 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech enhancement deep-learning architecture for efficient edge processing
May 27, 2024


Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
Synthetic speech detection using meta-learning with prototypical loss
Jan 24, 2022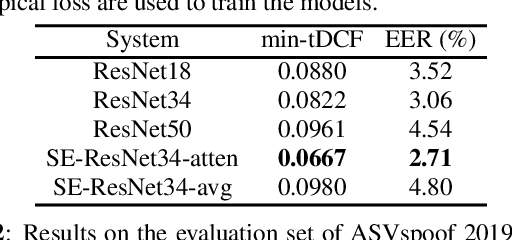
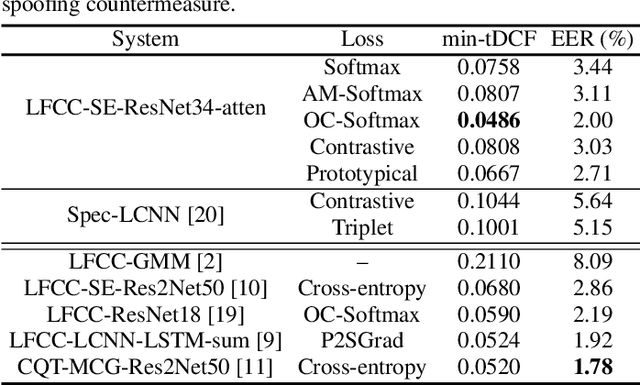
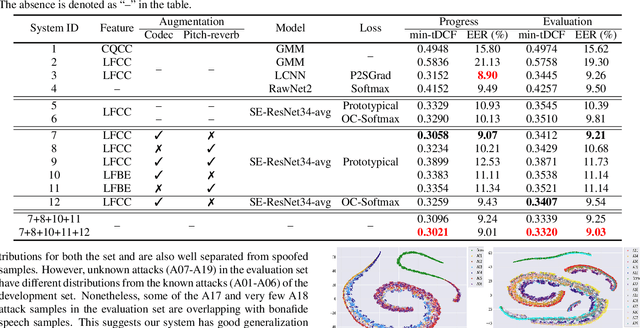
Recent works on speech spoofing countermeasures still lack generalization ability to unseen spoofing attacks. This is one of the key issues of ASVspoof challenges especially with the rapid development of diverse and high-quality spoofing algorithms. In this work, we address the generalizability of spoofing detection by proposing prototypical loss under the meta-learning paradigm to mimic the unseen test scenario during training. Prototypical loss with metric-learning objectives can learn the embedding space directly and emerges as a strong alternative to prevailing classification loss functions. We propose an anti-spoofing system based on squeeze-excitation Residual network (SE-ResNet) architecture with prototypical loss. We demonstrate that the proposed single system without any data augmentation can achieve competitive performance to the recent best anti-spoofing systems on ASVspoof 2019 logical access (LA) task. Furthermore, the proposed system with data augmentation outperforms the ASVspoof 2021 challenge best baseline both in the progress and evaluation phase of the LA task. On ASVspoof 2019 and 2021 evaluation set LA scenario, we attain a relative 68.4% and 3.6% improvement in min-tDCF compared to the challenge best baselines, respectively.
Adversarial Attack and Defense Strategies for Deep Speaker Recognition Systems
Aug 18, 2020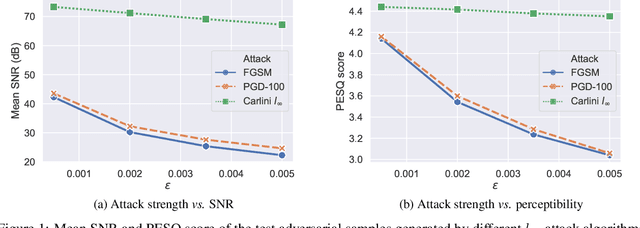
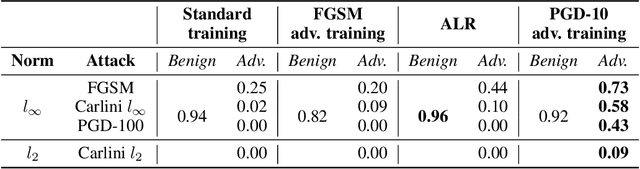
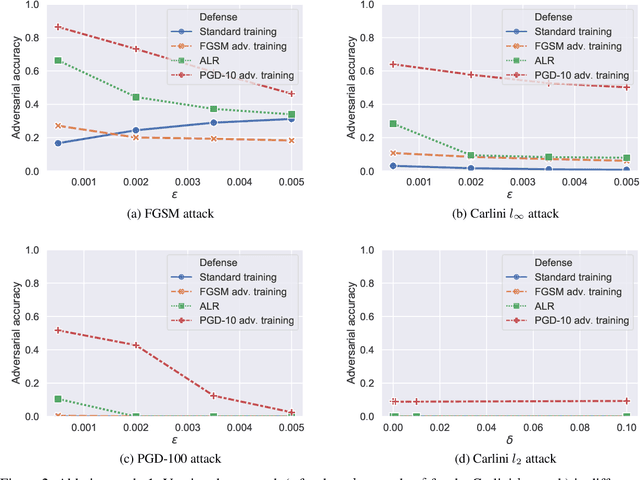

Robust speaker recognition, including in the presence of malicious attacks, is becoming increasingly important and essential, especially due to the proliferation of several smart speakers and personal agents that interact with an individual's voice commands to perform diverse, and even sensitive tasks. Adversarial attack is a recently revived domain which is shown to be effective in breaking deep neural network-based classifiers, specifically, by forcing them to change their posterior distribution by only perturbing the input samples by a very small amount. Although, significant progress in this realm has been made in the computer vision domain, advances within speaker recognition is still limited. The present expository paper considers several state-of-the-art adversarial attacks to a deep speaker recognition system, employing strong defense methods as countermeasures, and reporting on several ablation studies to obtain a comprehensive understanding of the problem. The experiments show that the speaker recognition systems are vulnerable to adversarial attacks, and the strongest attacks can reduce the accuracy of the system from 94% to even 0%. The study also compares the performances of the employed defense methods in detail, and finds adversarial training based on Projected Gradient Descent (PGD) to be the best defense method in our setting. We hope that the experiments presented in this paper provide baselines that can be useful for the research community interested in further studying adversarial robustness of speaker recognition systems.
Robustness of Voice Conversion Techniques Under Mismatched Conditions
Dec 22, 2016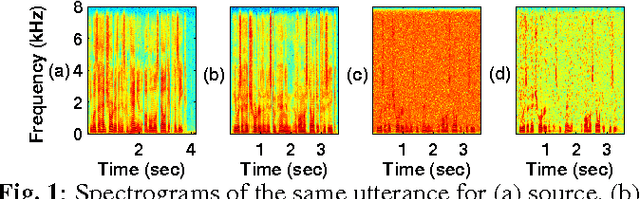


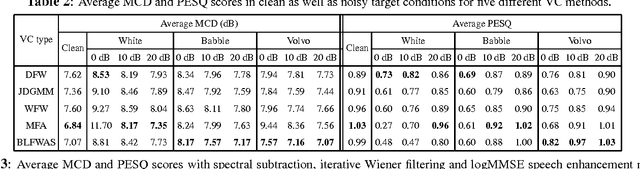
Most of the existing studies on voice conversion (VC) are conducted in acoustically matched conditions between source and target signal. However, the robustness of VC methods in presence of mismatch remains unknown. In this paper, we report a comparative analysis of different VC techniques under mismatched conditions. The extensive experiments with five different VC techniques on CMU ARCTIC corpus suggest that performance of VC methods substantially degrades in noisy conditions. We have found that bilinear frequency warping with amplitude scaling (BLFWAS) outperforms other methods in most of the noisy conditions. We further explore the suitability of different speech enhancement techniques for robust conversion. The objective evaluation results indicate that spectral subtraction and log minimum mean square error (logMMSE) based speech enhancement techniques can be used to improve the performance in specific noisy conditions.