 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adversarial Robustness of 3D Large Vision-Language Models
Jan 10, 20263D Vision-Language Models (VLMs), such as PointLLM and GPT4Point, have shown strong reasoning and generalization abilities in 3D understanding tasks. However, their adversarial robustness remains largely unexplored. Prior work in 2D VLMs has shown that the integration of visual inputs significantly increases vulnerability to adversarial attacks, making these models easier to manipulate into generating toxic or misleading outputs. In this paper, we investigate whether incorporating 3D vision similarly compromises the robustness of 3D VLMs. To this end, we present the first systematic study of adversarial robustness in point-based 3D VLMs. We propose two complementary attack strategies: \textit{Vision Attack}, which perturbs the visual token features produced by the 3D encoder and projector to assess the robustness of vision-language alignment; and \textit{Caption Attack}, which directly manipulates output token sequences to evaluate end-to-end system robustness. Each attack includes both untargeted and targeted variants to measure general vulnerability and susceptibility to controlled manipulation. Our experiments reveal that 3D VLMs exhibit significant adversarial vulnerabilities under untargeted attacks, while demonstrating greater resilience against targeted attacks aimed at forcing specific harmful outputs, compared to their 2D counterparts. These findings highlight the importance of improving the adversarial robustness of 3D VLMs, especially as they are deployed in safety-critical applications.
Towards Sustainable Universal Deepfake Detection with Frequency-Domain Masking
Dec 08, 2025
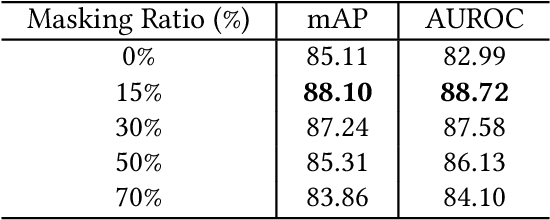
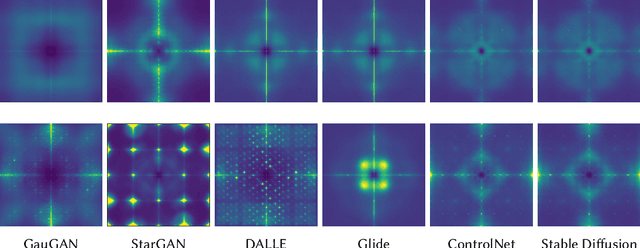
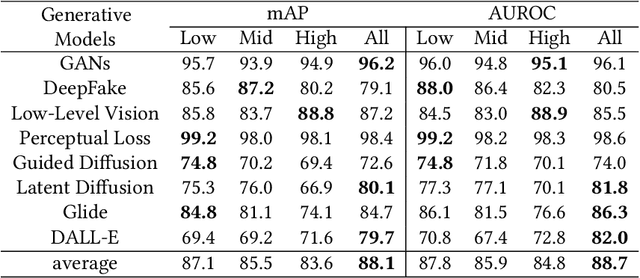
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [https://github.com/chandlerbing65nm/FakeImageDetection](https://github.com/chandlerbing65nm/FakeImageDetection).
Model Inversion Attacks on Vision-Language Models: Do They Leak What They Learn?
Aug 06, 2025Model inversion (MI) attacks pose significant privacy risks by reconstructing private training data from trained neural networks. While prior works have focused on conventional unimodal DNNs, the vulnerability of vision-language models (VLMs) remains underexplored. In this paper, we conduct the first study to understand VLMs' vulnerability in leaking private visual training data. To tailored for VLMs' token-based generative nature, we propose a suite of novel token-based and sequence-based model inversion strategies. Particularly, we propose Token-based Model Inversion (TMI), Convergent Token-based Model Inversion (TMI-C), Sequence-based Model Inversion (SMI), and Sequence-based Model Inversion with Adaptive Token Weighting (SMI-AW). Through extensive experiments and user study on three state-of-the-art VLMs and multiple datasets, we demonstrate, for the first time, that VLMs are susceptible to training data leakage. The experiments show that our proposed sequence-based methods, particularly SMI-AW combined with a logit-maximization loss based on vocabulary representation, can achieve competitive reconstruction and outperform token-based methods in attack accuracy and visual similarity. Importantly, human evaluation of the reconstructed images yields an attack accuracy of 75.31\%, underscoring the severity of model inversion threats in VLMs. Notably we also demonstrate inversion attacks on the publicly released VLMs. Our study reveals the privacy vulnerability of VLMs as they become increasingly popular across many applications such as healthcare and finance.
AIR: Zero-shot Generative Model Adaptation with Iterative Refinement
Jun 12, 2025Zero-shot generative model adaptation (ZSGM) aims to adapt a pre-trained generator to a target domain using only text guidance and without any samples from the target domain. Central to recent ZSGM approaches are directional loss which use the text guidance in the form of aligning the image offset with text offset in the embedding space of a vision-language model like CLIP. This is similar to the analogical reasoning in NLP where the offset between one pair of words is used to identify a missing element in another pair by aligning the offset between these two pairs. However, a major limitation of existing ZSGM methods is that the learning objective assumes the complete alignment between image offset and text offset in the CLIP embedding space, resulting in quality degrade in generated images. Our work makes two main contributions. Inspired by the offset misalignment studies in NLP, as our first contribution, we perform an empirical study to analyze the misalignment between text offset and image offset in CLIP embedding space for various large publicly available datasets. Our important finding is that offset misalignment in CLIP embedding space is correlated with concept distance, i.e., close concepts have a less offset misalignment. To address the limitations of the current approaches, as our second contribution, we propose Adaptation with Iterative Refinement (AIR) which is the first ZSGM approach to focus on improving target domain image quality based on our new insight on offset misalignment.Qualitative, quantitative, and user study in 26 experiment setups consistently demonstrate the proposed AIR approach achieves SOTA performance. Additional experiments are in Supp.
Uncovering the Limitations of Model Inversion Evaluation -- Benchmarks and Connection to Type-I Adversarial Attacks
May 08, 2025


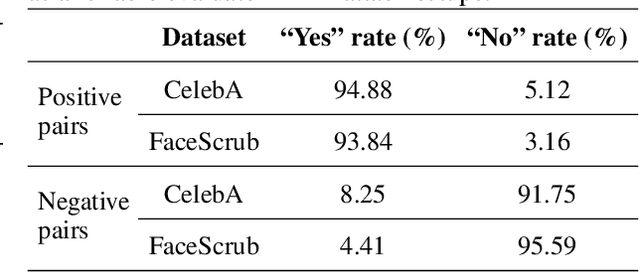
Model Inversion (MI) attacks aim to reconstruct information of private training data by exploiting access to machine learning models. The most common evaluation framework for MI attacks/defenses relies on an evaluation model that has been utilized to assess progress across almost all MI attacks and defenses proposed in recent years. In this paper, for the first time, we present an in-depth study of MI evaluation. Firstly, we construct the first comprehensive human-annotated dataset of MI attack samples, based on 28 setups of different MI attacks, defenses, private and public datasets. Secondly, using our dataset, we examine the accuracy of the MI evaluation framework and reveal that it suffers from a significant number of false positives. These findings raise questions about the previously reported success rates of SOTA MI attacks. Thirdly, we analyze the causes of these false positives, design controlled experiments, and discover the surprising effect of Type I adversarial features on MI evaluation, as well as adversarial transferability, highlighting a relationship between two previously distinct research areas. Our findings suggest that the performance of SOTA MI attacks has been overestimated, with the actual privacy leakage being significantly less than previously reported. In conclusion, we highlight critical limitations in the widely used MI evaluation framework and present our methods to mitigate false positive rates. We remark that prior research has shown that Type I adversarial attacks are very challenging, with no existing solution. Therefore, we urge to consider human evaluation as a primary MI evaluation framework rather than merely a supplement as in previous MI research. We also encourage further work on developing more robust and reliable automatic evaluation frameworks.
Text to Image Generation and Editing: A Survey
May 05, 2025Text-to-image generation (T2I) refers to the text-guided generation of high-quality images. In the past few years, T2I has attracted widespread attention and numerous works have emerged. In this survey, we comprehensively review 141 works conducted from 2021 to 2024. First, we introduce four foundation model architectures of T2I (autoregression, non-autoregression, GAN and diffusion) and the commonly used key technologies (autoencoder, attention and classifier-free guidance). Secondly, we systematically compare the methods of these studies in two directions, T2I generation and T2I editing, including the encoders and the key technologies they use. In addition, we also compare the performance of these researches side by side in terms of datasets, evaluation metrics, training resources, and inference speed. In addition to the four foundation models, we survey other works on T2I, such as energy-based models and recent Mamba and multimodality. We also investigate the potential social impact of T2I and provide some solutions. Finally, we propose unique insights of improving the performance of T2I models and possible future development directions. In summary, this survey is the first systematic and comprehensive overview of T2I, aiming to provide a valuable guide for future researchers and stimulate continued progress in this field.
Vision Transformer Neural Architecture Search for Out-of-Distribution Generalization: Benchmark and Insights
Jan 07, 2025


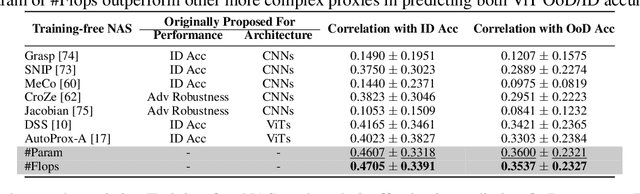
While ViTs have achieved across machine learning tasks, deploying them in real-world scenarios faces a critical challenge: generalizing under OoD shifts. A crucial research gap exists in understanding how to design ViT architectures, both manually and automatically, for better OoD generalization. To this end, we introduce OoD-ViT-NAS, the first systematic benchmark for ViTs NAS focused on OoD generalization. This benchmark includes 3000 ViT architectures of varying computational budgets evaluated on 8 common OoD datasets. Using this benchmark, we analyze factors contributing to OoD generalization. Our findings reveal key insights. First, ViT architecture designs significantly affect OoD generalization. Second, ID accuracy is often a poor indicator of OoD accuracy, highlighting the risk of optimizing ViT architectures solely for ID performance. Third, we perform the first study of NAS for ViTs OoD robustness, analyzing 9 Training-free NAS methods. We find that existing Training-free NAS methods are largely ineffective in predicting OoD accuracy despite excelling at ID accuracy. Simple proxies like Param or Flop surprisingly outperform complex Training-free NAS methods in predicting OoD accuracy. Finally, we study how ViT architectural attributes impact OoD generalization and discover that increasing embedding dimensions generally enhances performance. Our benchmark shows that ViT architectures exhibit a wide range of OoD accuracy, with up to 11.85% improvement for some OoD shifts. This underscores the importance of studying ViT architecture design for OoD. We believe OoD-ViT-NAS can catalyze further research into how ViT designs influence OoD generalization.
* Accepted in NeurIPS 2024
Multimodal Preference Data Synthetic Alignment with Reward Model
Dec 23, 2024
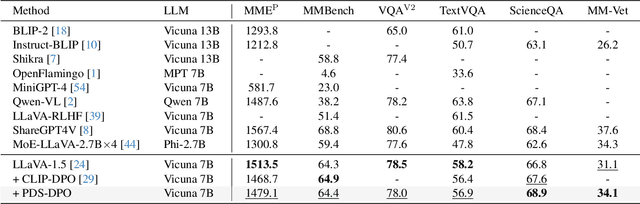
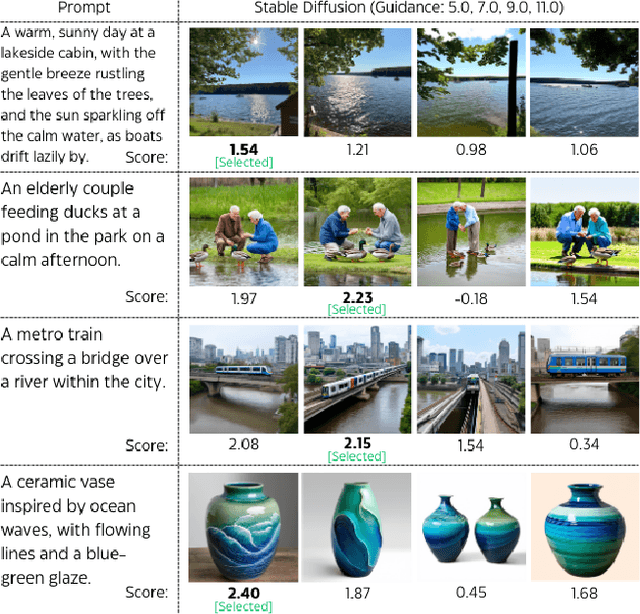

Multimodal large language models (MLLMs) have significantly advanced tasks like caption generation and visual question answering by integrating visual and textual data. However, they sometimes produce misleading or hallucinate content due to discrepancies between their pre-training data and real user prompts. Existing approaches using Direct Preference Optimization (DPO) in vision-language tasks often rely on strong models like GPT-4 or CLIP to determine positive and negative responses. Here, we propose a new framework in generating synthetic data using a reward model as a proxy of human preference for effective multimodal alignment with DPO training. The resulting DPO dataset ranges from 2K to 9K image-text pairs, was evaluated on LLaVA-v1.5-7B, where our approach demonstrated substantial improvements in both the trustworthiness and reasoning capabilities of the base model across multiple hallucination and vision-language benchmark. The experiment results indicate that integrating selected synthetic data, such as from generative and rewards models can effectively reduce reliance on human-annotated data while enhancing MLLMs' alignment capability, offering a scalable solution for safer deployment.
Urban Air Temperature Prediction using Conditional Diffusion Models
Dec 18, 2024Urbanization as a global trend has led to many environmental challenges, including the urban heat island (UHI) effect. The increase in temperature has a significant impact on the well-being of urban residents. Air temperature ($T_a$) at 2m above the surface is a key indicator of the UHI effect. How land use land cover (LULC) affects $T_a$ is a critical research question which requires high-resolution (HR) $T_a$ data at neighborhood scale. However, weather stations providing $T_a$ measurements are sparsely distributed e.g. more than 10km apart; and numerical models are impractically slow and computationally expensive. In this work, we propose a novel method to predict HR $T_a$ at 100m ground separation distance (gsd) using land surface temperature (LST) and other LULC related features which can be easily obtained from satellite imagery. Our method leverages diffusion models for the first time to generate accurate and visually realistic HR $T_a$ maps, which outperforms prior methods. We pave the way for meteorological research using computer vision techniques by providing a dataset of an extended spatial and temporal coverage, and a high spatial resolution as a benchmark for future research. Furthermore, we show that our model can be applied to urban planning by simulating the impact of different urban designs on $T_a$.
Are Anomaly Scores Telling the Whole Story? A Benchmark for Multilevel Anomaly Detection
Nov 21, 2024



Anomaly detection (AD) is a machine learning task that identifies anomalies by learning patterns from normal training data. In many real-world scenarios, anomalies vary in severity, from minor anomalies with little risk to severe abnormalities requiring immediate attention. However, existing models primarily operate in a binary setting, and the anomaly scores they produce are usually based on the deviation of data points from normal data, which may not accurately reflect practical severity. In this paper, we address this gap by making three key contributions. First, we propose a novel setting, Multilevel AD (MAD), in which the anomaly score represents the severity of anomalies in real-world applications, and we highlight its diverse applications across various domains. Second, we introduce a novel benchmark, MAD-Bench, that evaluates models not only on their ability to detect anomalies, but also on how effectively their anomaly scores reflect severity. This benchmark incorporates multiple types of baselines and real-world applications involving severity. Finally, we conduct a comprehensive performance analysis on MAD-Bench. We evaluate models on their ability to assign severity-aligned scores, investigate the correspondence between their performance on binary and multilevel detection, and study their robustness. This analysis offers key insights into improving AD models for practical severity alignment. The code framework and datasets used for the benchmark will be made publicly available.