 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Time Scheduling Framework for Multi Object Detection via Spiking Neural Networks
Jan 29, 2025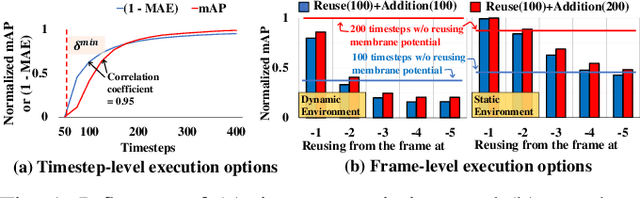
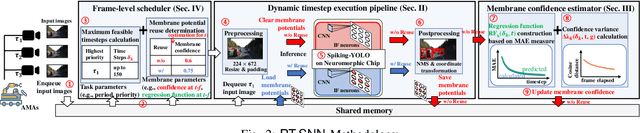

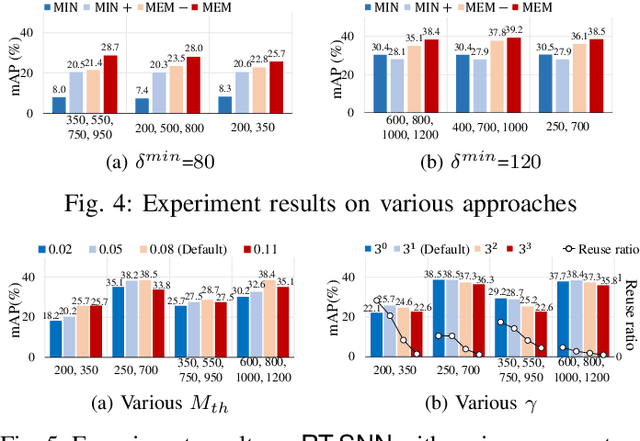
Given the energy constraints in autonomous mobile agents (AMAs), such as unmanned vehicles, spiking neural networks (SNNs) are increasingly favored as a more efficient alternative to traditional artificial neural networks. AMAs employ multi-object detection (MOD) from multiple cameras to identify nearby objects while ensuring two essential objectives, (R1) timing guarantee and (R2) high accuracy for safety. In this paper, we propose RT-SNN, the first system design, aiming at achieving R1 and R2 in SNN-based MOD systems on AMAs. Leveraging the characteristic that SNNs gather feature data of input image termed as membrane potential, through iterative computation over multiple timesteps, RT-SNN provides multiple execution options with adjustable timesteps and a novel method for reusing membrane potential to support R1. Then, it captures how these execution strategies influence R2 by introducing a novel notion of mean absolute error and membrane confidence. Further, RT-SNN develops a new scheduling framework consisting of offline schedulability analysis for R1 and a run-time scheduling algorithm for R2 using the notion of membrane confidence. We deployed RT-SNN to Spiking-YOLO, the SNN-based MOD model derived from ANN-to-SNN conversion, and our experimental evaluation confirms its effectiveness in meeting the R1 and R2 requirements while providing significant energy efficiency.
VFP: Converting Tabular Data for IIoT into Images Considering Correlations of Attributes for Convolutional Neural Networks
Mar 16, 2023For tabular data generated from IIoT devices, traditional machine learning (ML) techniques based on the decision tree algorithm have been employed. However, these methods have limitations in processing tabular data where real number attributes dominate. To address this issue, DeepInsight, REFINED, and IGTD were proposed to convert tabular data into images for utilizing convolutional neural networks (CNNs). They gather similar features in some specific spots of an image to make the converted image look like an actual image. Gathering similar features contrasts with traditional ML techniques for tabular data, which drops some highly correlated attributes to avoid overfitting. Also, previous converting methods fixed the image size, and there are wasted or insufficient pixels according to the number of attributes of tabular data. Therefore, this paper proposes a new converting method, Vortex Feature Positioning (VFP). VFP considers the correlation of features and places similar features far away from each. Features are positioned in the vortex shape from the center of an image, and the number of attributes determines the image size. VFP shows better test performance than traditional ML techniques for tabular data and previous converting methods in five datasets: Iris, Wine, Dry Bean, Epileptic Seizure, and SECOM, which have differences in the number of attributes.
Resource-Efficient Deep Learning: A Survey on Model-, Arithmetic-, and Implementation-Level Techniques
Dec 30, 2021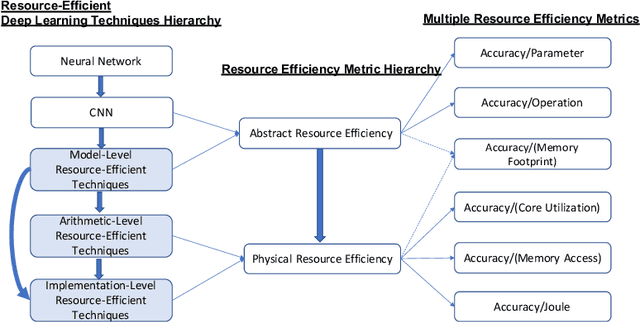
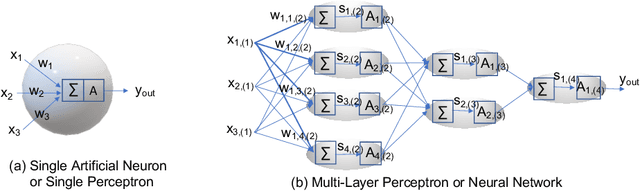
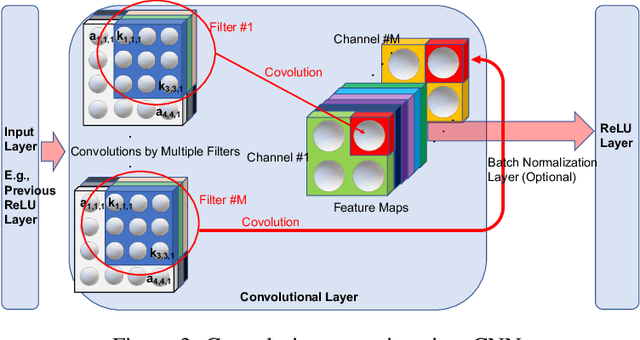
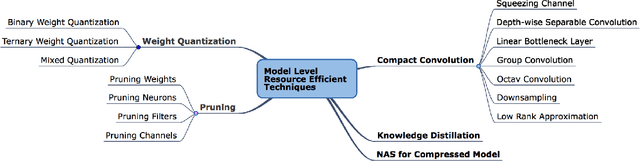
Deep learning is pervasive in our daily life, including self-driving cars, virtual assistants, social network services, healthcare services, face recognition, etc. However, deep neural networks demand substantial compute resources during training and inference. The machine learning community has mainly focused on model-level optimizations such as architectural compression of deep learning models, while the system community has focused on implementation-level optimization. In between, various arithmetic-level optimization techniques have been proposed in the arithmetic community. This article provides a survey on resource-efficient deep learning techniques in terms of model-, arithmetic-, and implementation-level techniques and identifies the research gaps for resource-efficient deep learning techniques across the three different level techniques. Our survey clarifies the influence from higher to lower-level techniques based on our resource-efficiency metric definition and discusses the future trend for resource-efficient deep learning research.
ScissionLite: Accelerating Distributed Deep Neural Networks Using Transfer Layer
May 05, 2021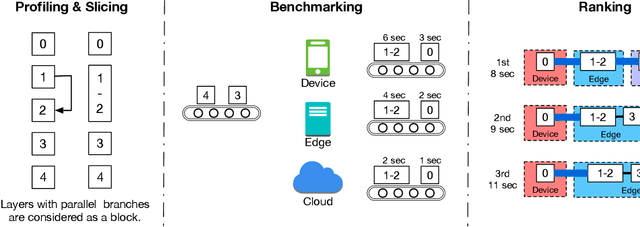
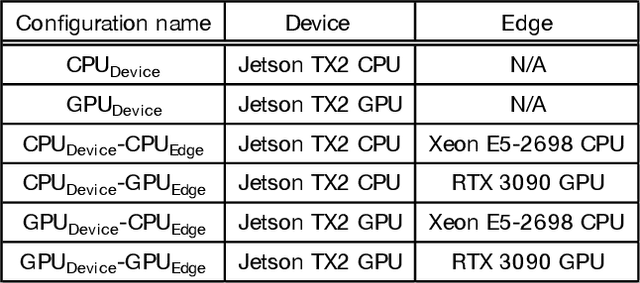
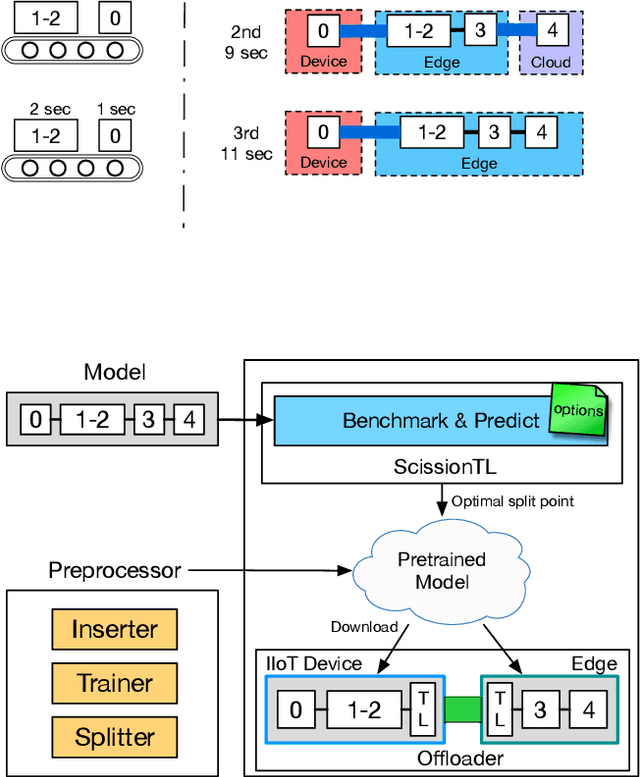

Industrial Internet of Things (IIoT) applications can benefit from leveraging edge computing. For example, applications underpinned by deep neural networks (DNN) models can be sliced and distributed across the IIoT device and the edge of the network for improving the overall performance of inference and for enhancing privacy of the input data, such as industrial product images. However, low network performance between IIoT devices and the edge is often a bottleneck. In this study, we develop ScissionLite, a holistic framework for accelerating distributed DNN inference using the Transfer Layer (TL). The TL is a traffic-aware layer inserted between the optimal slicing point of a DNN model slice in order to decrease the outbound network traffic without a significant accuracy drop. For the TL, we implement a new lightweight down/upsampling network for performance-limited IIoT devices. In ScissionLite, we develop ScissionTL, the Preprocessor, and the Offloader for end-to-end activities for deploying DNN slices with the TL. They decide the optimal slicing point of the DNN, prepare pre-trained DNN slices including the TL, and execute the DNN slices on an IIoT device and the edge. Employing the TL for the sliced DNN models has a negligible overhead. ScissionLite improves the inference latency by up to 16 and 2.8 times when compared to execution on the local device and an existing state-of-the-art model slicing approach respectively.