 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
Paper and Code

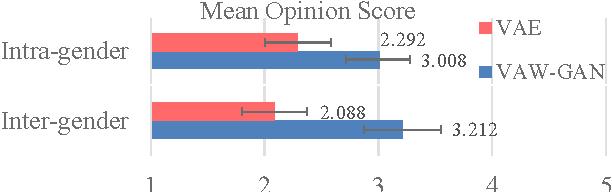

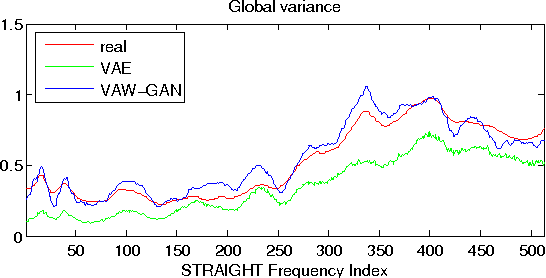
Building a voice conversion (VC) system from non-parallel speech corpora is challenging but highly valuable in real application scenarios. In most situations, the source and the target speakers do not repeat the same texts or they may even speak different languages. In this case, one possible, although indirect, solution is to build a generative model for speech. Generative models focus on explaining the observations with latent variables instead of learning a pairwise transformation function, thereby bypassing the requirement of speech frame alignment. In this paper, we propose a non-parallel VC framework with a variational autoencoding Wasserstein generative adversarial network (VAW-GAN) that explicitly considers a VC objective when building the speech model. Experimental results corroborate the capability of our framework for building a VC system from unaligned data, and demonstrate improved conversion quality.