 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Game Code World Model Generation into Lightweight Large Language Models
May 23, 2026Large Language Models (LLMs) have shown great ability in generating executable code from natural language, opening the possibility of automatically constructing environments for AI agents. Recent work on Code World Models (CWMs) demonstrates that LLMs can translate game rules into Python implementations compatible with solvers like Monte Carlo Tree Search. We study this problem in game settings, where generated environments must implement rules, legal actions, state transitions, observations, and rewards. We refer to these game-specific executable models as Game Code World Models (GameCWMs). However, current approaches to generating code world models rely on frontier models and inference-time refinement loops, limiting accessibility and scalability. This work investigates whether GameCWM generation capabilities can be distilled into smaller models through post-training. We introduce: (1) a curated dataset of 30 games spanning perfect and imperfect information games, (2) a verification framework that evaluates generated code against structural and semantic game properties, and (3) a post-training pipeline combining Supervised Fine-Tuning (SFT) with Reinforcement Learning with Verifiable Rewards (RLVR). We experiment with Qwen2.5-3B-Instruct and find that SFT can increase syntactic correctness, while RLVR can improve execution-level adherence to game rules, thereby improving Qwen's ability to generate valid GameCWMs in both perfect and imperfect information games. Overall, our pipeline makes Qwen2.5-3B-Instruct more capable of generating valid GameCWMs, thereby offering a scalable path toward automatic environment generation from natural language.
What Matters in Data Curation for Multimodal Reasoning? Insights from the DCVLR Challenge
Jan 16, 2026We study data curation for multimodal reasoning through the NeurIPS 2025 Data Curation for Vision-Language Reasoning (DCVLR) challenge, which isolates dataset selection by fixing the model and training protocol. Using a compact curated dataset derived primarily from Walton Multimodal Cold Start, our submission placed first in the challenge. Through post-competition ablations, we show that difficulty-based example selection on an aligned base dataset is the dominant driver of performance gains. Increasing dataset size does not reliably improve mean accuracy under the fixed training recipe, but mainly reduces run-to-run variance, while commonly used diversity and synthetic augmentation heuristics provide no additional benefit and often degrade performance. These results characterize DCVLR as a saturation-regime evaluation and highlight the central role of alignment and difficulty in data-efficient multimodal reasoning.
Planning as In-Painting: A Diffusion-Based Embodied Task Planning Framework for Environments under Uncertainty
Dec 02, 2023Task planning for embodied AI has been one of the most challenging problems where the community does not meet a consensus in terms of formulation. In this paper, we aim to tackle this problem with a unified framework consisting of an end-to-end trainable method and a planning algorithm. Particularly, we propose a task-agnostic method named 'planning as in-painting'. In this method, we use a Denoising Diffusion Model (DDM) for plan generation, conditioned on both language instructions and perceptual inputs under partially observable environments. Partial observation often leads to the model hallucinating the planning. Therefore, our diffusion-based method jointly models both state trajectory and goal estimation to improve the reliability of the generated plan, given the limited available information at each step. To better leverage newly discovered information along the plan execution for a higher success rate, we propose an on-the-fly planning algorithm to collaborate with the diffusion-based planner. The proposed framework achieves promising performances in various embodied AI tasks, including vision-language navigation, object manipulation, and task planning in a photorealistic virtual environment. The code is available at: https://github.com/joeyy5588/planning-as-inpainting.
Generalization in Generative Adversarial Networks: A Novel Perspective from Privacy Protection
Sep 25, 2019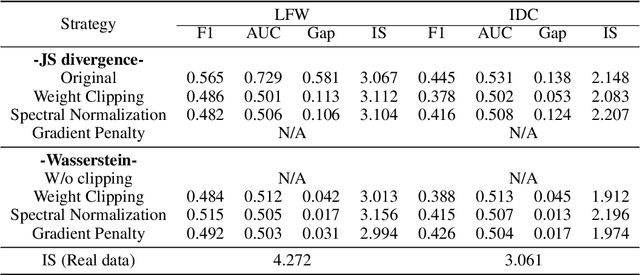
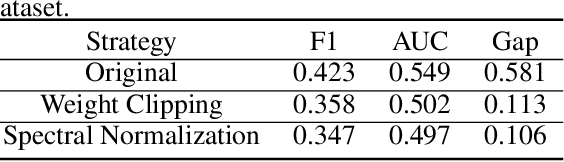
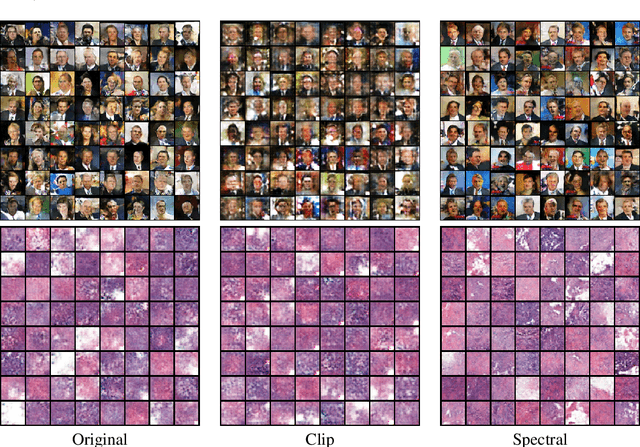
In this paper, we aim to understand the generalization properties of generative adversarial networks (GANs) from a new perspective of privacy protection. Theoretically, we prove that a differentially private learning algorithm used for training the GAN does not overfit to a certain degree, i.e., the generalization gap can be bounded. Moreover, some recent works, such as the Bayesian GAN, can be re-interpreted based on our theoretical insight from privacy protection. Quantitatively, to evaluate the information leakage of well-trained GAN models, we perform various membership attacks on these models. The results show that previous Lipschitz regularization techniques are effective in not only reducing the generalization gap but also alleviating the information leakage of the training dataset.