 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairQueue: Rethinking Prompt Learning for Fair Text-to-Image Generation
Oct 24, 2024Recently, prompt learning has emerged as the state-of-the-art (SOTA) for fair text-to-image (T2I) generation. Specifically, this approach leverages readily available reference images to learn inclusive prompts for each target Sensitive Attribute (tSA), allowing for fair image generation. In this work, we first reveal that this prompt learning-based approach results in degraded sample quality. Our analysis shows that the approach's training objective -- which aims to align the embedding differences of learned prompts and reference images -- could be sub-optimal, resulting in distortion of the learned prompts and degraded generated images. To further substantiate this claim, as our major contribution, we deep dive into the denoising subnetwork of the T2I model to track down the effect of these learned prompts by analyzing the cross-attention maps. In our analysis, we propose a novel prompt switching analysis: I2H and H2I. Furthermore, we propose new quantitative characterization of cross-attention maps. Our analysis reveals abnormalities in the early denoising steps, perpetuating improper global structure that results in degradation in the generated samples. Building on insights from our analysis, we propose two ideas: (i) Prompt Queuing and (ii) Attention Amplification to address the quality issue. Extensive experimental results on a wide range of tSAs show that our proposed method outperforms SOTA approach's image generation quality, while achieving competitive fairness. More resources at FairQueue Project site: https://sutd-visual-computing-group.github.io/FairQueue
On the Vulnerability of Skip Connections to Model Inversion Attacks
Sep 03, 2024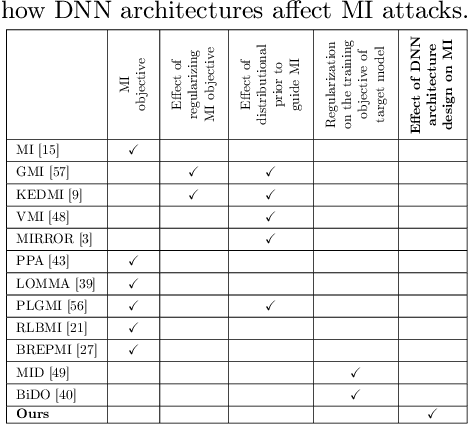
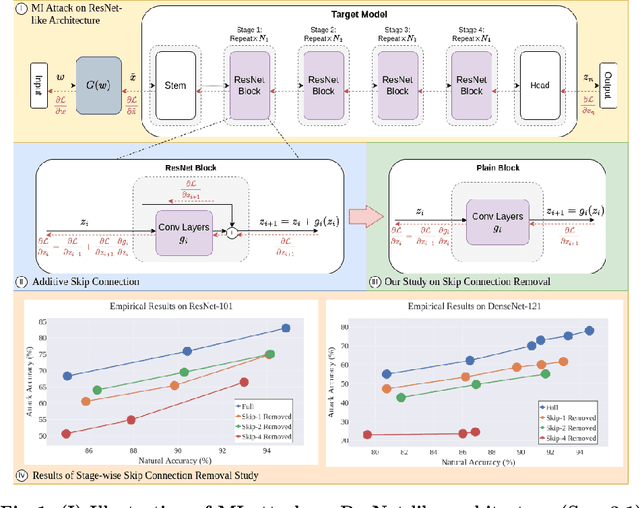
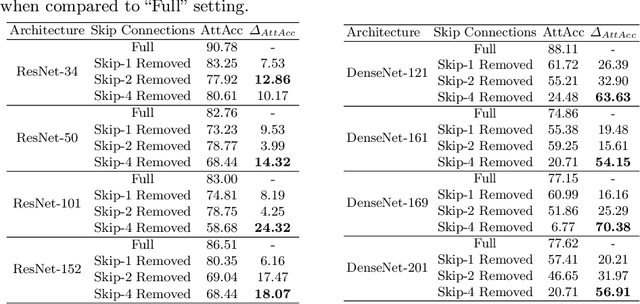
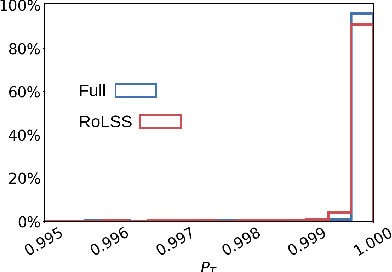
Skip connections are fundamental architecture designs for modern deep neural networks (DNNs) such as CNNs and ViTs. While they help improve model performance significantly, we identify a vulnerability associated with skip connections to Model Inversion (MI) attacks, a type of privacy attack that aims to reconstruct private training data through abusive exploitation of a model. In this paper, as a pioneer work to understand how DNN architectures affect MI, we study the impact of skip connections on MI. We make the following discoveries: 1) Skip connections reinforce MI attacks and compromise data privacy. 2) Skip connections in the last stage are the most critical to attack. 3) RepVGG, an approach to remove skip connections in the inference-time architectures, could not mitigate the vulnerability to MI attacks. 4) Based on our findings, we propose MI-resilient architecture designs for the first time. Without bells and whistles, we show in extensive experiments that our MI-resilient architectures can outperform state-of-the-art (SOTA) defense methods in MI robustness. Furthermore, our MI-resilient architectures are complementary to existing MI defense methods. Our project is available at https://Pillowkoh.github.io/projects/RoLSS/
Defending against Model Inversion Attacks via Random Erasing
Sep 02, 2024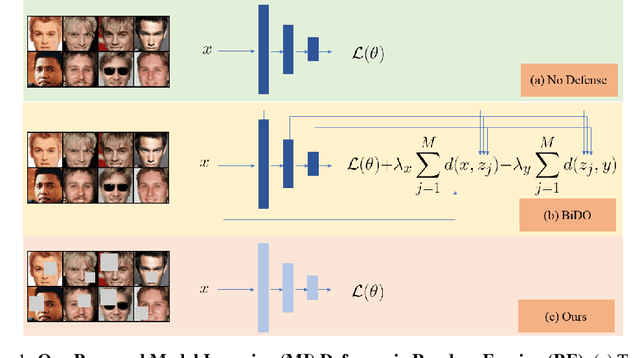

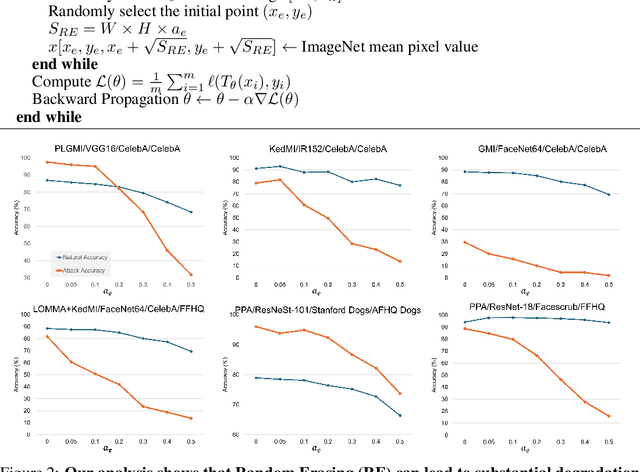

Model Inversion (MI) is a type of privacy violation that focuses on reconstructing private training data through abusive exploitation of machine learning models. To defend against MI attacks, state-of-the-art (SOTA) MI defense methods rely on regularizations that conflict with the training loss, creating explicit tension between privacy protection and model utility. In this paper, we present a new method to defend against MI attacks. Our method takes a new perspective and focuses on training data. Our idea is based on a novel insight on Random Erasing (RE), which has been applied in the past as a data augmentation technique to improve the model accuracy under occlusion. In our work, we instead focus on applying RE for degrading MI attack accuracy. Our key insight is that MI attacks require significant amount of private training data information encoded inside the model in order to reconstruct high-dimensional private images. Therefore, we propose to apply RE to reduce private information presented to the model during training. We show that this can lead to substantial degradation in MI reconstruction quality and attack accuracy. Meanwhile, natural accuracy of the model is only moderately affected. Our method is very simple to implement and complementary to existing defense methods. Our extensive experiments of 23 setups demonstrate that our method can achieve SOTA performance in balancing privacy and utility of the models. The results consistently demonstrate the superiority of our method over existing defenses across different MI attacks, network architectures, and attack configurations.
Towards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021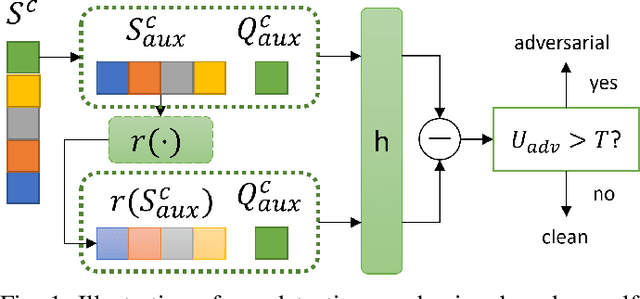
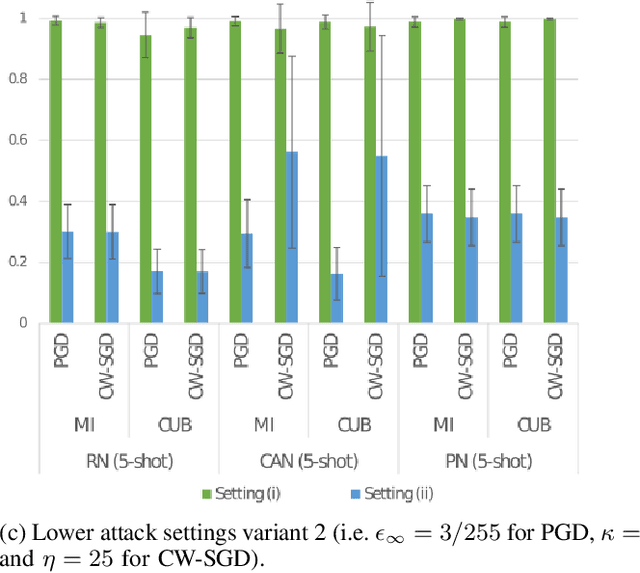
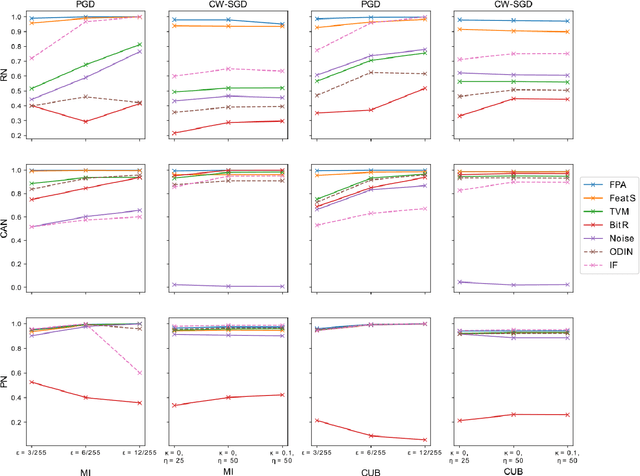
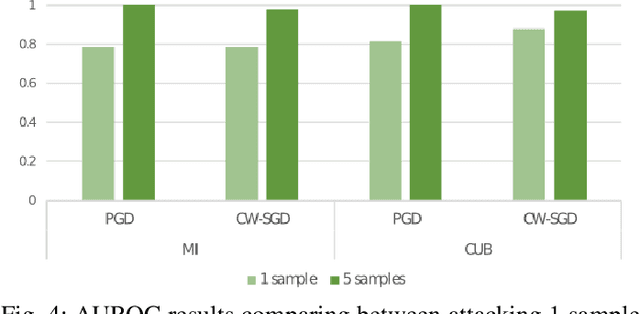
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.