 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Speech Intelligibility in Text-To-Speech Synthesis using Speaking Style Conversion
Aug 13, 2020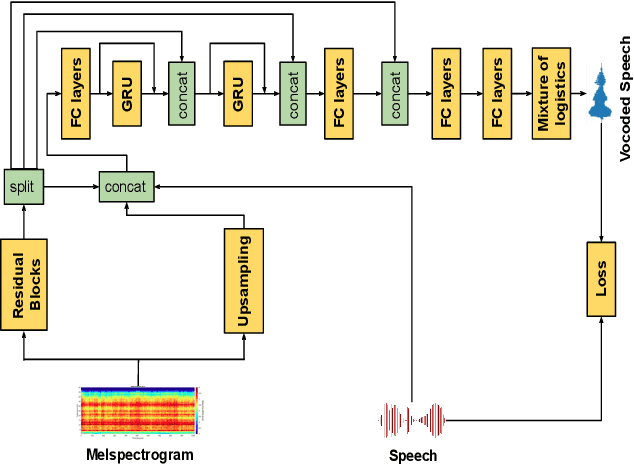
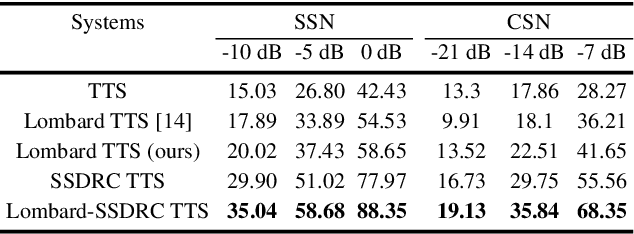
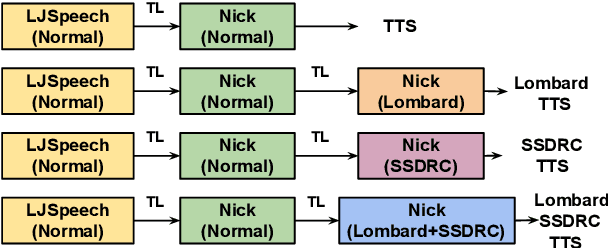
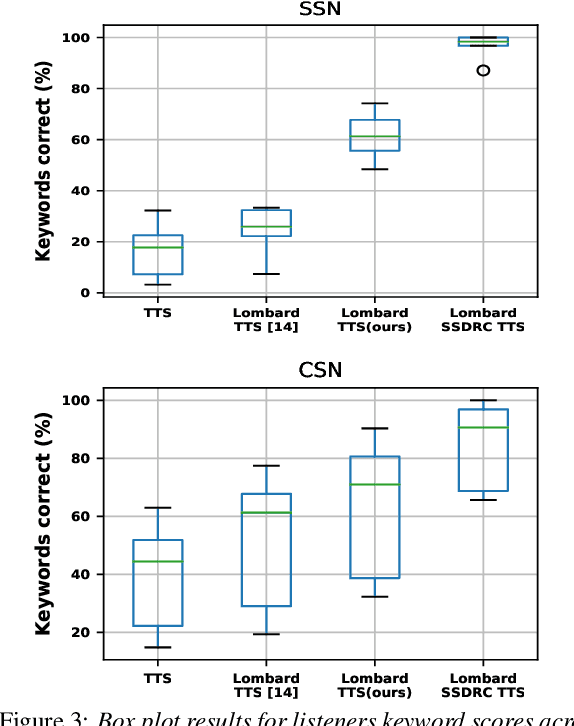
The increased adoption of digital assistants makes text-to-speech (TTS) synthesis systems an indispensable feature of modern mobile devices. It is hence desirable to build a system capable of generating highly intelligible speech in the presence of noise. Past studies have investigated style conversion in TTS synthesis, yet degraded synthesized quality often leads to worse intelligibility. To overcome such limitations, we proposed a novel transfer learning approach using Tacotron and WaveRNN based TTS synthesis. The proposed speech system exploits two modification strategies: (a) Lombard speaking style data and (b) Spectral Shaping and Dynamic Range Compression (SSDRC) which has been shown to provide high intelligibility gains by redistributing the signal energy on the time-frequency domain. We refer to this extension as Lombard-SSDRC TTS system. Intelligibility enhancement as quantified by the Intelligibility in Bits (SIIB-Gauss) measure shows that the proposed Lombard-SSDRC TTS system shows significant relative improvement between 110% and 130% in speech-shaped noise (SSN), and 47% to 140% in competing-speaker noise (CSN) against the state-of-the-art TTS approach. Additional subjective evaluation shows that Lombard-SSDRC TTS successfully increases the speech intelligibility with relative improvement of 455% for SSN and 104% for CSN in median keyword correction rate compared to the baseline TTS method.
Speaker Conditional WaveRNN: Towards Universal Neural Vocoder for Unseen Speaker and Recording Conditions
Aug 09, 2020
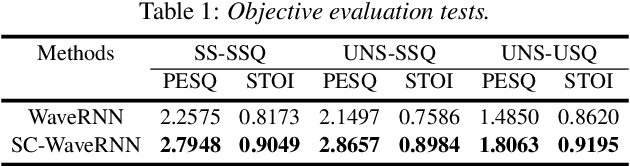
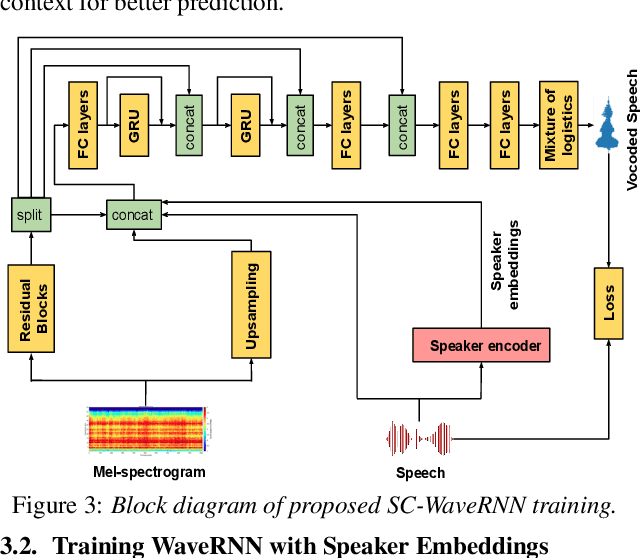
Recent advancements in deep learning led to human-level performance in single-speaker speech synthesis. However, there are still limitations in terms of speech quality when generalizing those systems into multiple-speaker models especially for unseen speakers and unseen recording qualities. For instance, conventional neural vocoders are adjusted to the training speaker and have poor generalization capabilities to unseen speakers. In this work, we propose a variant of WaveRNN, referred to as speaker conditional WaveRNN (SC-WaveRNN). We target towards the development of an efficient universal vocoder even for unseen speakers and recording conditions. In contrast to standard WaveRNN, SC-WaveRNN exploits additional information given in the form of speaker embeddings. Using publicly-available data for training, SC-WaveRNN achieves significantly better performance over baseline WaveRNN on both subjective and objective metrics. In MOS, SC-WaveRNN achieves an improvement of about 23% for seen speaker and seen recording condition and up to 95% for unseen speaker and unseen condition. Finally, we extend our work by implementing a multi-speaker text-to-speech (TTS) synthesis similar to zero-shot speaker adaptation. In terms of performance, our system has been preferred over the baseline TTS system by 60% over 15.5% and by 60.9% over 32.6%, for seen and unseen speakers, respectively.
Cumulant GAN
Jun 11, 2020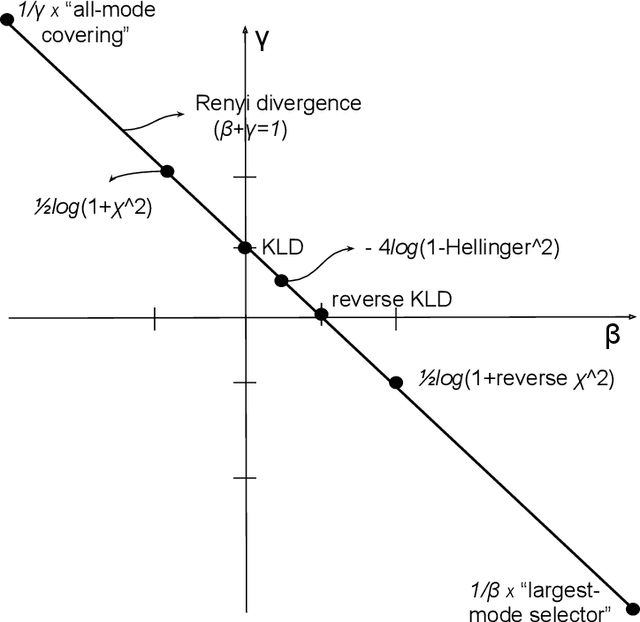
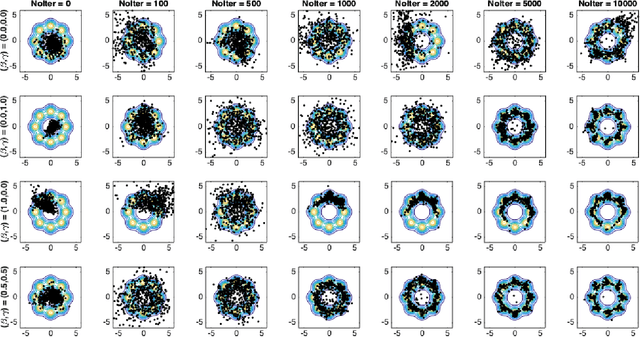
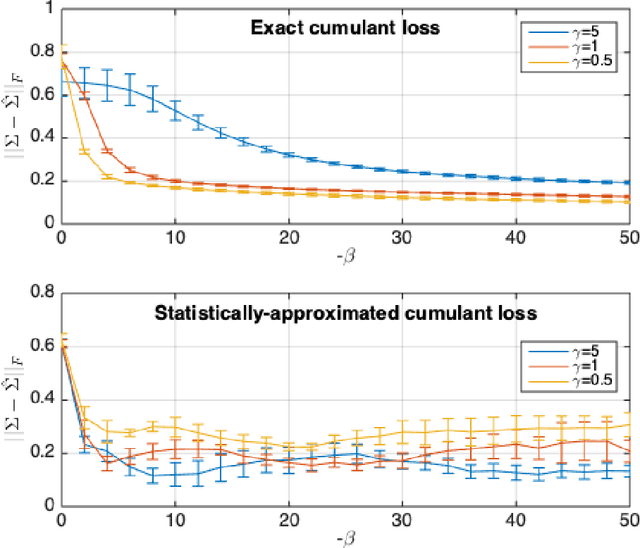
Despite the continuous improvements of Generative Adversarial Networks (GANs), stability and performance challenges still remain. In this work, we propose a novel loss function for GAN training aiming both for deeper theoretical understanding and improved performance of the underlying optimization problem. The new loss function is based on cumulant generating functions and relies on a recently-derived variational formula. We show that the corresponding optimization is equivalent to R\'enyi divergence minimization, thus offering a (partially) unified perspective of GAN losses: the R\'enyi family encompasses Kullback-Leibler divergence (KLD), reverse KLD, Hellinger distance and $\chi^2$-divergence. Wasserstein loss function is also included in the proposed cumulant GAN formulation. In terms of stability, we rigorously prove the convergence of the gradient descent algorithm for linear generator and linear discriminator for Gaussian distributions. Moreover, we numerically show that synthetic image generation trained on CIFAR-10 dataset is substantially improved in terms of inception score when weaker discriminators are considered.
Training Generative Adversarial Networks with Weights
Nov 06, 2018
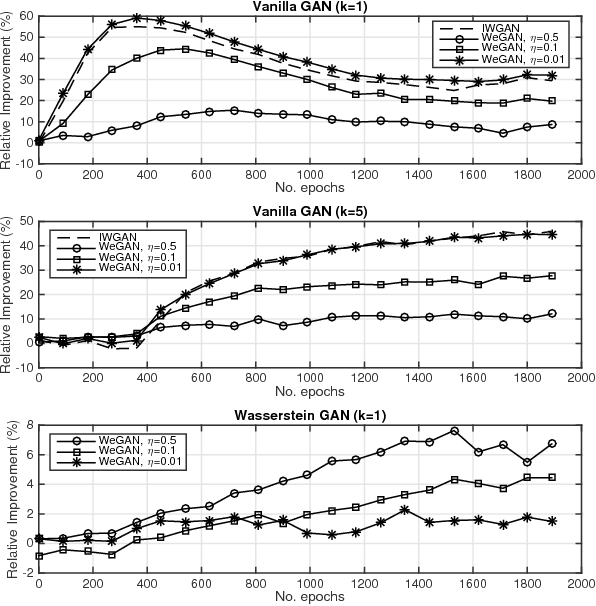
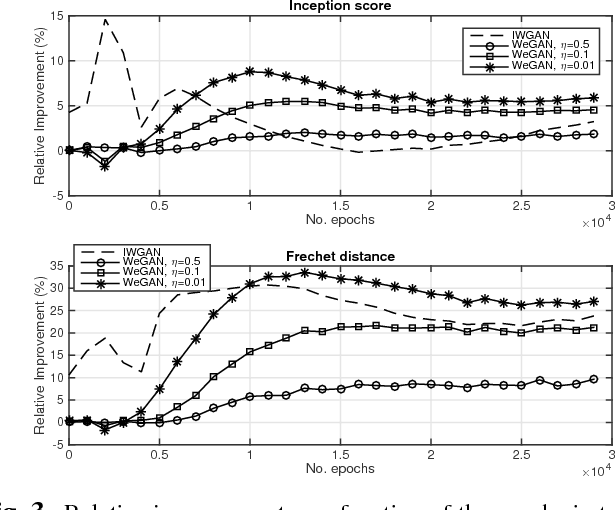
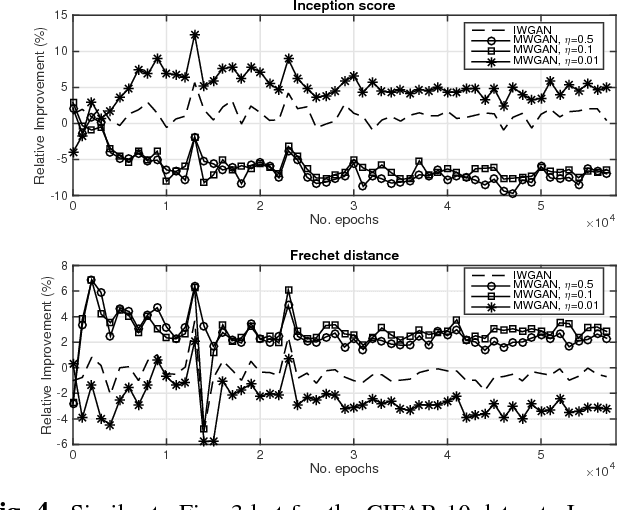
The impressive success of Generative Adversarial Networks (GANs) is often overshadowed by the difficulties in their training. Despite the continuous efforts and improvements, there are still open issues regarding their convergence properties. In this paper, we propose a simple training variation where suitable weights are defined and assist the training of the Generator. We provide theoretical arguments why the proposed algorithm is better than the baseline training in the sense of speeding up the training process and of creating a stronger Generator. Performance results showed that the new algorithm is more accurate in both synthetic and image datasets resulting in improvements ranging between 5% and 50%.
Robustness of Voice Conversion Techniques Under Mismatched Conditions
Dec 22, 2016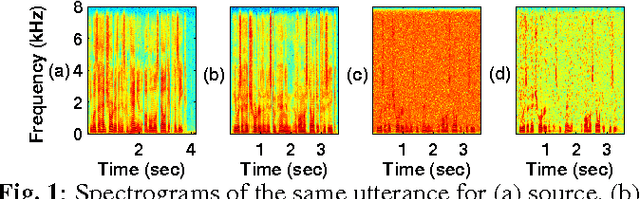


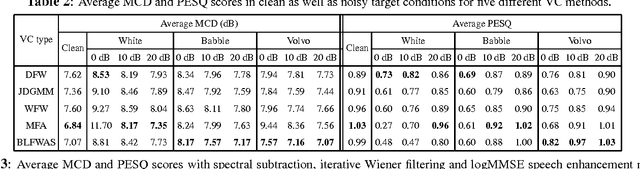
Most of the existing studies on voice conversion (VC) are conducted in acoustically matched conditions between source and target signal. However, the robustness of VC methods in presence of mismatch remains unknown. In this paper, we report a comparative analysis of different VC techniques under mismatched conditions. The extensive experiments with five different VC techniques on CMU ARCTIC corpus suggest that performance of VC methods substantially degrades in noisy conditions. We have found that bilinear frequency warping with amplitude scaling (BLFWAS) outperforms other methods in most of the noisy conditions. We further explore the suitability of different speech enhancement techniques for robust conversion. The objective evaluation results indicate that spectral subtraction and log minimum mean square error (logMMSE) based speech enhancement techniques can be used to improve the performance in specific noisy conditions.