 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR: Zero-shot Generative Model Adaptation with Iterative Refinement
Jun 12, 2025Zero-shot generative model adaptation (ZSGM) aims to adapt a pre-trained generator to a target domain using only text guidance and without any samples from the target domain. Central to recent ZSGM approaches are directional loss which use the text guidance in the form of aligning the image offset with text offset in the embedding space of a vision-language model like CLIP. This is similar to the analogical reasoning in NLP where the offset between one pair of words is used to identify a missing element in another pair by aligning the offset between these two pairs. However, a major limitation of existing ZSGM methods is that the learning objective assumes the complete alignment between image offset and text offset in the CLIP embedding space, resulting in quality degrade in generated images. Our work makes two main contributions. Inspired by the offset misalignment studies in NLP, as our first contribution, we perform an empirical study to analyze the misalignment between text offset and image offset in CLIP embedding space for various large publicly available datasets. Our important finding is that offset misalignment in CLIP embedding space is correlated with concept distance, i.e., close concepts have a less offset misalignment. To address the limitations of the current approaches, as our second contribution, we propose Adaptation with Iterative Refinement (AIR) which is the first ZSGM approach to focus on improving target domain image quality based on our new insight on offset misalignment.Qualitative, quantitative, and user study in 26 experiment setups consistently demonstrate the proposed AIR approach achieves SOTA performance. Additional experiments are in Supp.
FairQueue: Rethinking Prompt Learning for Fair Text-to-Image Generation
Oct 24, 2024Recently, prompt learning has emerged as the state-of-the-art (SOTA) for fair text-to-image (T2I) generation. Specifically, this approach leverages readily available reference images to learn inclusive prompts for each target Sensitive Attribute (tSA), allowing for fair image generation. In this work, we first reveal that this prompt learning-based approach results in degraded sample quality. Our analysis shows that the approach's training objective -- which aims to align the embedding differences of learned prompts and reference images -- could be sub-optimal, resulting in distortion of the learned prompts and degraded generated images. To further substantiate this claim, as our major contribution, we deep dive into the denoising subnetwork of the T2I model to track down the effect of these learned prompts by analyzing the cross-attention maps. In our analysis, we propose a novel prompt switching analysis: I2H and H2I. Furthermore, we propose new quantitative characterization of cross-attention maps. Our analysis reveals abnormalities in the early denoising steps, perpetuating improper global structure that results in degradation in the generated samples. Building on insights from our analysis, we propose two ideas: (i) Prompt Queuing and (ii) Attention Amplification to address the quality issue. Extensive experimental results on a wide range of tSAs show that our proposed method outperforms SOTA approach's image generation quality, while achieving competitive fairness. More resources at FairQueue Project site: https://sutd-visual-computing-group.github.io/FairQueue
On Measuring Fairness in Generative Models
Oct 30, 2023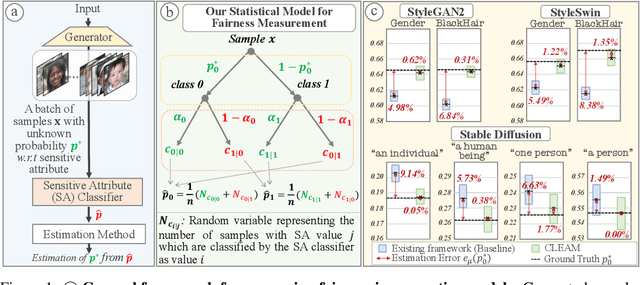



Recently, there has been increased interest in fair generative models. In this work, we conduct, for the first time, an in-depth study on fairness measurement, a critical component in gauging progress on fair generative models. We make three contributions. First, we conduct a study that reveals that the existing fairness measurement framework has considerable measurement errors, even when highly accurate sensitive attribute (SA) classifiers are used. These findings cast doubts on previously reported fairness improvements. Second, to address this issue, we propose CLassifier Error-Aware Measurement (CLEAM), a new framework which uses a statistical model to account for inaccuracies in SA classifiers. Our proposed CLEAM reduces measurement errors significantly, e.g., 4.98% $\rightarrow$ 0.62% for StyleGAN2 w.r.t. Gender. Additionally, CLEAM achieves this with minimal additional overhead. Third, we utilize CLEAM to measure fairness in important text-to-image generator and GANs, revealing considerable biases in these models that raise concerns about their applications. Code and more resources: https://sutd-visual-computing-group.github.io/CLEAM/.
Label-Only Model Inversion Attacks via Knowledge Transfer
Oct 30, 2023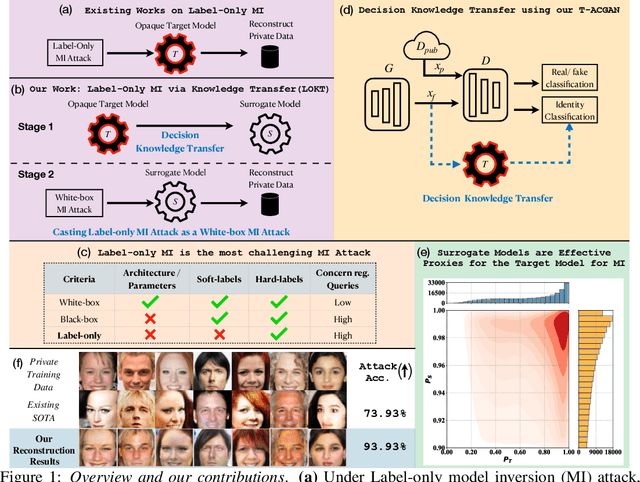
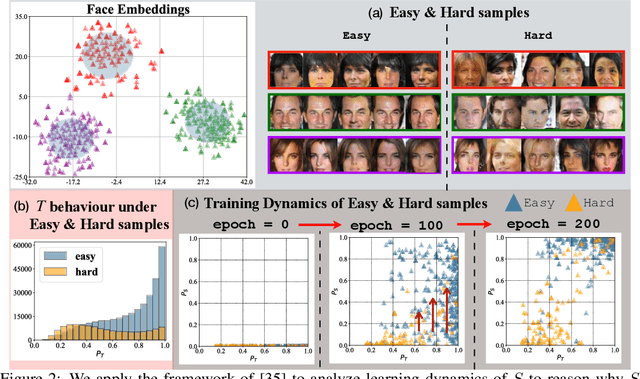
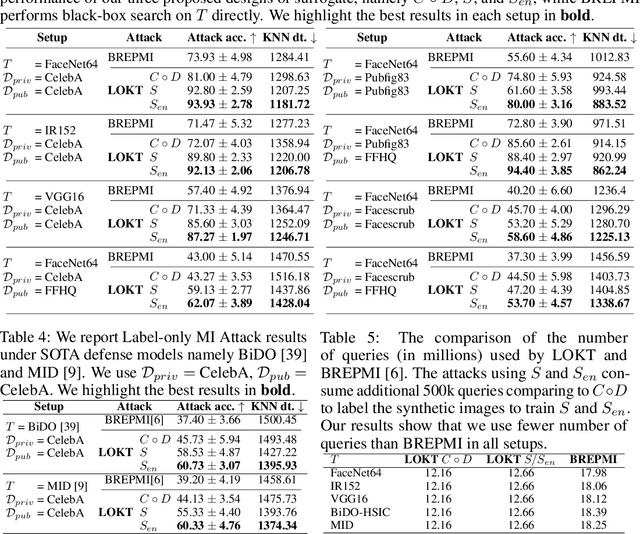

In a model inversion (MI) attack, an adversary abuses access to a machine learning (ML) model to infer and reconstruct private training data. Remarkable progress has been made in the white-box and black-box setups, where the adversary has access to the complete model or the model's soft output respectively. However, there is very limited study in the most challenging but practically important setup: Label-only MI attacks, where the adversary only has access to the model's predicted label (hard label) without confidence scores nor any other model information. In this work, we propose LOKT, a novel approach for label-only MI attacks. Our idea is based on transfer of knowledge from the opaque target model to surrogate models. Subsequently, using these surrogate models, our approach can harness advanced white-box attacks. We propose knowledge transfer based on generative modelling, and introduce a new model, Target model-assisted ACGAN (T-ACGAN), for effective knowledge transfer. Our method casts the challenging label-only MI into the more tractable white-box setup. We provide analysis to support that surrogate models based on our approach serve as effective proxies for the target model for MI. Our experiments show that our method significantly outperforms existing SOTA Label-only MI attack by more than 15% across all MI benchmarks. Furthermore, our method compares favorably in terms of query budget. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our code, demo, models and reconstructed data are available at our project page: https://ngoc-nguyen-0.github.io/lokt/
A Survey on Generative Modeling with Limited Data, Few Shots, and Zero Shot
Jul 26, 2023
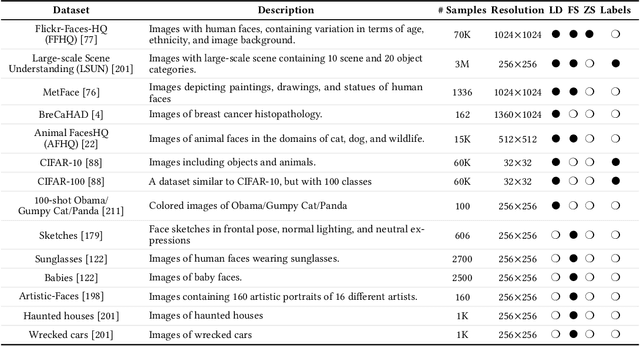

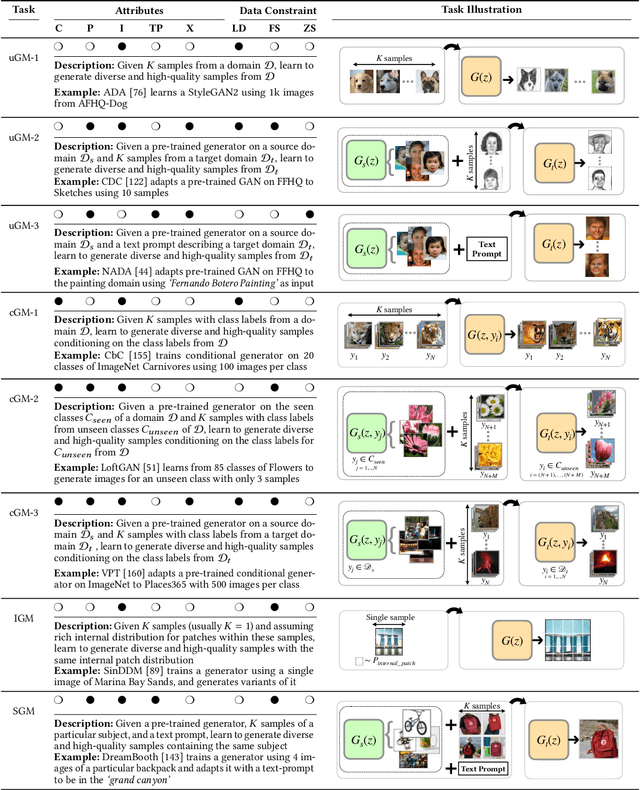
In machine learning, generative modeling aims to learn to generate new data statistically similar to the training data distribution. In this paper, we survey learning generative models under limited data, few shots and zero shot, referred to as Generative Modeling under Data Constraint (GM-DC). This is an important topic when data acquisition is challenging, e.g. healthcare applications. We discuss background, challenges, and propose two taxonomies: one on GM-DC tasks and another on GM-DC approaches. Importantly, we study interactions between different GM-DC tasks and approaches. Furthermore, we highlight research gaps, research trends, and potential avenues for future exploration. Project website: https://gmdc-survey.github.io.
Exploring Incompatible Knowledge Transfer in Few-shot Image Generation
Apr 15, 2023Few-shot image generation (FSIG) learns to generate diverse and high-fidelity images from a target domain using a few (e.g., 10) reference samples. Existing FSIG methods select, preserve and transfer prior knowledge from a source generator (pretrained on a related domain) to learn the target generator. In this work, we investigate an underexplored issue in FSIG, dubbed as incompatible knowledge transfer, which would significantly degrade the realisticness of synthetic samples. Empirical observations show that the issue stems from the least significant filters from the source generator. To this end, we propose knowledge truncation to mitigate this issue in FSIG, which is a complementary operation to knowledge preservation and is implemented by a lightweight pruning-based method. Extensive experiments show that knowledge truncation is simple and effective, consistently achieving state-of-the-art performance, including challenging setups where the source and target domains are more distant. Project Page: yunqing-me.github.io/RICK.
Re-thinking Model Inversion Attacks Against Deep Neural Networks
Apr 04, 2023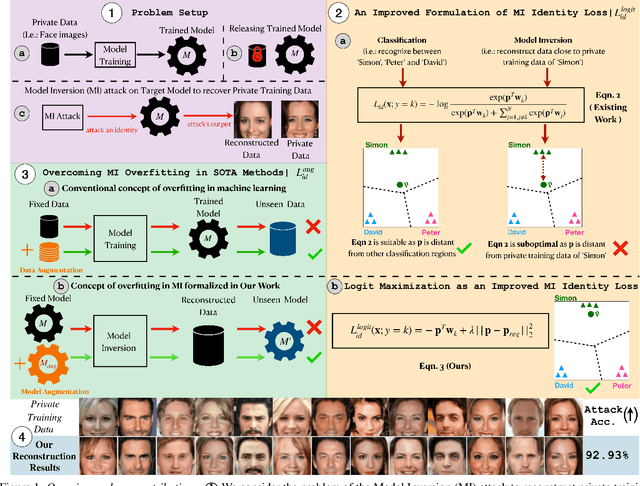

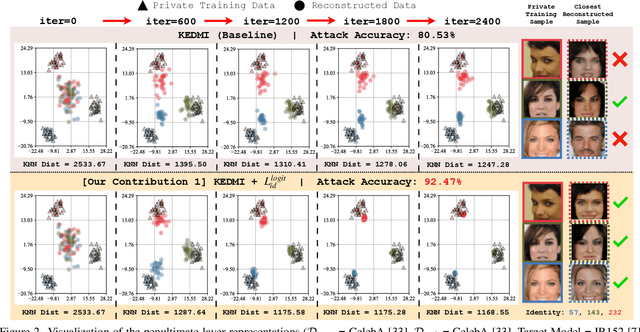
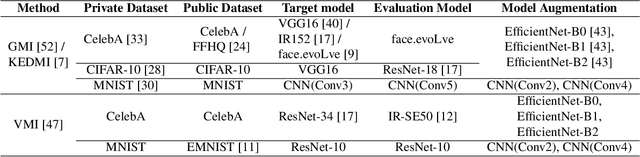
Model inversion (MI) attacks aim to infer and reconstruct private training data by abusing access to a model. MI attacks have raised concerns about the leaking of sensitive information (e.g. private face images used in training a face recognition system). Recently, several algorithms for MI have been proposed to improve the attack performance. In this work, we revisit MI, study two fundamental issues pertaining to all state-of-the-art (SOTA) MI algorithms, and propose solutions to these issues which lead to a significant boost in attack performance for all SOTA MI. In particular, our contributions are two-fold: 1) We analyze the optimization objective of SOTA MI algorithms, argue that the objective is sub-optimal for achieving MI, and propose an improved optimization objective that boosts attack performance significantly. 2) We analyze "MI overfitting", show that it would prevent reconstructed images from learning semantics of training data, and propose a novel "model augmentation" idea to overcome this issue. Our proposed solutions are simple and improve all SOTA MI attack accuracy significantly. E.g., in the standard CelebA benchmark, our solutions improve accuracy by 11.8% and achieve for the first time over 90% attack accuracy. Our findings demonstrate that there is a clear risk of leaking sensitive information from deep learning models. We urge serious consideration to be given to the privacy implications. Our code, demo, and models are available at https://ngoc-nguyen-0.github.io/re-thinking_model_inversion_attacks/
Fair Generative Models via Transfer Learning
Dec 02, 2022



This work addresses fair generative models. Dataset biases have been a major cause of unfairness in deep generative models. Previous work had proposed to augment large, biased datasets with small, unbiased reference datasets. Under this setup, a weakly-supervised approach has been proposed, which achieves state-of-the-art quality and fairness in generated samples. In our work, based on this setup, we propose a simple yet effective approach. Specifically, first, we propose fairTL, a transfer learning approach to learn fair generative models. Under fairTL, we pre-train the generative model with the available large, biased datasets and subsequently adapt the model using the small, unbiased reference dataset. We find that our fairTL can learn expressive sample generation during pre-training, thanks to the large (biased) dataset. This knowledge is then transferred to the target model during adaptation, which also learns to capture the underlying fair distribution of the small reference dataset. Second, we propose fairTL++, where we introduce two additional innovations to improve upon fairTL: (i) multiple feedback and (ii) Linear-Probing followed by Fine-Tuning (LP-FT). Taking one step further, we consider an alternative, challenging setup when only a pre-trained (potentially biased) model is available but the dataset that was used to pre-train the model is inaccessible. We demonstrate that our proposed fairTL and fairTL++ remain very effective under this setup. We note that previous work requires access to the large, biased datasets and is incapable of handling this more challenging setup. Extensive experiments show that fairTL and fairTL++ achieve state-of-the-art in both quality and fairness of generated samples. The code and additional resources can be found at bearwithchris.github.io/fairTL/.
Few-shot Image Generation via Adaptation-Aware Kernel Modulation
Nov 13, 2022Few-shot image generation (FSIG) aims to learn to generate new and diverse samples given an extremely limited number of samples from a domain, e.g., 10 training samples. Recent work has addressed the problem using transfer learning approach, leveraging a GAN pretrained on a large-scale source domain dataset and adapting that model to the target domain based on very limited target domain samples. Central to recent FSIG methods are knowledge preserving criteria, which aim to select a subset of source model's knowledge to be preserved into the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/source task, and they fail to consider target domain/adaptation task in selecting source model's knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. As our first contribution, we re-visit recent FSIG works and their experiments. Our important finding is that, under setups which assumption of close proximity between source and target domains is relaxed, existing state-of-the-art (SOTA) methods which consider only source domain/source task in knowledge preserving perform no better than a baseline fine-tuning method. To address the limitation of existing methods, as our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) to address general FSIG of different source-target domain proximity. Extensive experimental results show that the proposed method consistently achieves SOTA performance across source/target domains of different proximity, including challenging setups when source and target domains are more apart. Project Page: https://yunqing-me.github.io/AdAM/
Revisit Multimodal Meta-Learning through the Lens of Multi-Task Learning
Oct 27, 2021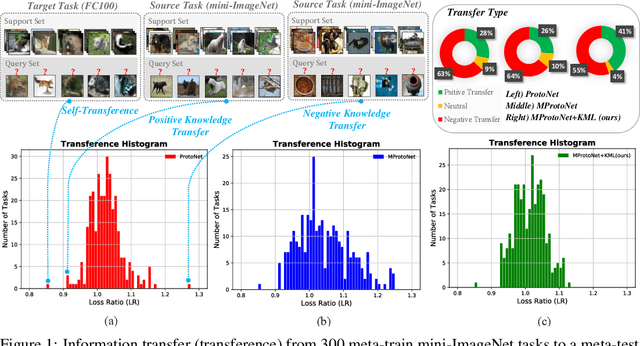
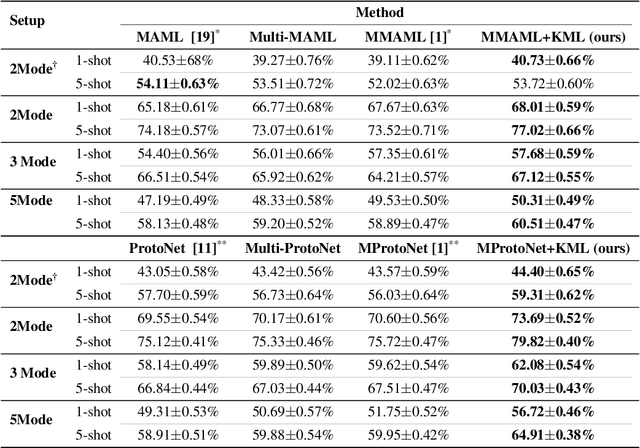
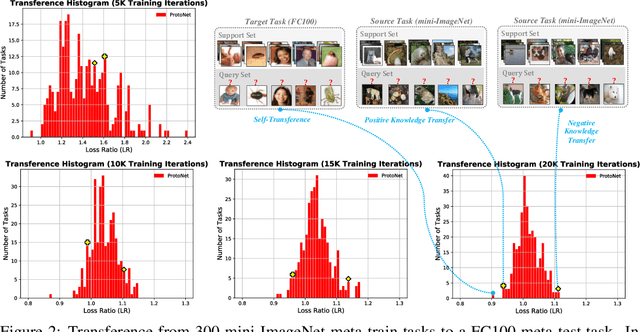
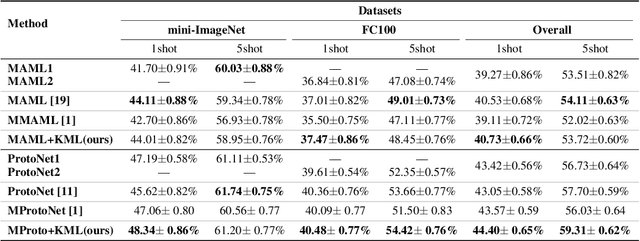
Multimodal meta-learning is a recent problem that extends conventional few-shot meta-learning by generalizing its setup to diverse multimodal task distributions. This setup makes a step towards mimicking how humans make use of a diverse set of prior skills to learn new skills. Previous work has achieved encouraging performance. In particular, in spite of the diversity of the multimodal tasks, previous work claims that a single meta-learner trained on a multimodal distribution can sometimes outperform multiple specialized meta-learners trained on individual unimodal distributions. The improvement is attributed to knowledge transfer between different modes of task distributions. However, there is no deep investigation to verify and understand the knowledge transfer between multimodal tasks. Our work makes two contributions to multimodal meta-learning. First, we propose a method to quantify knowledge transfer between tasks of different modes at a micro-level. Our quantitative, task-level analysis is inspired by the recent transference idea from multi-task learning. Second, inspired by hard parameter sharing in multi-task learning and a new interpretation of related work, we propose a new multimodal meta-learner that outperforms existing work by considerable margins. While the major focus is on multimodal meta-learning, our work also attempts to shed light on task interaction in conventional meta-learning. The code for this project is available at https://miladabd.github.io/KML.