a more uniform ray sampling strategy to apply supervision, which empirically improves reconstruction quality. Experiments on multiple pinhole and fisheye datasets show that our method consistently outperforms prior methods, establishing a new state-of-the-art in real-time neural rendering.
Online Language Splatting
Mar 12, 2025To enable AI agents to interact seamlessly with both humans and 3D environments, they must not only perceive the 3D world accurately but also align human language with 3D spatial representations. While prior work has made significant progress by integrating language features into geometrically detailed 3D scene representations using 3D Gaussian Splatting (GS), these approaches rely on computationally intensive offline preprocessing of language features for each input image, limiting adaptability to new environments. In this work, we introduce Online Language Splatting, the first framework to achieve online, near real-time, open-vocabulary language mapping within a 3DGS-SLAM system without requiring pre-generated language features. The key challenge lies in efficiently fusing high-dimensional language features into 3D representations while balancing the computation speed, memory usage, rendering quality and open-vocabulary capability. To this end, we innovatively design: (1) a high-resolution CLIP embedding module capable of generating detailed language feature maps in 18ms per frame, (2) a two-stage online auto-encoder that compresses 768-dimensional CLIP features to 15 dimensions while preserving open-vocabulary capabilities, and (3) a color-language disentangled optimization approach to improve rendering quality. Experimental results show that our online method not only surpasses the state-of-the-art offline methods in accuracy but also achieves more than 40x efficiency boost, demonstrating the potential for dynamic and interactive AI applications.
Boosting Generalizability towards Zero-Shot Cross-Dataset Single-Image Indoor Depth by Meta-Initialization
Sep 04, 2024Indoor robots rely on depth to perform tasks like navigation or obstacle detection, and single-image depth estimation is widely used to assist perception. Most indoor single-image depth prediction focuses less on model generalizability to unseen datasets, concerned with in-the-wild robustness for system deployment. This work leverages gradient-based meta-learning to gain higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied meta-learning of image classification associated with explicit class labels, no explicit task boundaries exist for continuous depth values tied to highly varying indoor environments regarding object arrangement and scene composition. We propose fine-grained task that treats each RGB-D mini-batch as a task in our meta-learning formulation. We first show that our method on limited data induces a much better prior (max 27.8% in RMSE). Then, finetuning on meta-learned initialization consistently outperforms baselines without the meta approach. Aiming at generalization, we propose zero-shot cross-dataset protocols and validate higher generalizability induced by our meta-initialization, as a simple and useful plugin to many existing depth estimation methods. The work at the intersection of depth and meta-learning potentially drives both research to step closer to practical robotic and machine perception usage.
InSpaceType: Dataset and Benchmark for Reconsidering Cross-Space Type Performance in Indoor Monocular Depth
Aug 25, 2024Indoor monocular depth estimation helps home automation, including robot navigation or AR/VR for surrounding perception. Most previous methods primarily experiment with the NYUv2 Dataset and concentrate on the overall performance in their evaluation. However, their robustness and generalization to diversely unseen types or categories for indoor spaces (spaces types) have yet to be discovered. Researchers may empirically find degraded performance in a released pretrained model on custom data or less-frequent types. This paper studies the common but easily overlooked factor-space type and realizes a model's performance variances across spaces. We present InSpaceType Dataset, a high-quality RGBD dataset for general indoor scenes, and benchmark 13 recent state-of-the-art methods on InSpaceType. Our examination shows that most of them suffer from performance imbalance between head and tailed types, and some top methods are even more severe. The work reveals and analyzes underlying bias in detail for transparency and robustness. We extend the analysis to a total of 4 datasets and discuss the best practice in synthetic data curation for training indoor monocular depth. Further, dataset ablation is conducted to find out the key factor in generalization. This work marks the first in-depth investigation of performance variances across space types and, more importantly, releases useful tools, including datasets and codes, to closely examine your pretrained depth models. Data and code: https://depthcomputation.github.io/DepthPublic/
InSpaceType: Reconsider Space Type in Indoor Monocular Depth Estimation
Sep 24, 2023Indoor monocular depth estimation has attracted increasing research interest. Most previous works have been focusing on methodology, primarily experimenting with NYU-Depth-V2 (NYUv2) Dataset, and only concentrated on the overall performance over the test set. However, little is known regarding robustness and generalization when it comes to applying monocular depth estimation methods to real-world scenarios where highly varying and diverse functional \textit{space types} are present such as library or kitchen. A study for performance breakdown into space types is essential to realize a pretrained model's performance variance. To facilitate our investigation for robustness and address limitations of previous works, we collect InSpaceType, a high-quality and high-resolution RGBD dataset for general indoor environments. We benchmark 11 recent methods on InSpaceType and find they severely suffer from performance imbalance concerning space types, which reveals their underlying bias. We extend our analysis to 4 other datasets, 3 mitigation approaches, and the ability to generalize to unseen space types. Our work marks the first in-depth investigation of performance imbalance across space types for indoor monocular depth estimation, drawing attention to potential safety concerns for model deployment without considering space types, and further shedding light on potential ways to improve robustness. See \url{https://depthcomputation.github.io/DepthPublic} for data.
Meta-Optimization for Higher Model Generalizability in Single-Image Depth Prediction
May 12, 2023



Model generalizability to unseen datasets, concerned with in-the-wild robustness, is less studied for indoor single-image depth prediction. We leverage gradient-based meta-learning for higher generalizability on zero-shot cross-dataset inference. Unlike the most-studied image classification in meta-learning, depth is pixel-level continuous range values, and mappings from each image to depth vary widely across environments. Thus no explicit task boundaries exist. We instead propose fine-grained task that treats each RGB-D pair as a task in our meta-optimization. We first show meta-learning on limited data induces much better prior (max +29.4\%). Using meta-learned weights as initialization for following supervised learning, without involving extra data or information, it consistently outperforms baselines without the method. Compared to most indoor-depth methods that only train/ test on a single dataset, we propose zero-shot cross-dataset protocols, closely evaluate robustness, and show consistently higher generalizability and accuracy by our meta-initialization. The work at the intersection of depth and meta-learning potentially drives both research streams to step closer to practical use.
Cross-Modal Perceptionist: Can Face Geometry be Gleaned from Voices?
Mar 18, 2022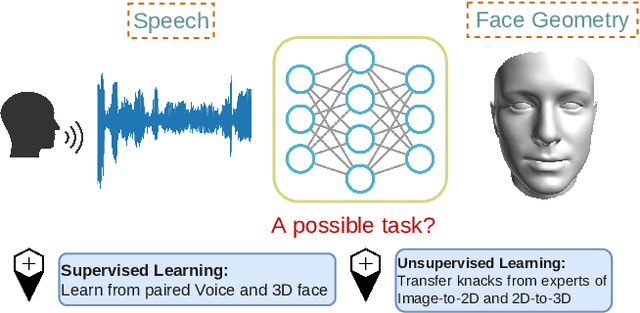

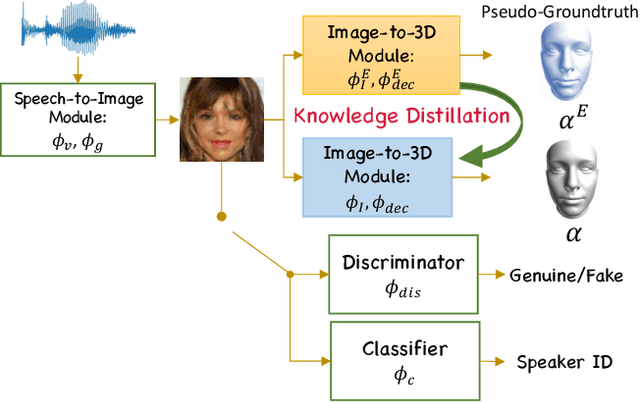
This work digs into a root question in human perception: can face geometry be gleaned from one's voices? Previous works that study this question only adopt developments in image synthesis and convert voices into face images to show correlations, but working on the image domain unavoidably involves predicting attributes that voices cannot hint, including facial textures, hairstyles, and backgrounds. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is much more physiologically grounded. We propose our analysis framework, Cross-Modal Perceptionist, under both supervised and unsupervised learning. First, we construct a dataset, Voxceleb-3D, which extends Voxceleb and includes paired voices and face meshes, making supervised learning possible. Second, we use a knowledge distillation mechanism to study whether face geometry can still be gleaned from voices without paired voices and 3D face data under limited availability of 3D face scans. We break down the core question into four parts and perform visual and numerical analyses as responses to the core question. Our findings echo those in physiology and neuroscience about the correlation between voices and facial structures. The work provides future human-centric cross-modal learning with explainable foundations. See our project page: https://choyingw.github.io/works/Voice2Mesh/index.html
Toward Practical Self-Supervised Monocular Indoor Depth Estimation
Dec 04, 2021



The majority of self-supervised monocular depth estimation methods focus on driving scenarios. We show that such methods generalize poorly to unseen complex indoor scenes, where objects are cluttered and arbitrarily arranged in the near field. To obtain more robustness, we propose a structure distillation approach to learn knacks from a pretrained depth estimator that produces structured but metric-agnostic depth due to its in-the-wild mixed-dataset training. By combining distillation with the self-supervised branch that learns metrics from left-right consistency, we attain structured and metric depth for generic indoor scenes and make inferences in real-time. To facilitate learning and evaluation, we collect SimSIN, a dataset from simulation with thousands of environments, and UniSIN, a dataset that contains about 500 real scan sequences of generic indoor environments. We experiment in both sim-to-real and real-to-real settings, and show improvements both qualitatively and quantitatively, as well as in downstream applications using our depth maps. This work provides a full study, covering methods, data, and applications. We believe the work lays a solid basis for practical indoor depth estimation via self-supervision.
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 20, 2021


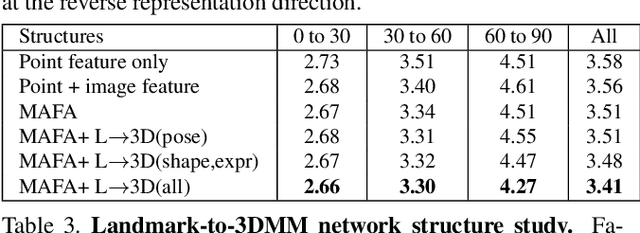
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
Voice2Mesh: Cross-Modal 3D Face Model Generation from Voices
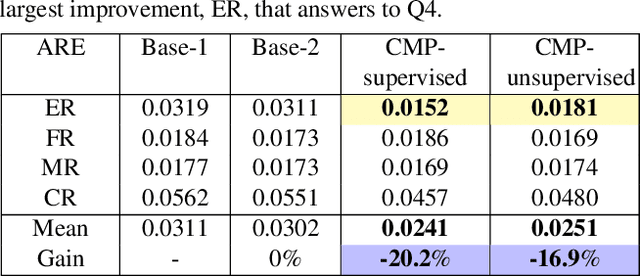
Apr 21, 2021

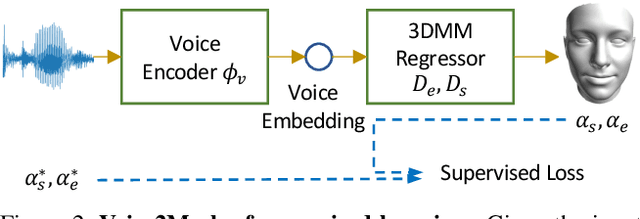

This work focuses on the analysis that whether 3D face models can be learned from only the speech inputs of speakers. Previous works for cross-modal face synthesis study image generation from voices. However, image synthesis includes variations such as hairstyles, backgrounds, and facial textures, that are arguably irrelevant to voice or without direct studies to show correlations. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is more physiologically grounded. We propose both the supervised learning and unsupervised learning frameworks. Especially we demonstrate how unsupervised learning is possible in the absence of a direct voice-to-3D-face dataset under limited availability of 3D face scans when the model is equipped with knowledge distillation. To evaluate the performance, we also propose several metrics to measure the geometric fitness of two 3D faces based on points, lines, and regions. We find that 3D face shapes can be reconstructed from voices. Experimental results suggest that 3D faces can be reconstructed from voices, and our method can improve the performance over the baseline. The best performance gains (15% - 20%) on ear-to-ear distance ratio metric (ER) coincides with the intuition that one can roughly envision whether a speaker's face is overall wider or thinner only from a person's voice. See our project page for codes and data.