 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Pose and Shape Estimation of Vehicles from LiDAR Data
Paper and Code
Sep 08, 2020
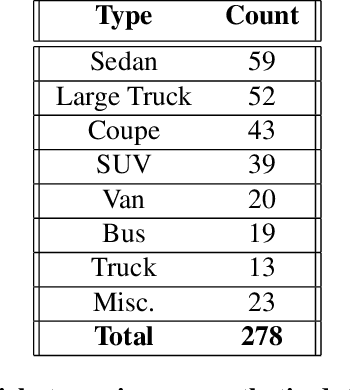

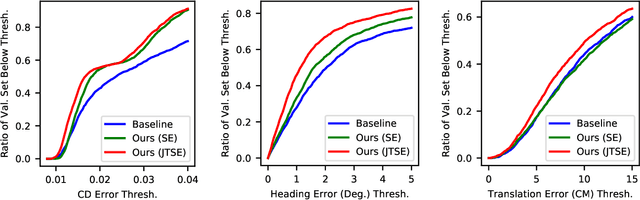
We address the problem of estimating the pose and shape of vehicles from LiDAR scans, a common problem faced by the autonomous vehicle community. Recent work has tended to address pose and shape estimation separately in isolation, despite the inherent connection between the two. We investigate a method of jointly estimating shape and pose where a single encoding is learned from which shape and pose may be decoded in an efficient yet effective manner. We additionally introduce a novel joint pose and shape loss, and show that this joint training method produces better results than independently-trained pose and shape estimators. We evaluate our method on both synthetic data and real-world data, and show superior performance against a state-of-the-art baseline.