 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Visual Data Augmentation
Feb 24, 2025Large multimodal models (LMMs) often struggle to recognize novel concepts, as they rely on pre-trained knowledge and have limited ability to capture subtle visual details. Domain-specific knowledge gaps in training also make them prone to confusing visually similar, commonly misrepresented, or low-resource concepts. To help LMMs better align nuanced visual features with language, improving their ability to recognize and reason about novel or rare concepts, we propose a Contrastive visual Data Augmentation (CoDA) strategy. CoDA extracts key contrastive textual and visual features of target concepts against the known concepts they are misrecognized as, and then uses multimodal generative models to produce targeted synthetic data. Automatic filtering of extracted features and augmented images is implemented to guarantee their quality, as verified by human annotators. We show the effectiveness and efficiency of CoDA on low-resource concept and diverse scene recognition datasets including INaturalist and SUN. We additionally collect NovelSpecies, a benchmark dataset consisting of newly discovered animal species that are guaranteed to be unseen by LMMs. LLaVA-1.6 1-shot updating results on these three datasets show CoDA significantly improves SOTA visual data augmentation strategies by 12.3% (NovelSpecies), 5.1% (SUN), and 6.0% (iNat) absolute gains in accuracy.
InSpaceType: Dataset and Benchmark for Reconsidering Cross-Space Type Performance in Indoor Monocular Depth
Aug 25, 2024Indoor monocular depth estimation helps home automation, including robot navigation or AR/VR for surrounding perception. Most previous methods primarily experiment with the NYUv2 Dataset and concentrate on the overall performance in their evaluation. However, their robustness and generalization to diversely unseen types or categories for indoor spaces (spaces types) have yet to be discovered. Researchers may empirically find degraded performance in a released pretrained model on custom data or less-frequent types. This paper studies the common but easily overlooked factor-space type and realizes a model's performance variances across spaces. We present InSpaceType Dataset, a high-quality RGBD dataset for general indoor scenes, and benchmark 13 recent state-of-the-art methods on InSpaceType. Our examination shows that most of them suffer from performance imbalance between head and tailed types, and some top methods are even more severe. The work reveals and analyzes underlying bias in detail for transparency and robustness. We extend the analysis to a total of 4 datasets and discuss the best practice in synthetic data curation for training indoor monocular depth. Further, dataset ablation is conducted to find out the key factor in generalization. This work marks the first in-depth investigation of performance variances across space types and, more importantly, releases useful tools, including datasets and codes, to closely examine your pretrained depth models. Data and code: https://depthcomputation.github.io/DepthPublic/
ARMADA: Attribute-Based Multimodal Data Augmentation
Aug 19, 2024



In Multimodal Language Models (MLMs), the cost of manually annotating high-quality image-text pair data for fine-tuning and alignment is extremely high. While existing multimodal data augmentation frameworks propose ways to augment image-text pairs, they either suffer from semantic inconsistency between texts and images, or generate unrealistic images, causing knowledge gap with real world examples. To address these issues, we propose Attribute-based Multimodal Data Augmentation (ARMADA), a novel multimodal data augmentation method via knowledge-guided manipulation of visual attributes of the mentioned entities. Specifically, we extract entities and their visual attributes from the original text data, then search for alternative values for the visual attributes under the guidance of knowledge bases (KBs) and large language models (LLMs). We then utilize an image-editing model to edit the images with the extracted attributes. ARMADA is a novel multimodal data generation framework that: (i) extracts knowledge-grounded attributes from symbolic KBs for semantically consistent yet distinctive image-text pair generation, (ii) generates visually similar images of disparate categories using neighboring entities in the KB hierarchy, and (iii) uses the commonsense knowledge of LLMs to modulate auxiliary visual attributes such as backgrounds for more robust representation of original entities. Our empirical results over four downstream tasks demonstrate the efficacy of our framework to produce high-quality data and enhance the model performance. This also highlights the need to leverage external knowledge proxies for enhanced interpretability and real-world grounding.
VDebugger: Harnessing Execution Feedback for Debugging Visual Programs
Jun 19, 2024



Visual programs are executable code generated by large language models to address visual reasoning problems. They decompose complex questions into multiple reasoning steps and invoke specialized models for each step to solve the problems. However, these programs are prone to logic errors, with our preliminary evaluation showing that 58% of the total errors are caused by program logic errors. Debugging complex visual programs remains a major bottleneck for visual reasoning. To address this, we introduce VDebugger, a novel critic-refiner framework trained to localize and debug visual programs by tracking execution step by step. VDebugger identifies and corrects program errors leveraging detailed execution feedback, improving interpretability and accuracy. The training data is generated through an automated pipeline that injects errors into correct visual programs using a novel mask-best decoding technique. Evaluations on six datasets demonstrate VDebugger's effectiveness, showing performance improvements of up to 3.2% in downstream task accuracy. Further studies show VDebugger's ability to generalize to unseen tasks, bringing a notable improvement of 2.3% on the unseen COVR task. Code, data and models are made publicly available at https://github.com/shirley-wu/vdebugger/
DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation
Mar 04, 2024



Data analysis is a crucial analytical process to generate in-depth studies and conclusive insights to comprehensively answer a given user query for tabular data. In this work, we aim to propose new resources and benchmarks to inspire future research on this crucial yet challenging and under-explored task. However, collecting data analysis annotations curated by experts can be prohibitively expensive. We propose to automatically generate high-quality answer annotations leveraging the code-generation capabilities of LLMs with a multi-turn prompting technique. We construct the DACO dataset, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k query-answer pairs that can serve as weak supervision for model training, and (3) a concentrated but high-quality test set with human refined annotations that serves as our main evaluation benchmark. We train a 6B supervised fine-tuning (SFT) model on DACO dataset, and find that the SFT model learns reasonable data analysis capabilities. To further align the models with human preference, we use reinforcement learning to encourage generating analysis perceived by human as helpful, and design a set of dense rewards to propagate the sparse human preference reward to intermediate code generation steps. Our DACO-RL algorithm is evaluated by human annotators to produce more helpful answers than SFT model in 57.72% cases, validating the effectiveness of our proposed algorithm. Data and code are released at https://github.com/shirley-wu/daco
Planning as In-Painting: A Diffusion-Based Embodied Task Planning Framework for Environments under Uncertainty
Dec 02, 2023Task planning for embodied AI has been one of the most challenging problems where the community does not meet a consensus in terms of formulation. In this paper, we aim to tackle this problem with a unified framework consisting of an end-to-end trainable method and a planning algorithm. Particularly, we propose a task-agnostic method named 'planning as in-painting'. In this method, we use a Denoising Diffusion Model (DDM) for plan generation, conditioned on both language instructions and perceptual inputs under partially observable environments. Partial observation often leads to the model hallucinating the planning. Therefore, our diffusion-based method jointly models both state trajectory and goal estimation to improve the reliability of the generated plan, given the limited available information at each step. To better leverage newly discovered information along the plan execution for a higher success rate, we propose an on-the-fly planning algorithm to collaborate with the diffusion-based planner. The proposed framework achieves promising performances in various embodied AI tasks, including vision-language navigation, object manipulation, and task planning in a photorealistic virtual environment. The code is available at: https://github.com/joeyy5588/planning-as-inpainting.
ACQUIRED: A Dataset for Answering Counterfactual Questions In Real-Life Videos
Nov 02, 2023



Multimodal counterfactual reasoning is a vital yet challenging ability for AI systems. It involves predicting the outcomes of hypothetical circumstances based on vision and language inputs, which enables AI models to learn from failures and explore hypothetical scenarios. Despite its importance, there are only a few datasets targeting the counterfactual reasoning abilities of multimodal models. Among them, they only cover reasoning over synthetic environments or specific types of events (e.g. traffic collisions), making them hard to reliably benchmark the model generalization ability in diverse real-world scenarios and reasoning dimensions. To overcome these limitations, we develop a video question answering dataset, ACQUIRED: it consists of 3.9K annotated videos, encompassing a wide range of event types and incorporating both first and third-person viewpoints, which ensures a focus on real-world diversity. In addition, each video is annotated with questions that span three distinct dimensions of reasoning, including physical, social, and temporal, which can comprehensively evaluate the model counterfactual abilities along multiple aspects. We benchmark our dataset against several state-of-the-art language-only and multimodal models and experimental results demonstrate a significant performance gap (>13%) between models and humans. The findings suggest that multimodal counterfactual reasoning remains an open challenge and ACQUIRED is a comprehensive and reliable benchmark for inspiring future research in this direction.
Localizing Active Objects from Egocentric Vision with Symbolic World Knowledge
Oct 23, 2023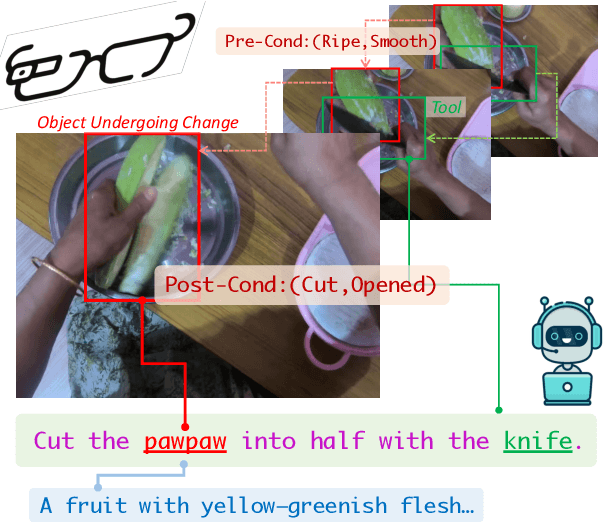
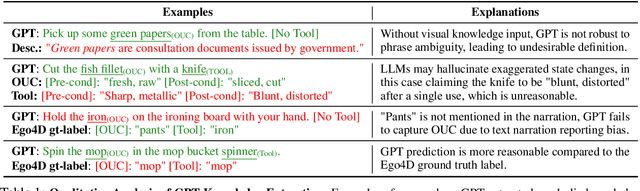

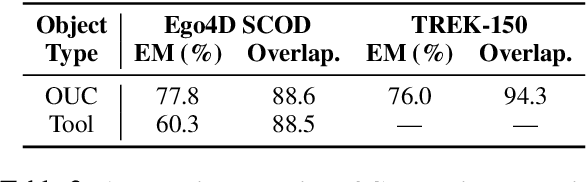
The ability to actively ground task instructions from an egocentric view is crucial for AI agents to accomplish tasks or assist humans virtually. One important step towards this goal is to localize and track key active objects that undergo major state change as a consequence of human actions/interactions to the environment without being told exactly what/where to ground (e.g., localizing and tracking the `sponge` in video from the instruction "Dip the `sponge` into the bucket."). While existing works approach this problem from a pure vision perspective, we investigate to which extent the textual modality (i.e., task instructions) and their interaction with visual modality can be beneficial. Specifically, we propose to improve phrase grounding models' ability on localizing the active objects by: (1) learning the role of `objects undergoing change` and extracting them accurately from the instructions, (2) leveraging pre- and post-conditions of the objects during actions, and (3) recognizing the objects more robustly with descriptional knowledge. We leverage large language models (LLMs) to extract the aforementioned action-object knowledge, and design a per-object aggregation masking technique to effectively perform joint inference on object phrases and symbolic knowledge. We evaluate our framework on Ego4D and Epic-Kitchens datasets. Extensive experiments demonstrate the effectiveness of our proposed framework, which leads to>54% improvements in all standard metrics on the TREK-150-OPE-Det localization + tracking task, >7% improvements in all standard metrics on the TREK-150-OPE tracking task, and >3% improvements in average precision (AP) on the Ego4D SCOD task.
InSpaceType: Reconsider Space Type in Indoor Monocular Depth Estimation
Sep 24, 2023Indoor monocular depth estimation has attracted increasing research interest. Most previous works have been focusing on methodology, primarily experimenting with NYU-Depth-V2 (NYUv2) Dataset, and only concentrated on the overall performance over the test set. However, little is known regarding robustness and generalization when it comes to applying monocular depth estimation methods to real-world scenarios where highly varying and diverse functional \textit{space types} are present such as library or kitchen. A study for performance breakdown into space types is essential to realize a pretrained model's performance variance. To facilitate our investigation for robustness and address limitations of previous works, we collect InSpaceType, a high-quality and high-resolution RGBD dataset for general indoor environments. We benchmark 11 recent methods on InSpaceType and find they severely suffer from performance imbalance concerning space types, which reveals their underlying bias. We extend our analysis to 4 other datasets, 3 mitigation approaches, and the ability to generalize to unseen space types. Our work marks the first in-depth investigation of performance imbalance across space types for indoor monocular depth estimation, drawing attention to potential safety concerns for model deployment without considering space types, and further shedding light on potential ways to improve robustness. See \url{https://depthcomputation.github.io/DepthPublic} for data.
Character-Centric Story Visualization via Visual Planning and Token Alignment
Oct 20, 2022
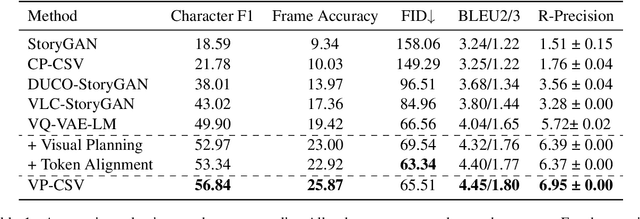
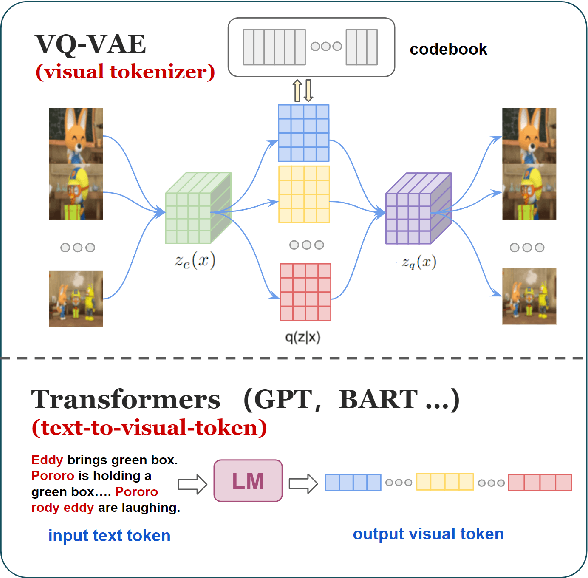
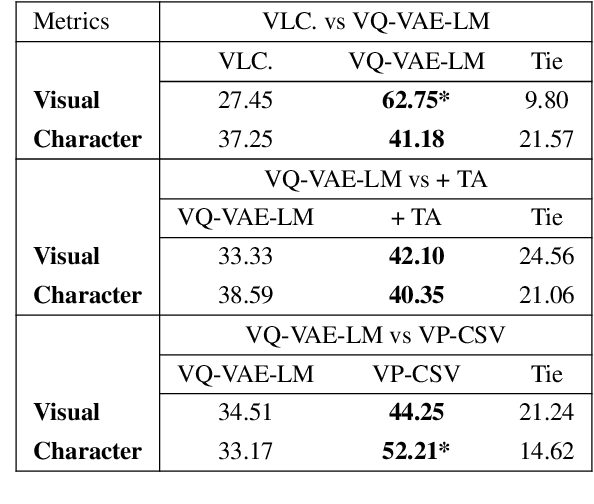
Story visualization advances the traditional text-to-image generation by enabling multiple image generation based on a complete story. This task requires machines to 1) understand long text inputs and 2) produce a globally consistent image sequence that illustrates the contents of the story. A key challenge of consistent story visualization is to preserve characters that are essential in stories. To tackle the challenge, we propose to adapt a recent work that augments Vector-Quantized Variational Autoencoders (VQ-VAE) with a text-tovisual-token (transformer) architecture. Specifically, we modify the text-to-visual-token module with a two-stage framework: 1) character token planning model that predicts the visual tokens for characters only; 2) visual token completion model that generates the remaining visual token sequence, which is sent to VQ-VAE for finalizing image generations. To encourage characters to appear in the images, we further train the two-stage framework with a character-token alignment objective. Extensive experiments and evaluations demonstrate that the proposed method excels at preserving characters and can produce higher quality image sequences compared with the strong baselines. Codes can be found in https://github.com/sairin1202/VP-CSV