 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSpaceType: Dataset and Benchmark for Reconsidering Cross-Space Type Performance in Indoor Monocular Depth
Aug 25, 2024Indoor monocular depth estimation helps home automation, including robot navigation or AR/VR for surrounding perception. Most previous methods primarily experiment with the NYUv2 Dataset and concentrate on the overall performance in their evaluation. However, their robustness and generalization to diversely unseen types or categories for indoor spaces (spaces types) have yet to be discovered. Researchers may empirically find degraded performance in a released pretrained model on custom data or less-frequent types. This paper studies the common but easily overlooked factor-space type and realizes a model's performance variances across spaces. We present InSpaceType Dataset, a high-quality RGBD dataset for general indoor scenes, and benchmark 13 recent state-of-the-art methods on InSpaceType. Our examination shows that most of them suffer from performance imbalance between head and tailed types, and some top methods are even more severe. The work reveals and analyzes underlying bias in detail for transparency and robustness. We extend the analysis to a total of 4 datasets and discuss the best practice in synthetic data curation for training indoor monocular depth. Further, dataset ablation is conducted to find out the key factor in generalization. This work marks the first in-depth investigation of performance variances across space types and, more importantly, releases useful tools, including datasets and codes, to closely examine your pretrained depth models. Data and code: https://depthcomputation.github.io/DepthPublic/
InSpaceType: Reconsider Space Type in Indoor Monocular Depth Estimation
Sep 24, 2023Indoor monocular depth estimation has attracted increasing research interest. Most previous works have been focusing on methodology, primarily experimenting with NYU-Depth-V2 (NYUv2) Dataset, and only concentrated on the overall performance over the test set. However, little is known regarding robustness and generalization when it comes to applying monocular depth estimation methods to real-world scenarios where highly varying and diverse functional \textit{space types} are present such as library or kitchen. A study for performance breakdown into space types is essential to realize a pretrained model's performance variance. To facilitate our investigation for robustness and address limitations of previous works, we collect InSpaceType, a high-quality and high-resolution RGBD dataset for general indoor environments. We benchmark 11 recent methods on InSpaceType and find they severely suffer from performance imbalance concerning space types, which reveals their underlying bias. We extend our analysis to 4 other datasets, 3 mitigation approaches, and the ability to generalize to unseen space types. Our work marks the first in-depth investigation of performance imbalance across space types for indoor monocular depth estimation, drawing attention to potential safety concerns for model deployment without considering space types, and further shedding light on potential ways to improve robustness. See \url{https://depthcomputation.github.io/DepthPublic} for data.
Synthesizing Personalized Non-speech Vocalization from Discrete Speech Representations
Jun 25, 2022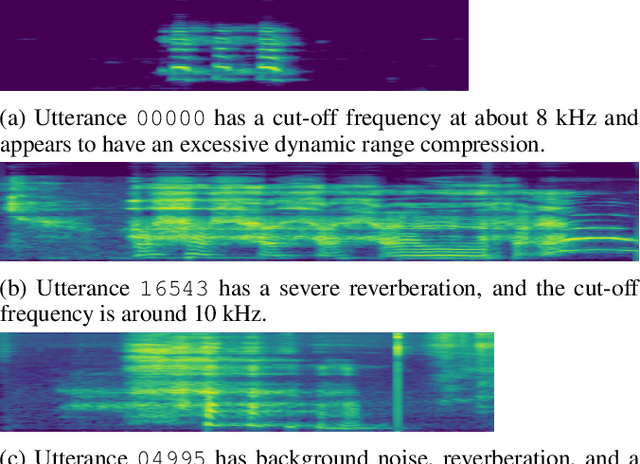
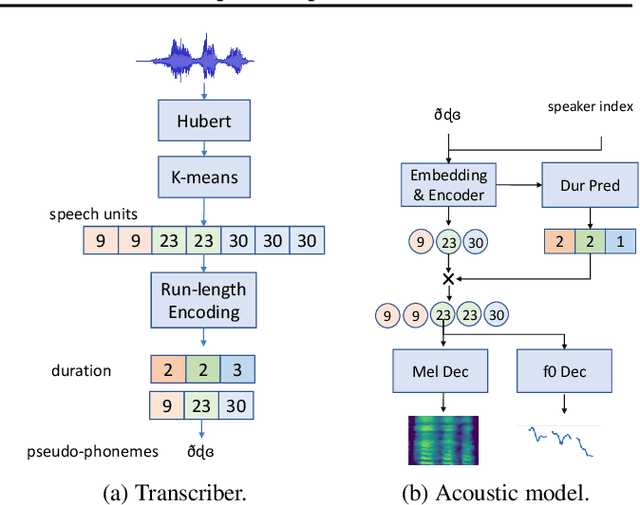
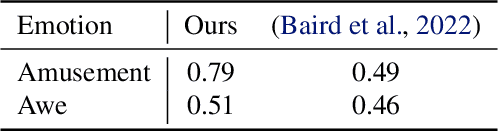
We formulated non-speech vocalization (NSV) modeling as a text-to-speech task and verified its viability. Specifically, we evaluated the phonetic expressivity of HUBERT speech units on NSVs and verified our model's ability to control over speaker timbre even though the training data is speaker few-shot. In addition, we substantiated that the heterogeneity in recording conditions is the major obstacle for NSV modeling. Finally, we discussed five improvements over our method for future research. Audio samples of synthesized NSVs are available on our demo page: https://resemble-ai.github.io/reLaugh.
Cross-Modal Perceptionist: Can Face Geometry be Gleaned from Voices?
Mar 18, 2022
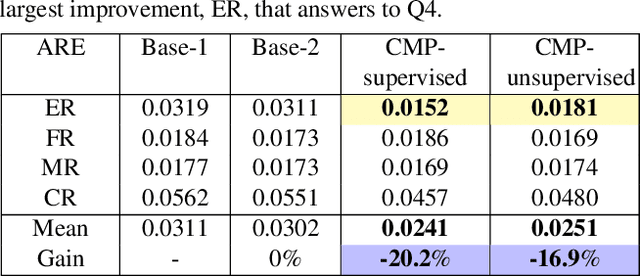

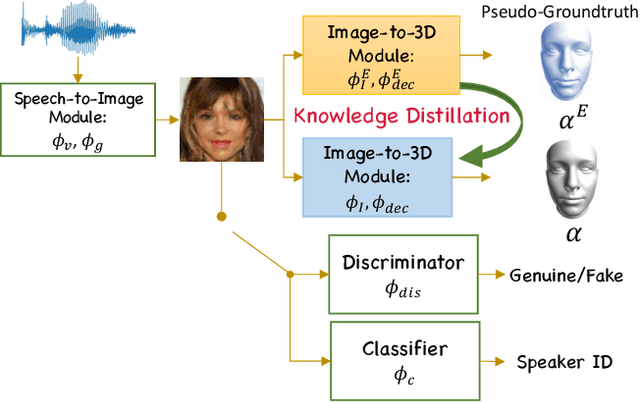
This work digs into a root question in human perception: can face geometry be gleaned from one's voices? Previous works that study this question only adopt developments in image synthesis and convert voices into face images to show correlations, but working on the image domain unavoidably involves predicting attributes that voices cannot hint, including facial textures, hairstyles, and backgrounds. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is much more physiologically grounded. We propose our analysis framework, Cross-Modal Perceptionist, under both supervised and unsupervised learning. First, we construct a dataset, Voxceleb-3D, which extends Voxceleb and includes paired voices and face meshes, making supervised learning possible. Second, we use a knowledge distillation mechanism to study whether face geometry can still be gleaned from voices without paired voices and 3D face data under limited availability of 3D face scans. We break down the core question into four parts and perform visual and numerical analyses as responses to the core question. Our findings echo those in physiology and neuroscience about the correlation between voices and facial structures. The work provides future human-centric cross-modal learning with explainable foundations. See our project page: https://choyingw.github.io/works/Voice2Mesh/index.html
Voice2Mesh: Cross-Modal 3D Face Model Generation from Voices
Apr 21, 2021

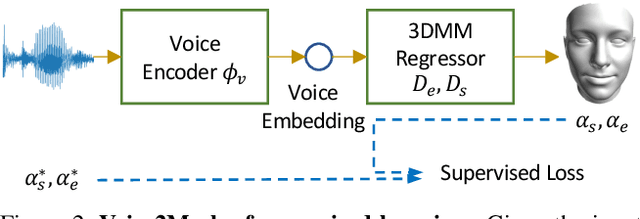

This work focuses on the analysis that whether 3D face models can be learned from only the speech inputs of speakers. Previous works for cross-modal face synthesis study image generation from voices. However, image synthesis includes variations such as hairstyles, backgrounds, and facial textures, that are arguably irrelevant to voice or without direct studies to show correlations. We instead investigate the ability to reconstruct 3D faces to concentrate on only geometry, which is more physiologically grounded. We propose both the supervised learning and unsupervised learning frameworks. Especially we demonstrate how unsupervised learning is possible in the absence of a direct voice-to-3D-face dataset under limited availability of 3D face scans when the model is equipped with knowledge distillation. To evaluate the performance, we also propose several metrics to measure the geometric fitness of two 3D faces based on points, lines, and regions. We find that 3D face shapes can be reconstructed from voices. Experimental results suggest that 3D faces can be reconstructed from voices, and our method can improve the performance over the baseline. The best performance gains (15% - 20%) on ear-to-ear distance ratio metric (ER) coincides with the intuition that one can roughly envision whether a speaker's face is overall wider or thinner only from a person's voice. See our project page for codes and data.
Adversarial Attack and Defense Strategies for Deep Speaker Recognition Systems
Aug 18, 2020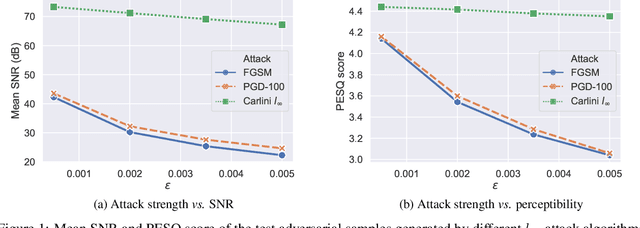
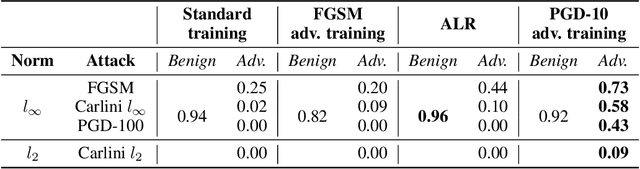
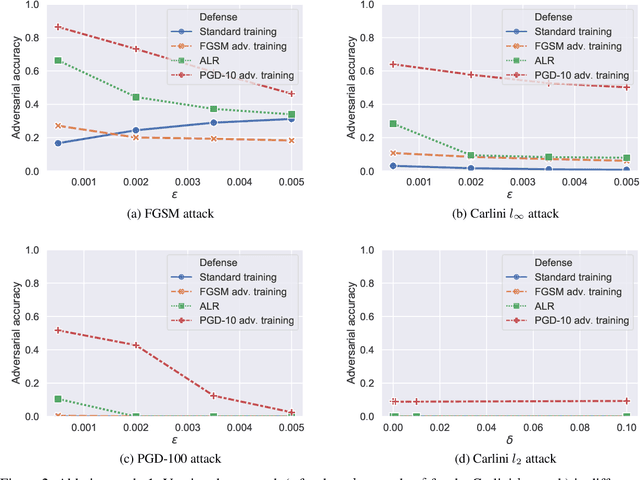

Robust speaker recognition, including in the presence of malicious attacks, is becoming increasingly important and essential, especially due to the proliferation of several smart speakers and personal agents that interact with an individual's voice commands to perform diverse, and even sensitive tasks. Adversarial attack is a recently revived domain which is shown to be effective in breaking deep neural network-based classifiers, specifically, by forcing them to change their posterior distribution by only perturbing the input samples by a very small amount. Although, significant progress in this realm has been made in the computer vision domain, advances within speaker recognition is still limited. The present expository paper considers several state-of-the-art adversarial attacks to a deep speaker recognition system, employing strong defense methods as countermeasures, and reporting on several ablation studies to obtain a comprehensive understanding of the problem. The experiments show that the speaker recognition systems are vulnerable to adversarial attacks, and the strongest attacks can reduce the accuracy of the system from 94% to even 0%. The study also compares the performances of the employed defense methods in detail, and finds adversarial training based on Projected Gradient Descent (PGD) to be the best defense method in our setting. We hope that the experiments presented in this paper provide baselines that can be useful for the research community interested in further studying adversarial robustness of speaker recognition systems.
Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
Jun 08, 2017
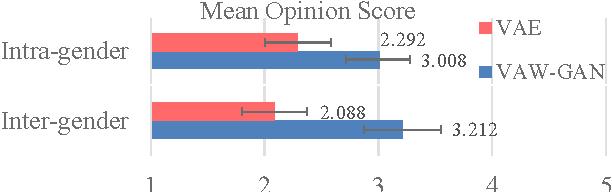

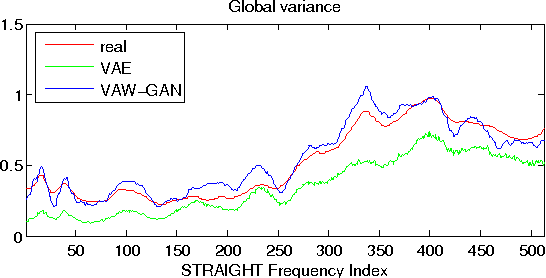
Building a voice conversion (VC) system from non-parallel speech corpora is challenging but highly valuable in real application scenarios. In most situations, the source and the target speakers do not repeat the same texts or they may even speak different languages. In this case, one possible, although indirect, solution is to build a generative model for speech. Generative models focus on explaining the observations with latent variables instead of learning a pairwise transformation function, thereby bypassing the requirement of speech frame alignment. In this paper, we propose a non-parallel VC framework with a variational autoencoding Wasserstein generative adversarial network (VAW-GAN) that explicitly considers a VC objective when building the speech model. Experimental results corroborate the capability of our framework for building a VC system from unaligned data, and demonstrate improved conversion quality.
Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder
Oct 13, 2016
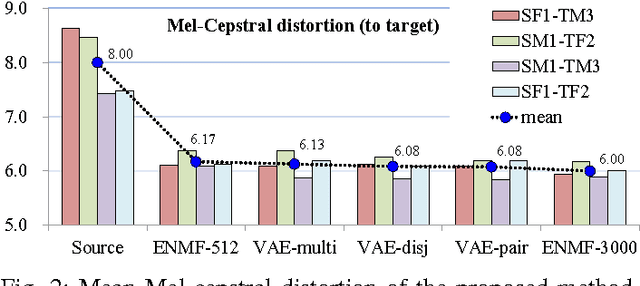

We propose a flexible framework for spectral conversion (SC) that facilitates training with unaligned corpora. Many SC frameworks require parallel corpora, phonetic alignments, or explicit frame-wise correspondence for learning conversion functions or for synthesizing a target spectrum with the aid of alignments. However, these requirements gravely limit the scope of practical applications of SC due to scarcity or even unavailability of parallel corpora. We propose an SC framework based on variational auto-encoder which enables us to exploit non-parallel corpora. The framework comprises an encoder that learns speaker-independent phonetic representations and a decoder that learns to reconstruct the designated speaker. It removes the requirement of parallel corpora or phonetic alignments to train a spectral conversion system. We report objective and subjective evaluations to validate our proposed method and compare it to SC methods that have access to aligned corpora.
Dictionary Update for NMF-based Voice Conversion Using an Encoder-Decoder Network
Oct 13, 2016
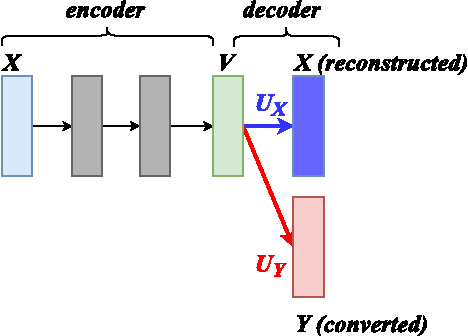
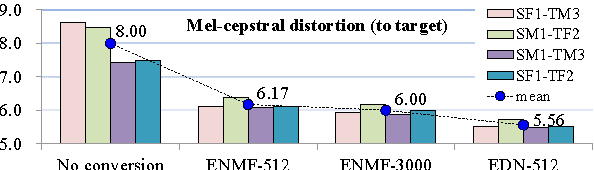
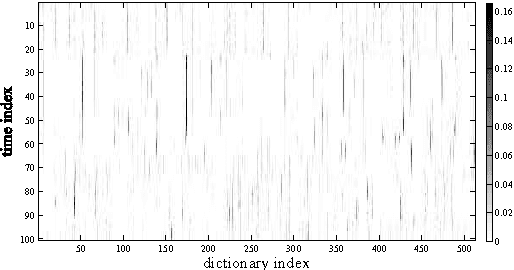
In this paper, we propose a dictionary update method for Nonnegative Matrix Factorization (NMF) with high dimensional data in a spectral conversion (SC) task. Voice conversion has been widely studied due to its potential applications such as personalized speech synthesis and speech enhancement. Exemplar-based NMF (ENMF) emerges as an effective and probably the simplest choice among all techniques for SC, as long as a source-target parallel speech corpus is given. ENMF-based SC systems usually need a large amount of bases (exemplars) to ensure the quality of the converted speech. However, a small and effective dictionary is desirable but hard to obtain via dictionary update, in particular when high-dimensional features such as STRAIGHT spectra are used. Therefore, we propose a dictionary update framework for NMF by means of an encoder-decoder reformulation. Regarding NMF as an encoder-decoder network makes it possible to exploit the whole parallel corpus more effectively and efficiently when applied to SC. Our experiments demonstrate significant gains of the proposed system with small dictionaries over conventional ENMF-based systems with dictionaries of same or much larger size.