 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Radiance Field using Near-Surface Sampling with Point Cloud Generation
Oct 06, 2023Neural radiance field (NeRF) is an emerging view synthesis method that samples points in a three-dimensional (3D) space and estimates their existence and color probabilities. The disadvantage of NeRF is that it requires a long training time since it samples many 3D points. In addition, if one samples points from occluded regions or in the space where an object is unlikely to exist, the rendering quality of NeRF can be degraded. These issues can be solved by estimating the geometry of 3D scene. This paper proposes a near-surface sampling framework to improve the rendering quality of NeRF. To this end, the proposed method estimates the surface of a 3D object using depth images of the training set and sampling is performed around there only. To obtain depth information on a novel view, the paper proposes a 3D point cloud generation method and a simple refining method for projected depth from a point cloud. Experimental results show that the proposed near-surface sampling NeRF framework can significantly improve the rendering quality, compared to the original NeRF and a state-of-the-art depth-based NeRF method. In addition, one can significantly accelerate the training time of a NeRF model with the proposed near-surface sampling framework.
End-to-End Driving via Self-Supervised Imitation Learning Using Camera and LiDAR Data
Aug 28, 2023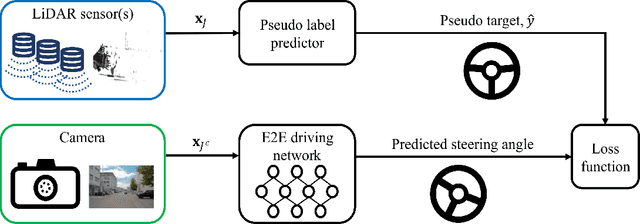
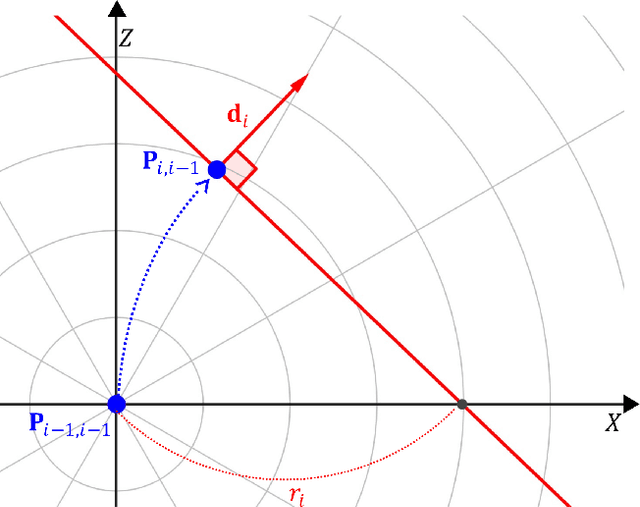
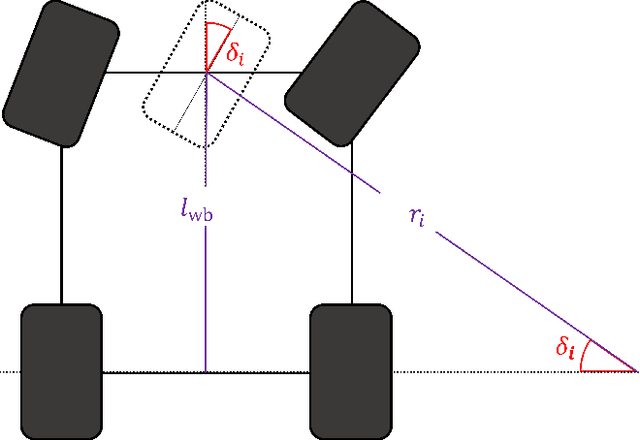
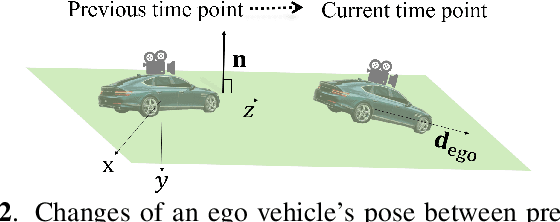
In autonomous driving, the end-to-end (E2E) driving approach that predicts vehicle control signals directly from sensor data is rapidly gaining attention. To learn a safe E2E driving system, one needs an extensive amount of driving data and human intervention. Vehicle control data is constructed by many hours of human driving, and it is challenging to construct large vehicle control datasets. Often, publicly available driving datasets are collected with limited driving scenes, and collecting vehicle control data is only available by vehicle manufacturers. To address these challenges, this paper proposes the first self-supervised learning framework, self-supervised imitation learning (SSIL), that can learn E2E driving networks without using driving command data. To construct pseudo steering angle data, proposed SSIL predicts a pseudo target from the vehicle's poses at the current and previous time points that are estimated with light detection and ranging sensors. Our numerical experiments demonstrate that the proposed SSIL framework achieves comparable E2E driving accuracy with the supervised learning counterpart. In addition, our qualitative analyses using a conventional visual explanation tool show that trained NNs by proposed SSIL and the supervision counterpart attend similar objects in making predictions.
Improved Real-Time Monocular SLAM Using Semantic Segmentation on Selective Frames
Apr 30, 2021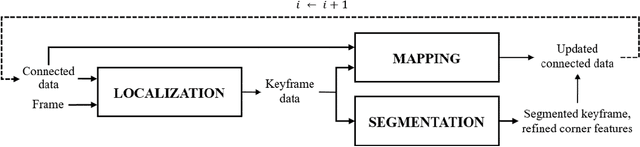
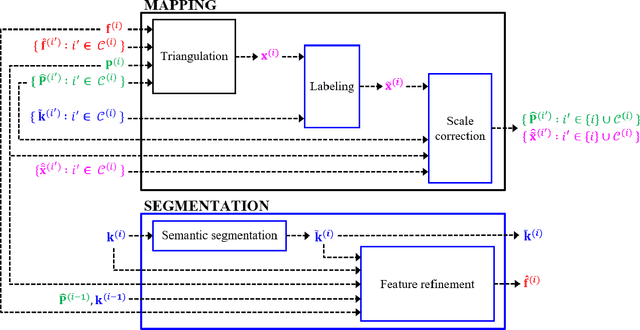
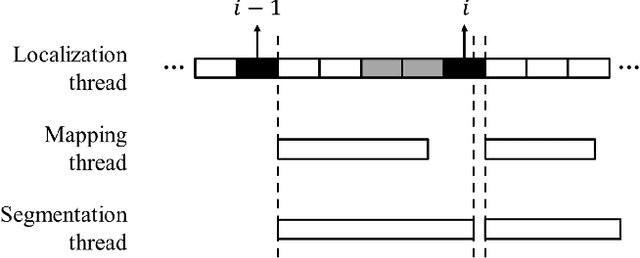
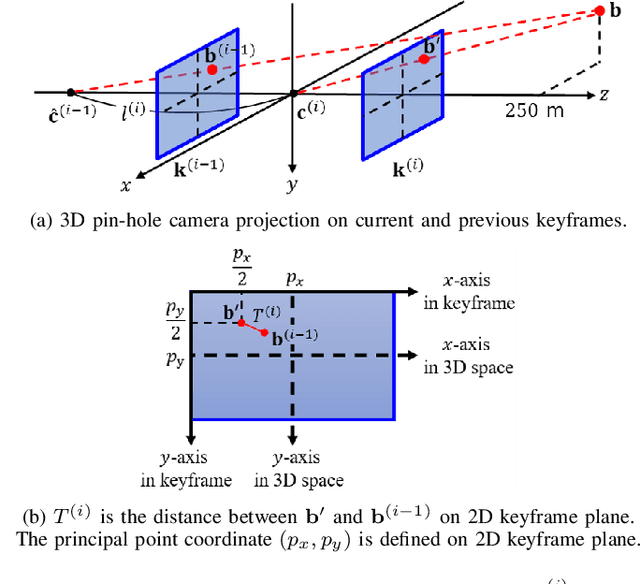
Monocular simultaneous localization and mapping (SLAM) is emerging in advanced driver assistance systems and autonomous driving, because a single camera is cheap and easy to install. Conventional monocular SLAM has two major challenges leading inaccurate localization and mapping. First, it is challenging to estimate scales in localization and mapping. Second, conventional monocular SLAM uses inappropriate mapping factors such as dynamic objects and low-parallax ares in mapping. This paper proposes an improved real-time monocular SLAM that resolves the aforementioned challenges by efficiently using deep learning-based semantic segmentation. To achieve the real-time execution of the proposed method, we apply semantic segmentation only to downsampled keyframes in parallel with mapping processes. In addition, the proposed method corrects scales of camera poses and three-dimensional (3D) points, using estimated ground plane from road-labeled 3D points and the real camera height. The proposed method also removes inappropriate corner features labeled as moving objects and low parallax areas. Experiments with six video sequences demonstrate that the proposed monocular SLAM system achieves significantly more accurate trajectory tracking accuracy compared to state-of-the-art monocular SLAM and comparable trajectory tracking accuracy compared to state-of-the-art stereo SLAM.
Fisheye Lens Camera based Autonomous Valet Parking System
Apr 27, 2021



This paper proposes an efficient autonomous valet parking system utilizing only cameras which are the most widely used sensor. To capture more information instantaneously and respond rapidly to changes in the surrounding environment, fisheye cameras which have a wider angle of view compared to pinhole cameras are used. Accordingly, visual simultaneous localization and mapping is used to identify the layout of the parking lot and track the location of the vehicle. In addition, the input image frames are converted into around view monitor images to resolve the distortion of fisheye lens because the algorithm to detect edges are supposed to be applied to images taken with pinhole cameras. The proposed system adopts a look up table for real time operation by minimizing the computational complexity encountered when processing AVM images. The detection rate of each process and the success rate of autonomous parking were measured to evaluate performance. The experimental results confirm that autonomous parking can be achieved using only visual sensors.
Improved and efficient inter-vehicle distance estimation using road gradients of both ego and target vehicles
Apr 01, 2021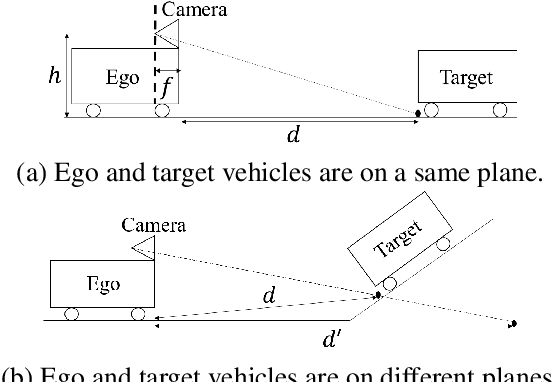
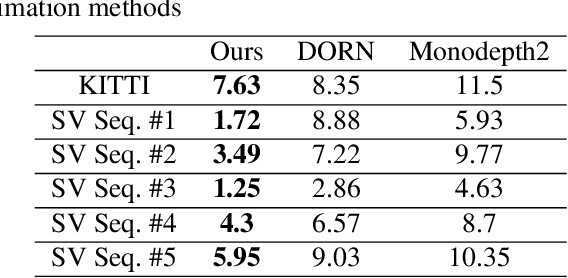

In advanced driver assistant systems and autonomous driving, it is crucial to estimate distances between an ego vehicle and target vehicles. Existing inter-vehicle distance estimation methods assume that the ego and target vehicles drive on a same ground plane. In practical driving environments, however, they may drive on different ground planes. This paper proposes an inter-vehicle distance estimation framework that can consider slope changes of a road forward, by estimating road gradients of \emph{both} ego vehicle and target vehicles and using a 2D object detection deep net. Numerical experiments demonstrate that the proposed method significantly improves the distance estimation accuracy and time complexity, compared to deep learning-based depth estimation methods.