Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Personalized Non-speech Vocalization from Discrete Speech Representations
Paper and Code
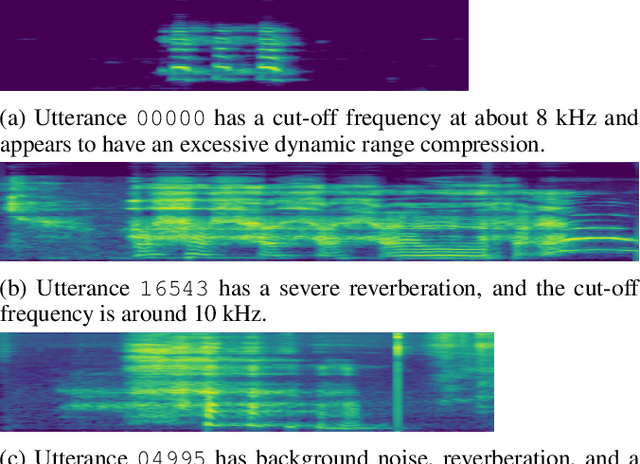
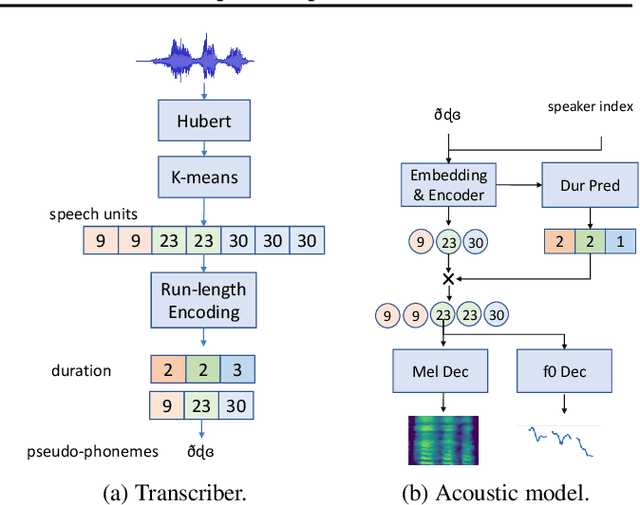
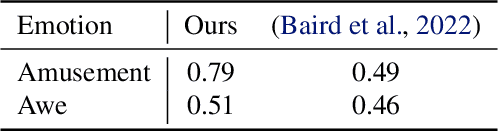
We formulated non-speech vocalization (NSV) modeling as a text-to-speech task and verified its viability. Specifically, we evaluated the phonetic expressivity of HUBERT speech units on NSVs and verified our model's ability to control over speaker timbre even though the training data is speaker few-shot. In addition, we substantiated that the heterogeneity in recording conditions is the major obstacle for NSV modeling. Finally, we discussed five improvements over our method for future research. Audio samples of synthesized NSVs are available on our demo page: https://resemble-ai.github.io/reLaugh.
View paper on