 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
Defending against Model Inversion Attacks via Random Erasing
Sep 02, 2024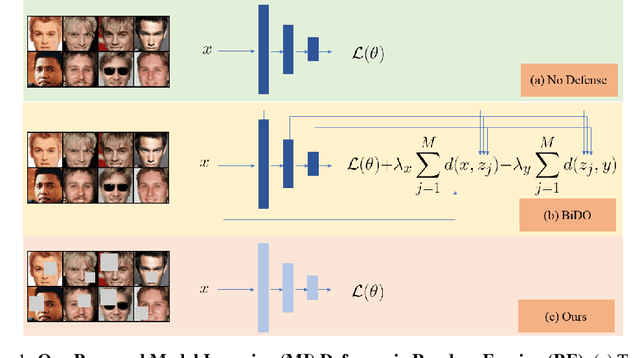


Model Inversion (MI) is a type of privacy violation that focuses on reconstructing private training data through abusive exploitation of machine learning models. To defend against MI attacks, state-of-the-art (SOTA) MI defense methods rely on regularizations that conflict with the training loss, creating explicit tension between privacy protection and model utility. In this paper, we present a new method to defend against MI attacks. Our method takes a new perspective and focuses on training data. Our idea is based on a novel insight on Random Erasing (RE), which has been applied in the past as a data augmentation technique to improve the model accuracy under occlusion. In our work, we instead focus on applying RE for degrading MI attack accuracy. Our key insight is that MI attacks require significant amount of private training data information encoded inside the model in order to reconstruct high-dimensional private images. Therefore, we propose to apply RE to reduce private information presented to the model during training. We show that this can lead to substantial degradation in MI reconstruction quality and attack accuracy. Meanwhile, natural accuracy of the model is only moderately affected. Our method is very simple to implement and complementary to existing defense methods. Our extensive experiments of 23 setups demonstrate that our method can achieve SOTA performance in balancing privacy and utility of the models. The results consistently demonstrate the superiority of our method over existing defenses across different MI attacks, network architectures, and attack configurations.
HiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models in Resource-Constrained Environments
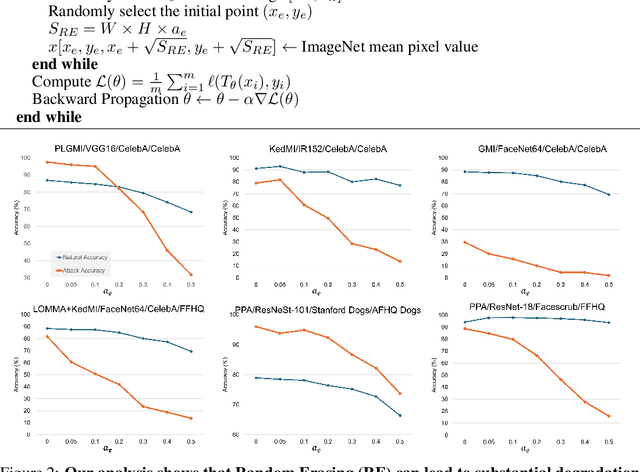
Aug 20, 2024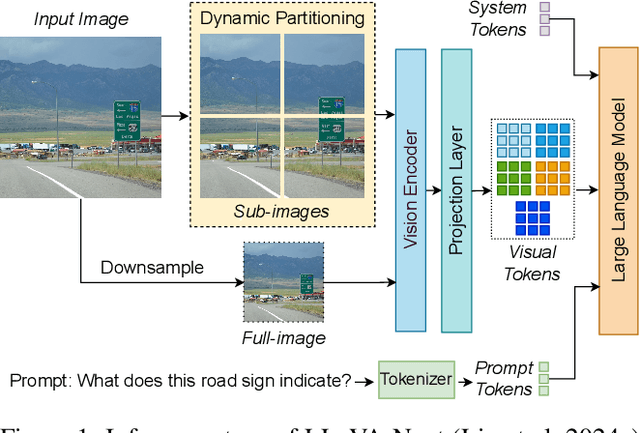

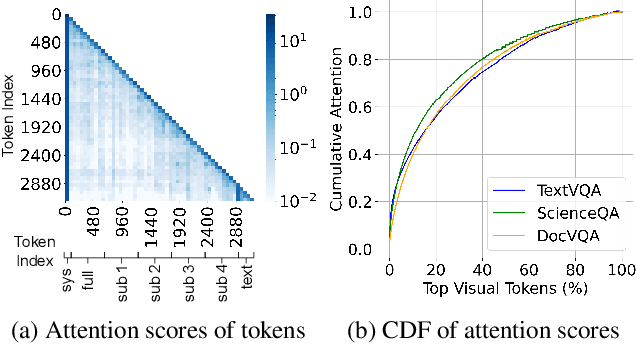

High-resolution Vision-Language Models (VLMs) have been widely used in multimodal tasks to enhance accuracy by preserving detailed image information. However, these models often generate excessive visual tokens due to encoding multiple partitions of the input image. Processing these excessive visual tokens is computationally challenging, especially in resource-constrained environments with commodity GPUs. To support high-resolution images while meeting resource constraints, we propose High-Resolution Early Dropping (HiRED), a token-dropping scheme that operates within a fixed token budget before the Large Language Model (LLM) stage. HiRED can be integrated with existing high-resolution VLMs in a plug-and-play manner, as it requires no additional training while still maintaining superior accuracy. We strategically use the vision encoder's attention in the initial layers to assess the visual content of each image partition and allocate the token budget accordingly. Then, using the attention in the final layer, we select the most important visual tokens from each partition within the allocated budget, dropping the rest. Empirically, when applied to LLaVA-Next-7B on NVIDIA TESLA P40 GPU, HiRED with a 20% token budget increases token generation throughput by 4.7, reduces first-token generation latency by 15 seconds, and saves 2.3 GB of GPU memory for a single inference.
ROMA: Run-Time Object Detection To Maximize Real-Time Accuracy
Oct 28, 2022This paper analyzes the effects of dynamically varying video contents and detection latency on the real-time detection accuracy of a detector and proposes a new run-time accuracy variation model, ROMA, based on the findings from the analysis. ROMA is designed to select an optimal detector out of a set of detectors in real time without label information to maximize real-time object detection accuracy. ROMA utilizing four YOLOv4 detectors on an NVIDIA Jetson Nano shows real-time accuracy improvements by 4 to 37% for a scenario of dynamically varying video contents and detection latency consisting of MOT17Det and MOT20Det datasets, compared to individual YOLOv4 detectors and two state-of-the-art runtime techniques.
Resource-Efficient Deep Learning: A Survey on Model-, Arithmetic-, and Implementation-Level Techniques
Dec 30, 2021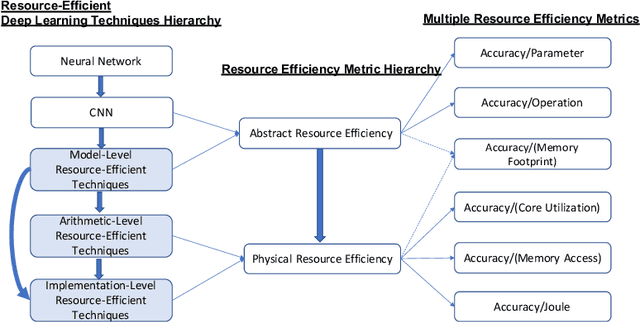
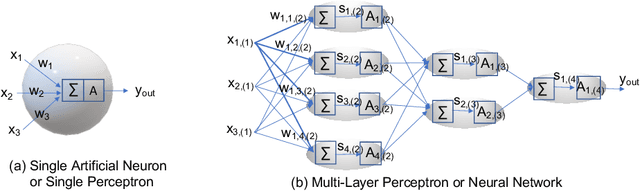
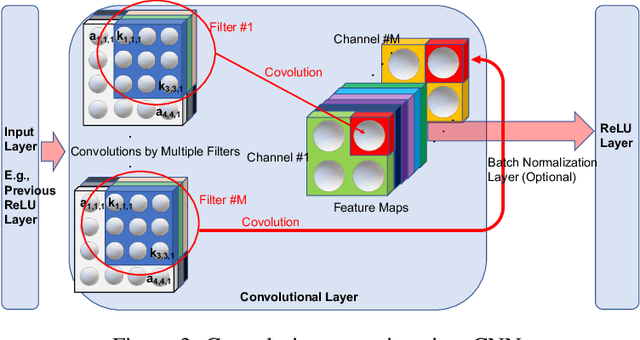
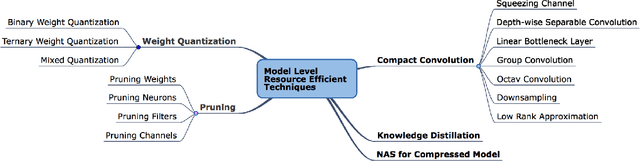
Deep learning is pervasive in our daily life, including self-driving cars, virtual assistants, social network services, healthcare services, face recognition, etc. However, deep neural networks demand substantial compute resources during training and inference. The machine learning community has mainly focused on model-level optimizations such as architectural compression of deep learning models, while the system community has focused on implementation-level optimization. In between, various arithmetic-level optimization techniques have been proposed in the arithmetic community. This article provides a survey on resource-efficient deep learning techniques in terms of model-, arithmetic-, and implementation-level techniques and identifies the research gaps for resource-efficient deep learning techniques across the three different level techniques. Our survey clarifies the influence from higher to lower-level techniques based on our resource-efficiency metric definition and discusses the future trend for resource-efficient deep learning research.
Leveraging Transprecision Computing for Machine Vision Applications at the Edge
Aug 29, 2021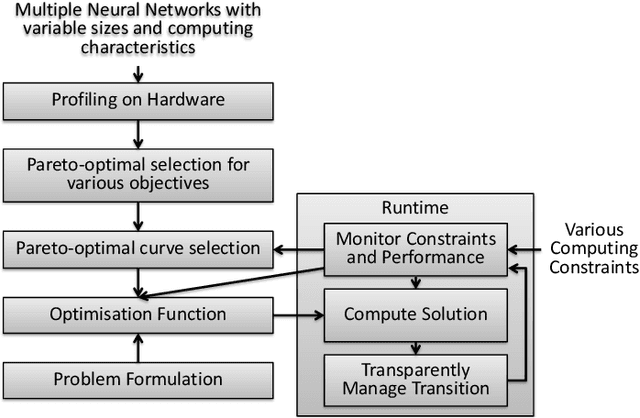
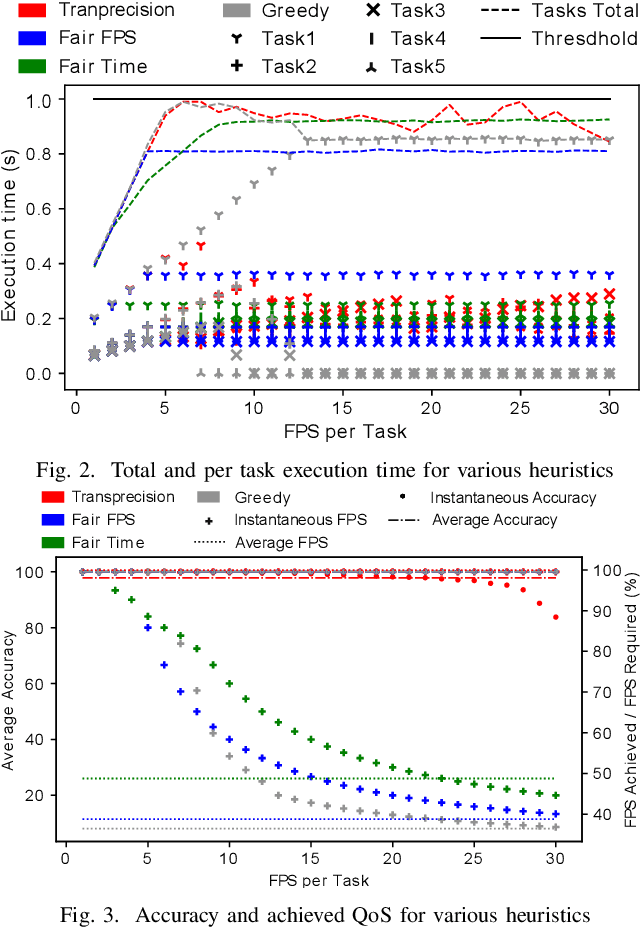
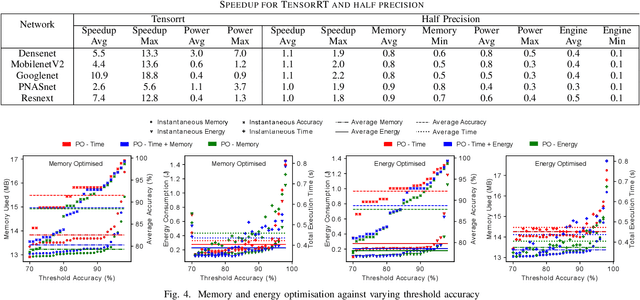
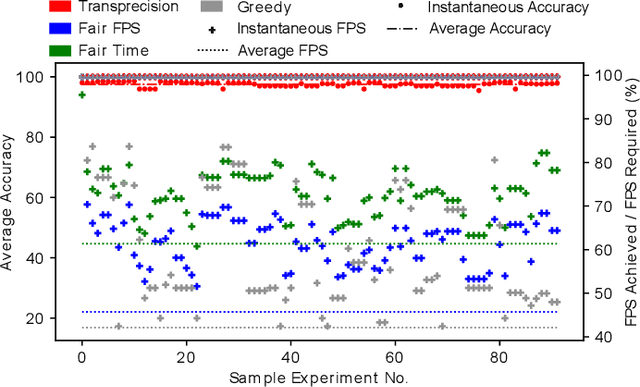
Machine vision tasks present challenges for resource constrained edge devices, particularly as they execute multiple tasks with variable workloads. A robust approach that can dynamically adapt in runtime while maintaining the maximum quality of service (QoS) within resource constraints, is needed. The paper presents a lightweight approach that monitors the runtime workload constraint and leverages accuracy-throughput trade-off. Optimisation techniques are included which find the configurations for each task for optimal accuracy, energy and memory and manages transparent switching between configurations. For an accuracy drop of 1%, we show a 1.6x higher achieved frame processing rate with further improvements possible at lower accuracy.
Understood in Translation, Transformers for Domain Understanding
Dec 18, 2020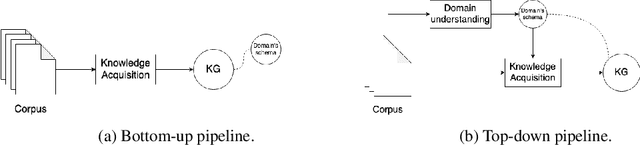


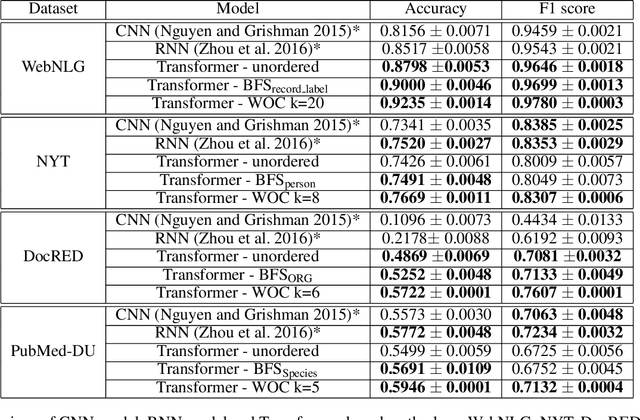
Knowledge acquisition is the essential first step of any Knowledge Graph (KG) application. This knowledge can be extracted from a given corpus (KG generation process) or specified from an existing KG (KG specification process). Focusing on domain specific solutions, knowledge acquisition is a labor intensive task usually orchestrated and supervised by subject matter experts. Specifically, the domain of interest is usually manually defined and then the needed generation or extraction tools are utilized to produce the KG. Herein, we propose a supervised machine learning method, based on Transformers, for domain definition of a corpus. We argue why such automated definition of the domain's structure is beneficial both in terms of construction time and quality of the generated graph. The proposed method is extensively validated on three public datasets (WebNLG, NYT and DocRED) by comparing it with two reference methods based on CNNs and RNNs models. The evaluation shows the efficiency of our model in this task. Focusing on scientific document understanding, we present a new health domain dataset based on publications extracted from PubMed and we successfully utilize our method on this. Lastly, we demonstrate how this work lays the foundation for fully automated and unsupervised KG generation.