 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Predictability of Multi-Tenant DNN Inference for Autonomous Vehicles' Perception
Feb 11, 2026Autonomous vehicles (AVs) rely on sensors and deep neural networks (DNNs) to perceive their surrounding environment and make maneuver decisions in real time. However, achieving real-time DNN inference in the AV's perception pipeline is challenging due to the large gap between the computation requirement and the AV's limited resources. Most, if not all, of existing studies focus on optimizing the DNN inference time to achieve faster perception by compressing the DNN model with pruning and quantization. In contrast, we present a Predictable Perception system with DNNs (PP-DNN) that reduce the amount of image data to be processed while maintaining the same level of accuracy for multi-tenant DNNs by dynamically selecting critical frames and regions of interest (ROIs). PP-DNN is based on our key insight that critical frames and ROIs for AVs vary with the AV's surrounding environment. However, it is challenging to identify and use critical frames and ROIs in multi-tenant DNNs for predictable inference. Given image-frame streams, PP-DNN leverages an ROI generator to identify critical frames and ROIs based on the similarities of consecutive frames and traffic scenarios. PP-DNN then leverages a FLOPs predictor to predict multiply-accumulate operations (MACs) from the dynamic critical frames and ROIs. The ROI scheduler coordinates the processing of critical frames and ROIs with multiple DNN models. Finally, we design a detection predictor for the perception of non-critical frames. We have implemented PP-DNN in an ROS-based AV pipeline and evaluated it with the BDD100K and the nuScenes dataset. PP-DNN is observed to significantly enhance perception predictability, increasing the number of fusion frames by up to 7.3x, reducing the fusion delay by >2.6x and fusion-delay variations by >2.3x, improving detection completeness by 75.4% and the cost-effectiveness by up to 98% over the baseline.
CF-DETR: Coarse-to-Fine Transformer for Real-Time Object Detection
May 29, 2025Detection Transformers (DETR) are increasingly adopted in autonomous vehicle (AV) perception systems due to their superior accuracy over convolutional networks. However, concurrently executing multiple DETR tasks presents significant challenges in meeting firm real-time deadlines (R1) and high accuracy requirements (R2), particularly for safety-critical objects, while navigating the inherent latency-accuracy trade-off under resource constraints. Existing real-time DNN scheduling approaches often treat models generically, failing to leverage Transformer-specific properties for efficient resource allocation. To address these challenges, we propose CF-DETR, an integrated system featuring a novel coarse-to-fine Transformer architecture and a dedicated real-time scheduling framework NPFP**. CF-DETR employs three key strategies (A1: coarse-to-fine inference, A2: selective fine inference, A3: multi-level batch inference) that exploit Transformer properties to dynamically adjust patch granularity and attention scope based on object criticality, aiming to satisfy R2. The NPFP** scheduling framework (A4) orchestrates these adaptive mechanisms A1-A3. It partitions each DETR task into a safety-critical coarse subtask for guaranteed critical object detection within its deadline (ensuring R1), and an optional fine subtask for enhanced overall accuracy (R2), while managing individual and batched execution. Our extensive evaluations on server, GPU-enabled embedded platforms, and actual AV platforms demonstrate that CF-DETR, under an NPFP** policy, successfully meets strict timing guarantees for critical operations and achieves significantly higher overall and critical object detection accuracy compared to existing baselines across diverse AV workloads.
Real Time Scheduling Framework for Multi Object Detection via Spiking Neural Networks
Jan 29, 2025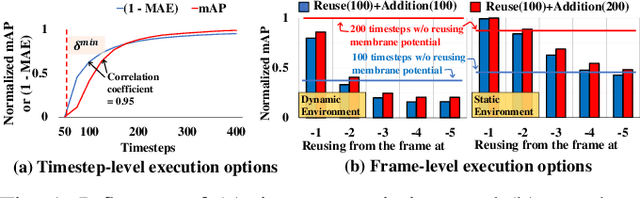
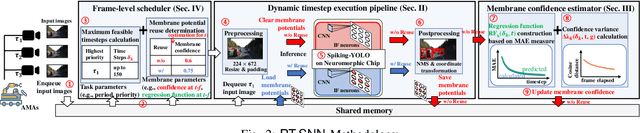

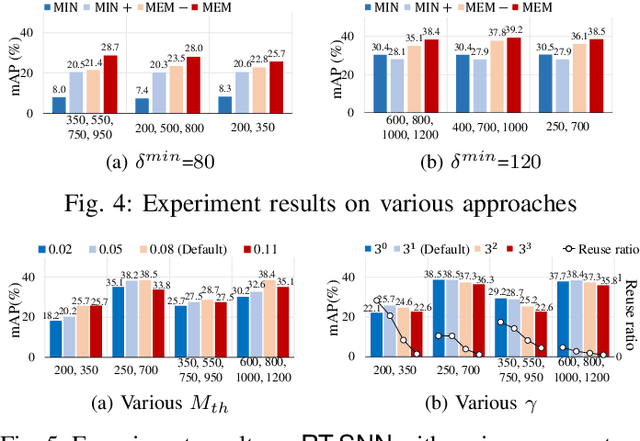
Given the energy constraints in autonomous mobile agents (AMAs), such as unmanned vehicles, spiking neural networks (SNNs) are increasingly favored as a more efficient alternative to traditional artificial neural networks. AMAs employ multi-object detection (MOD) from multiple cameras to identify nearby objects while ensuring two essential objectives, (R1) timing guarantee and (R2) high accuracy for safety. In this paper, we propose RT-SNN, the first system design, aiming at achieving R1 and R2 in SNN-based MOD systems on AMAs. Leveraging the characteristic that SNNs gather feature data of input image termed as membrane potential, through iterative computation over multiple timesteps, RT-SNN provides multiple execution options with adjustable timesteps and a novel method for reusing membrane potential to support R1. Then, it captures how these execution strategies influence R2 by introducing a novel notion of mean absolute error and membrane confidence. Further, RT-SNN develops a new scheduling framework consisting of offline schedulability analysis for R1 and a run-time scheduling algorithm for R2 using the notion of membrane confidence. We deployed RT-SNN to Spiking-YOLO, the SNN-based MOD model derived from ANN-to-SNN conversion, and our experimental evaluation confirms its effectiveness in meeting the R1 and R2 requirements while providing significant energy efficiency.
AT-SNN: Adaptive Tokens for Vision Transformer on Spiking Neural Network
Aug 22, 2024



In the training and inference of spiking neural networks (SNNs), direct training and lightweight computation methods have been orthogonally developed, aimed at reducing power consumption. However, only a limited number of approaches have applied these two mechanisms simultaneously and failed to fully leverage the advantages of SNN-based vision transformers (ViTs) since they were originally designed for convolutional neural networks (CNNs). In this paper, we propose AT-SNN designed to dynamically adjust the number of tokens processed during inference in SNN-based ViTs with direct training, wherein power consumption is proportional to the number of tokens. We first demonstrate the applicability of adaptive computation time (ACT), previously limited to RNNs and ViTs, to SNN-based ViTs, enhancing it to discard less informative spatial tokens selectively. Also, we propose a new token-merge mechanism that relies on the similarity of tokens, which further reduces the number of tokens while enhancing accuracy. We implement AT-SNN to Spikformer and show the effectiveness of AT-SNN in achieving high energy efficiency and accuracy compared to state-of-the-art approaches on the image classification tasks, CIFAR10, CIFAR-100, and TinyImageNet. For example, our approach uses up to 42.4% fewer tokens than the existing best-performing method on CIFAR-100, while conserving higher accuracy.
BankTweak: Adversarial Attack against Multi-Object Trackers by Manipulating Feature Banks
Aug 22, 2024



Multi-object tracking (MOT) aims to construct moving trajectories for objects, and modern multi-object trackers mainly utilize the tracking-by-detection methodology. Initial approaches to MOT attacks primarily aimed to degrade the detection quality of the frames under attack, thereby reducing accuracy only in those specific frames, highlighting a lack of \textit{efficiency}. To improve efficiency, recent advancements manipulate object positions to cause persistent identity (ID) switches during the association phase, even after the attack ends within a few frames. However, these position-manipulating attacks have inherent limitations, as they can be easily counteracted by adjusting distance-related parameters in the association phase, revealing a lack of \textit{robustness}. In this paper, we present \textsf{BankTweak}, a novel adversarial attack designed for MOT trackers, which features efficiency and robustness. \textsf{BankTweak} focuses on the feature extractor in the association phase and reveals vulnerability in the Hungarian matching method used by feature-based MOT systems. Exploiting the vulnerability, \textsf{BankTweak} induces persistent ID switches (addressing \textit{efficiency}) even after the attack ends by strategically injecting altered features into the feature banks without modifying object positions (addressing \textit{robustness}). To demonstrate the applicability, we apply \textsf{BankTweak} to three multi-object trackers (DeepSORT, StrongSORT, and MOTDT) with one-stage, two-stage, anchor-free, and transformer detectors. Extensive experiments on the MOT17 and MOT20 datasets show that our method substantially surpasses existing attacks, exposing the vulnerability of the tracking-by-detection framework to \textsf{BankTweak}.
Knowledge Distillation from Non-streaming to Streaming ASR Encoder using Auxiliary Non-streaming Layer
Aug 31, 2023Streaming automatic speech recognition (ASR) models are restricted from accessing future context, which results in worse performance compared to the non-streaming models. To improve the performance of streaming ASR, knowledge distillation (KD) from the non-streaming to streaming model has been studied, mainly focusing on aligning the output token probabilities. In this paper, we propose a layer-to-layer KD from the teacher encoder to the student encoder. To ensure that features are extracted using the same context, we insert auxiliary non-streaming branches to the student and perform KD from the non-streaming teacher layer to the non-streaming auxiliary layer. We design a special KD loss that leverages the autoregressive predictive coding (APC) mechanism to encourage the streaming model to predict unseen future contexts. Experimental results show that the proposed method can significantly reduce the word error rate compared to previous token probability distillation methods.
End-to-End Driving via Self-Supervised Imitation Learning Using Camera and LiDAR Data
Aug 28, 2023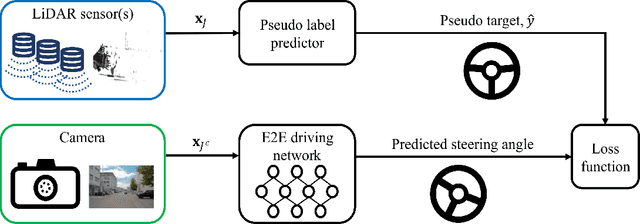
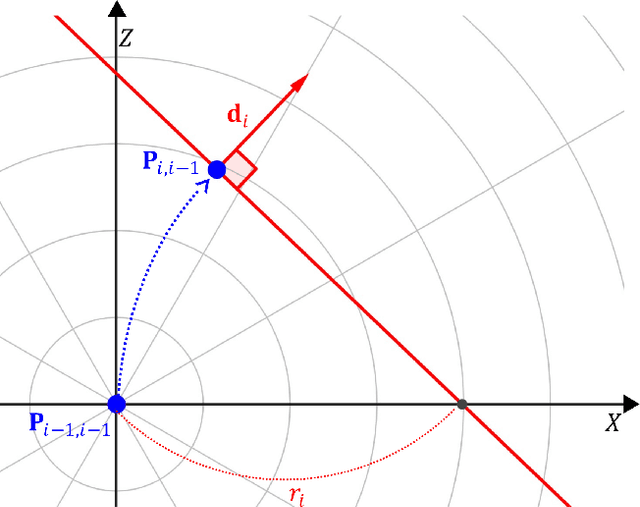
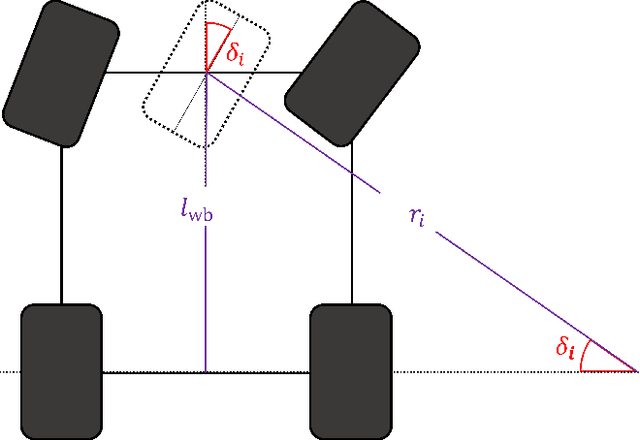
In autonomous driving, the end-to-end (E2E) driving approach that predicts vehicle control signals directly from sensor data is rapidly gaining attention. To learn a safe E2E driving system, one needs an extensive amount of driving data and human intervention. Vehicle control data is constructed by many hours of human driving, and it is challenging to construct large vehicle control datasets. Often, publicly available driving datasets are collected with limited driving scenes, and collecting vehicle control data is only available by vehicle manufacturers. To address these challenges, this paper proposes the first self-supervised learning framework, self-supervised imitation learning (SSIL), that can learn E2E driving networks without using driving command data. To construct pseudo steering angle data, proposed SSIL predicts a pseudo target from the vehicle's poses at the current and previous time points that are estimated with light detection and ranging sensors. Our numerical experiments demonstrate that the proposed SSIL framework achieves comparable E2E driving accuracy with the supervised learning counterpart. In addition, our qualitative analyses using a conventional visual explanation tool show that trained NNs by proposed SSIL and the supervision counterpart attend similar objects in making predictions.
Broadcasted Residual Learning for Efficient Keyword Spotting
Jun 30, 2021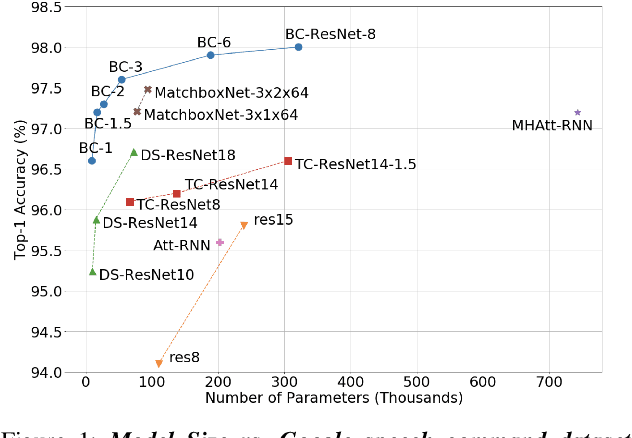
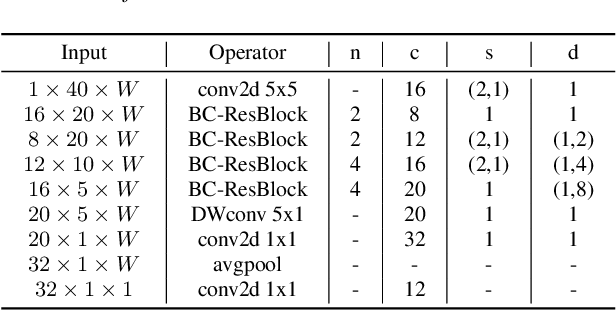
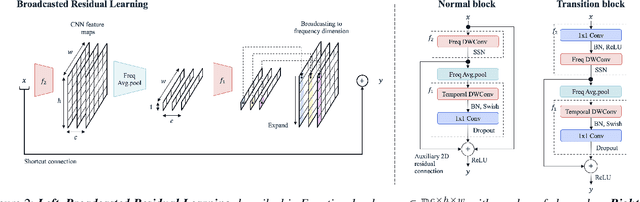
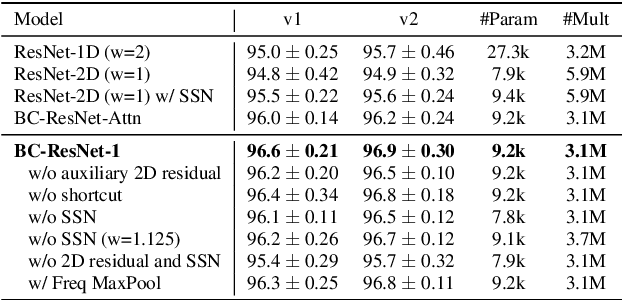
Keyword spotting is an important research field because it plays a key role in device wake-up and user interaction on smart devices. However, it is challenging to minimize errors while operating efficiently in devices with limited resources such as mobile phones. We present a broadcasted residual learning method to achieve high accuracy with small model size and computational load. Our method configures most of the residual functions as 1D temporal convolution while still allows 2D convolution together using a broadcasted-residual connection that expands temporal output to frequency-temporal dimension. This residual mapping enables the network to effectively represent useful audio features with much less computation than conventional convolutional neural networks. We also propose a novel network architecture, Broadcasting-residual network (BC-ResNet), based on broadcasted residual learning and describe how to scale up the model according to the target device's resources. BC-ResNets achieve state-of-the-art 98.0% and 98.7% top-1 accuracy on Google speech command datasets v1 and v2, respectively, and consistently outperform previous approaches, using fewer computations and parameters.
Improved Real-Time Monocular SLAM Using Semantic Segmentation on Selective Frames
Apr 30, 2021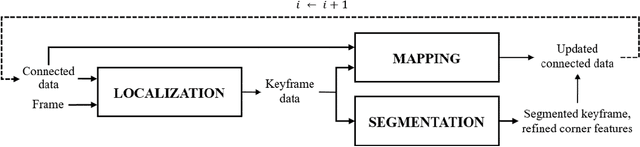
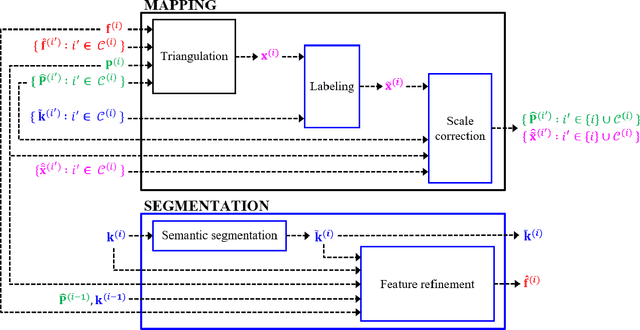
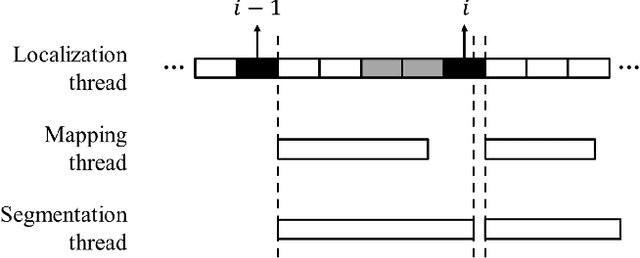
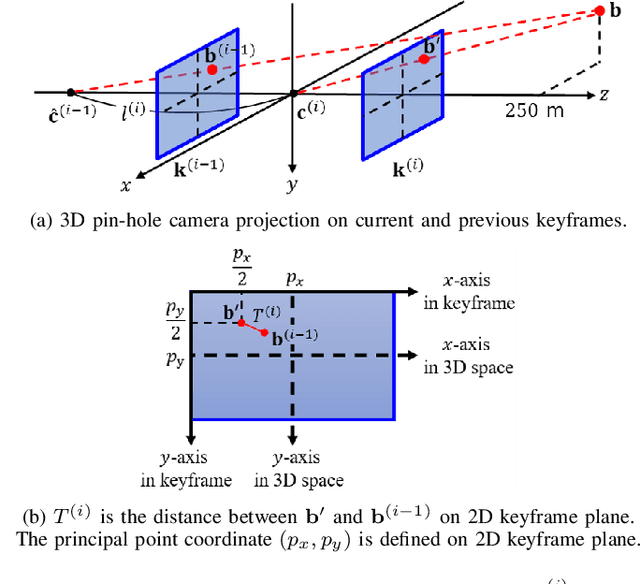
Monocular simultaneous localization and mapping (SLAM) is emerging in advanced driver assistance systems and autonomous driving, because a single camera is cheap and easy to install. Conventional monocular SLAM has two major challenges leading inaccurate localization and mapping. First, it is challenging to estimate scales in localization and mapping. Second, conventional monocular SLAM uses inappropriate mapping factors such as dynamic objects and low-parallax ares in mapping. This paper proposes an improved real-time monocular SLAM that resolves the aforementioned challenges by efficiently using deep learning-based semantic segmentation. To achieve the real-time execution of the proposed method, we apply semantic segmentation only to downsampled keyframes in parallel with mapping processes. In addition, the proposed method corrects scales of camera poses and three-dimensional (3D) points, using estimated ground plane from road-labeled 3D points and the real camera height. The proposed method also removes inappropriate corner features labeled as moving objects and low parallax areas. Experiments with six video sequences demonstrate that the proposed monocular SLAM system achieves significantly more accurate trajectory tracking accuracy compared to state-of-the-art monocular SLAM and comparable trajectory tracking accuracy compared to state-of-the-art stereo SLAM.
Improved and efficient inter-vehicle distance estimation using road gradients of both ego and target vehicles
Apr 01, 2021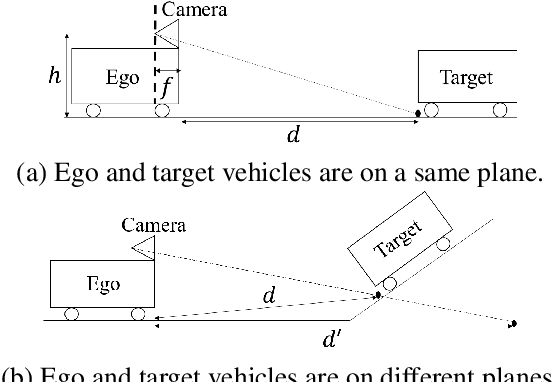
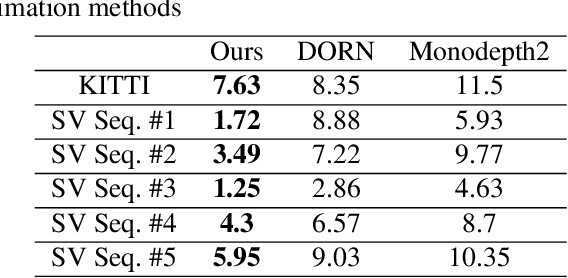
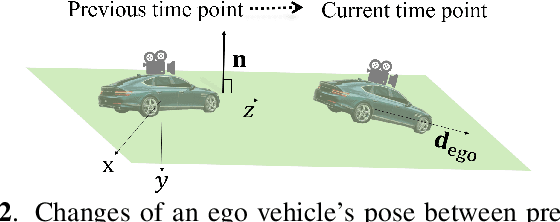

In advanced driver assistant systems and autonomous driving, it is crucial to estimate distances between an ego vehicle and target vehicles. Existing inter-vehicle distance estimation methods assume that the ego and target vehicles drive on a same ground plane. In practical driving environments, however, they may drive on different ground planes. This paper proposes an inter-vehicle distance estimation framework that can consider slope changes of a road forward, by estimating road gradients of \emph{both} ego vehicle and target vehicles and using a 2D object detection deep net. Numerical experiments demonstrate that the proposed method significantly improves the distance estimation accuracy and time complexity, compared to deep learning-based depth estimation methods.